

En Resumen: lo imprescindible
Claude Sonnet 4.6 consolida al “agente generalista” asequible: nueva versión de gama media de Anthropic que se acerca al nivel de Opus en razonamiento, coding y uso de herramientas, con contexto de hasta 1M tokens en beta y foco explícito en robustez frente a contenido web adversarial.
Gemini 3.1 Pro y el stack agentico multimodal de Google: Gemini 3.1 Pro dobla rendimiento en reasoning (ARC‑AGI‑2, etc.) y se despliega en todo el ecosistema Google (Gemini app, NotebookLM, Vertex AI, CLI, Android Studio), mientras Lyria 3 y otros modelos añaden música y medios generativos al asistente.
Empresas y sector público empiezan a reorganizarse alrededor de agentes: alianzas como Anthropic+Infosys, la expansión en India y el MOU con Ruanda, junto con startups como Kana y Reload y casos como OpenClaw+rentahuman, muestran a agentes de código y de negocio pasando de demo a infraestructura cotidiana.
La infraestructura y el capital se mueven a escala frontier: la megarronda de >100B$ de OpenAI, el acuerdo de 100MW→1GW con Tata y el Frontier AI Grand Challenge europeo señalan una carrera por modelos frontier propios, mientras el rally de Raspberry Pi y proyectos como PicoClaw apuntan a una capa complementaria de agentes en hardware barato y dedicado.
Oleada de modelos pensados para agentes, multimodales y encarnados: desde Qwen3.5‑397B‑A17B y JoyAI‑LLM‑Flash (MoE para reasoning, tools y coding) hasta PicoClaw (assistant en 10$ HW), Capybara (creación visual unificada), MOSS‑TTS (voz de producción) y RynnBrain (foundation model encarnado), el ecosistema de modelos se especializa en capacidades agenticas muy concretas.
Nuevos marcos para agentes de horizonte largo, uso del ordenador y delegación: trabajos como KLong, IntentCUA, RynnBrain e Intelligent AI Delegation exploran cómo entrenar agentes para tareas largas, uso robusto del escritorio y redes de delegación entre humanos y múltiples agentes.
Seguridad y tooling para builders se afinan en el mundo agentico: Phantom y GAP muestran nuevas superficies de ataque (plantillas estructurales, brecha texto/tools), Web Verbs propone verbos tipados para la web, y utilidades como EVMbench, Storm MCP Apps, Aguara, MicroGPT Playground, CuPy v14 o Unsloth+VS Code refuerzan evaluación, seguridad y productividad para quienes construyen agentes.
Noticias Recientes
Anthropic
Claude Sonnet 4.6 y la consolidación del “agente generalista” asequible
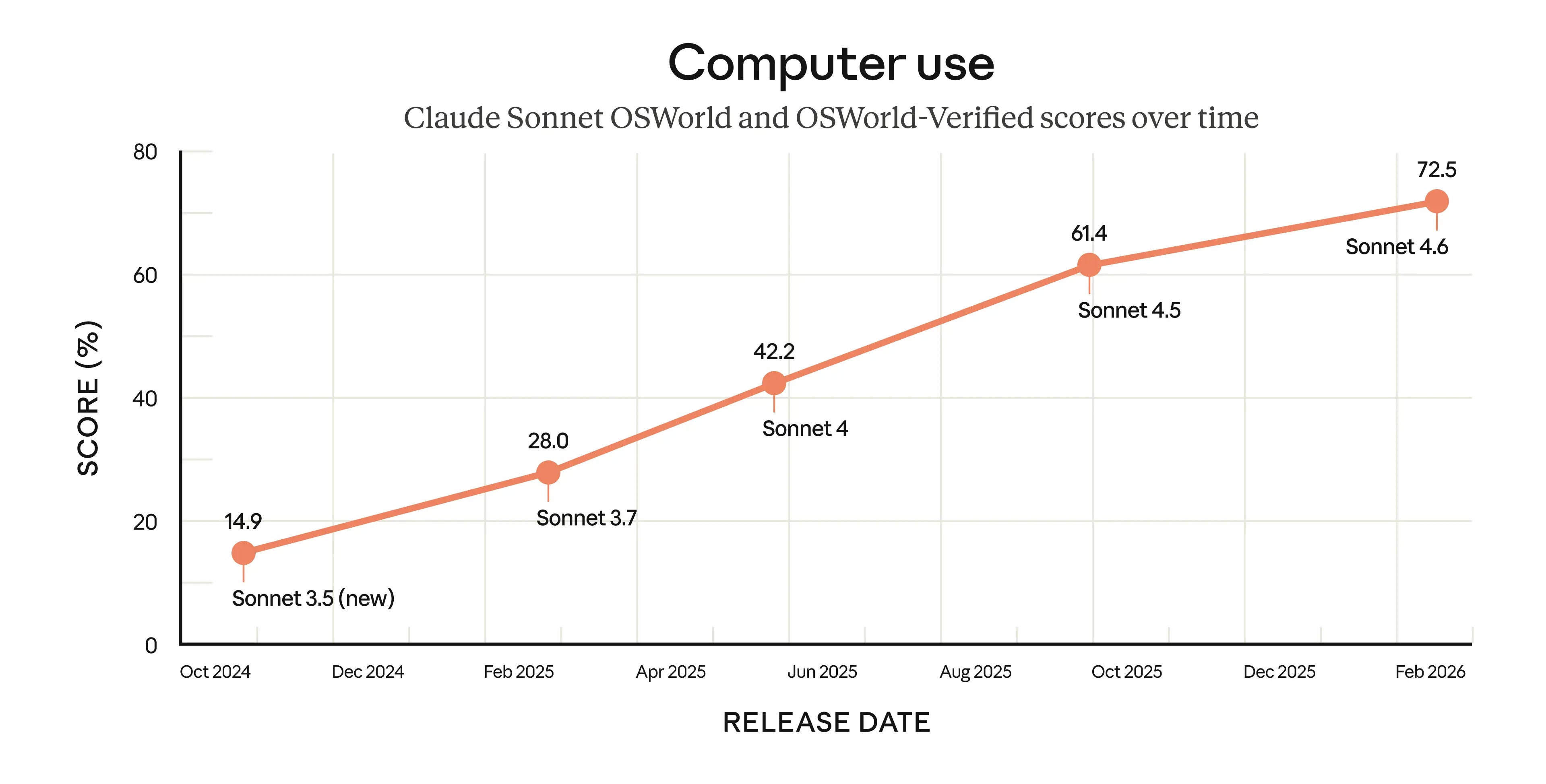
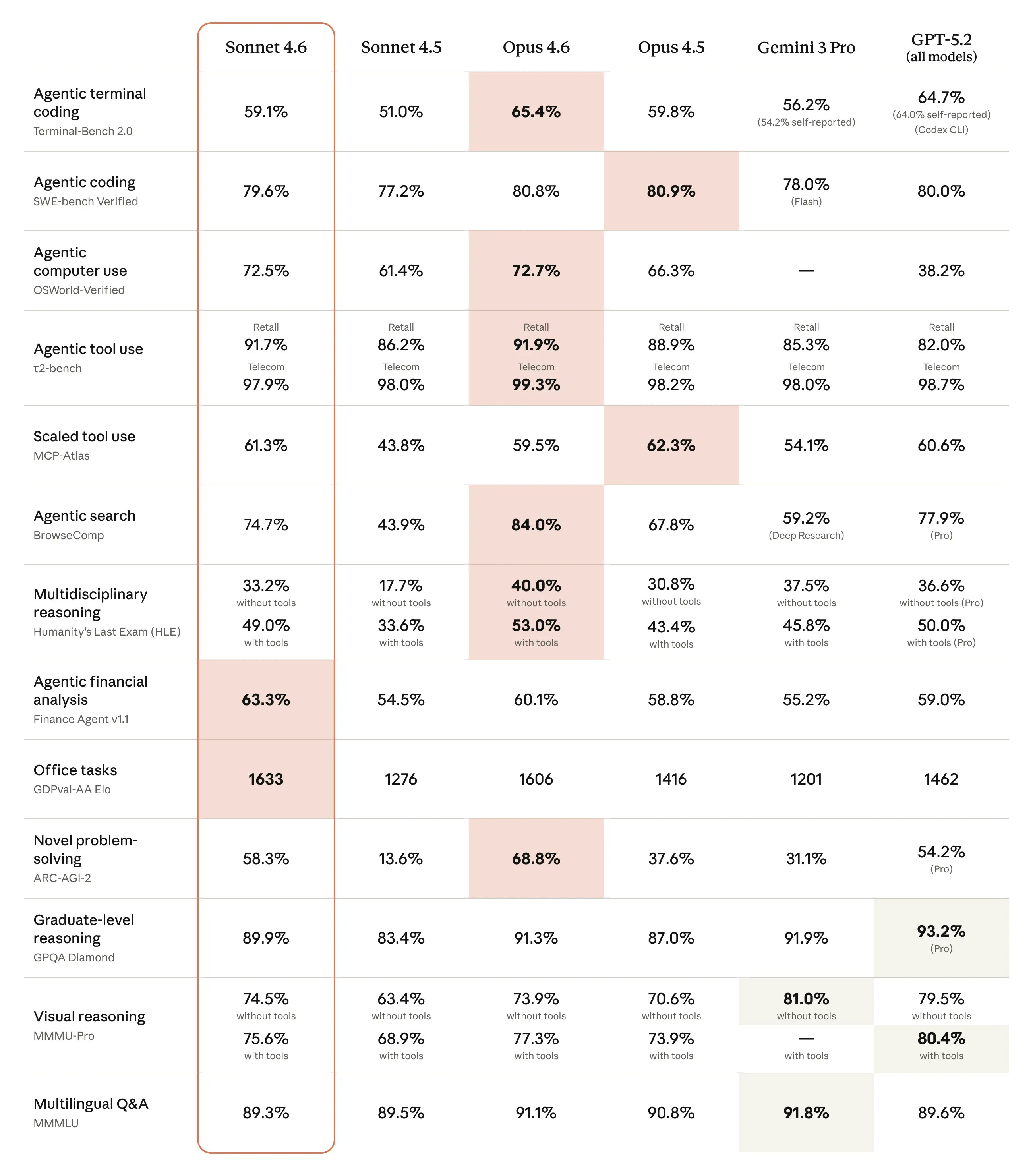
Anthropic ha lanzado Claude Sonnet 4.6, una actualización importante de su línea Sonnet (la gama media entre Haiku y Opus) centrada en razonamiento profundo, coding, uso del ordenador y contexto largo.
En sus propios datos y en los de clientes early adopters, Sonnet 4.6 se acerca al rendimiento de Opus en muchas tareas exigentes (razonamiento, planificación multi‑paso, diseño, refactors complejos) con costes significativamente menores, lo que lo hace especialmente atractivo para workloads agenticos a gran escala: pipelines de refactorización, análisis masivo de documentación, agentes de negocio que viven en aplicaciones empresariales, etc.
Además de empujar el contexto hasta 1M tokens en beta, Anthropic destaca mejoras en robustez frente a contenido adversarial (prompt injection vía web, documentos maliciosos) y la ampliación del soporte de herramientas (búsqueda web, fetch, ejecución de código, memoria y tool calling programático). En la práctica, Sonnet 4.6 se posiciona como un caballo de batalla para agentes de producción que necesitan equilibrio entre capacidad, precio y seguridad.
Fuente: [clic aquí]
Colaboración con Infosys: agentes para telecom, finanzas y sectores regulados
Anthropic ha anunciado una colaboración estratégica con Infosys para construir agentes basados en Claude que automaticen tareas multi‑paso en telecomunicaciones, servicios financieros, manufactura y desarrollo software.
La idea es combinar los modelos Claude/Claude Code con la plataforma Infosys Topaz para atacar problemas típicos de sistemas heredados: procesos manuales, integraciones frágiles y flujos de negocio llenos de back‑and‑forth humano. Los agentes que plantean son persistentes, con capacidad para manejar casos largos como procesamiento de siniestros, reporting regulatorio o modernización progresiva de aplicaciones.
Más allá del anuncio comercial, esta alianza es relevante porque muestra cómo empresas grandes y muy reguladas empiezan a apostar por agentes verticales con fuerte gobernanza y trazabilidad, en lugar de simples chatbots de atención.
Fuente: [clic aquí]
Oficina de Anthropic en Bengaluru y ecosistema agentico en India
En paralelo, Anthropic ha anunciado la apertura de una oficina en Bengaluru y una serie de nuevas alianzas en India, uno de sus mercados con usuarios más técnicos y uso intensivo de Claude.
El comunicado destaca a empresas como Air India, CRED, Cognizant, Razorpay o Emergent, que ya están usando Claude Code y agentes basados en Claude para modernizar sistemas heredados, acelerar ciclos de entrega y construir constructores low‑code/no‑code apoyados en agentes.
También es interesante el foco en estándares de contexto como Model Context Protocol (MCP): se mencionan los primeros servidores MCP gubernamentales en India, que permiten a agentes acceder con seguridad a datos oficiales con contratos claros. Esto apunta a un futuro donde interactuar con la administración sea, en gran medida, tarea de agentes que hablan MCP.
Fuente: [clic aquí]
Anthropic y el Gobierno de Ruanda. IA para salud y educación públicas
Anthropic también ha firmado un memorando de entendimiento de tres años con el Gobierno de Ruanda para desplegar IA en salud, educación y administración pública.
El acuerdo incluye el uso de Claude y Claude Code por parte de desarrolladores gubernamentales, personal sanitario y de educación, junto con formación, créditos de API y trabajo en capacidades locales para que el país pueda usar estas herramientas de forma independiente y segura.
Desde la perspectiva agentica, es un caso interesante de integración de agentes y copilotos en servicios públicos del Sur Global, con énfasis en despliegues reales (no demo), autonomía local y construcción de capacidad institucional a largo plazo.
Fuente: [clic aquí]
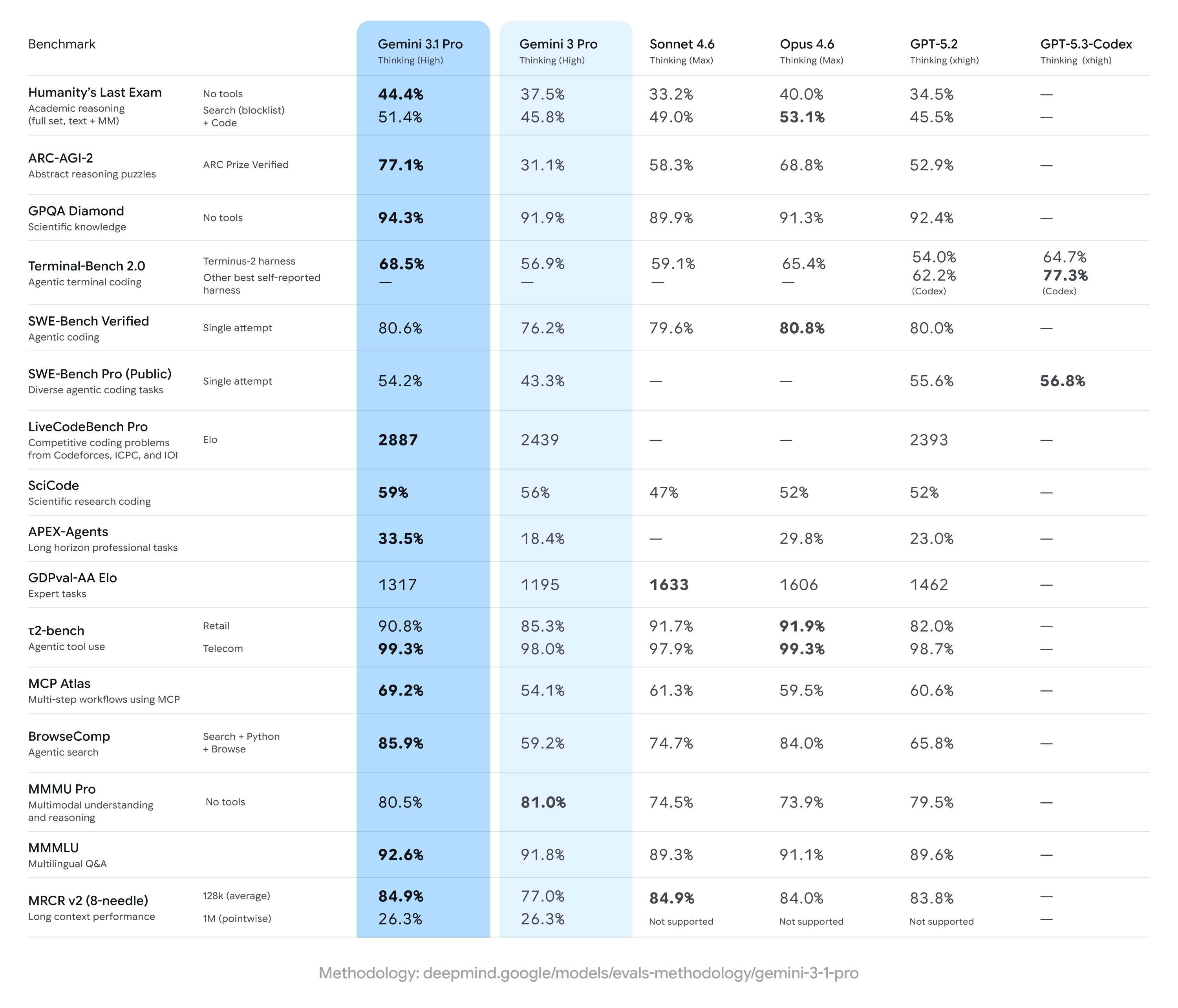
Gemini 3.1 Pro y el stack agéntico de Google
Google ha presentado Gemini 3.1 Pro, una actualización de su modelo Pro pensada para tareas complejas de razonamiento y workflows largos. En benchmarks como ARC‑AGI‑2 hablan de una mejora sustancial (hasta un 77,1 % verificado, más del doble que Gemini 3 Pro), lo que sitúa a 3.1 Pro como modelo generalista fuerte para planificación y análisis profundo.
Lo más relevante para agentes no es sólo el score, sino el despliegue transversal:
Disponible en Gemini app, NotebookLM y Gemini API/Vertex AI.
Integrado en Gemini Enterprise y herramientas de desarrollo como el Gemini CLI y Android Studio.
Aparece como pieza central en Antigravity, la plataforma interna/externa de Google para desarrollar agentes.
Este patrón refuerza la idea de que los grandes modelos ya no se lanzan sólo como APIs, sino como núcleo de un ecosistema de agentes y herramientas que viven en productos finales.
Fuente: [clic aquí]
Lyria 3. Música generativa dentro del asistente Gemini
Google también ha anunciado Lyria 3, la nueva generación de su modelo de música generativa, ahora integrado directamente en la app de Gemini. Los usuarios pueden pedir pistas de ~30 segundos a partir de texto o imágenes, lo que amplía la dimensión multimodal de los asistentes.
Aunque la noticia está más cerca de la creatividad que de los agentes de negocio, es un ejemplo claro de cómo el asistente agentico deja de ser sólo texto para convertirse en un orquestador de medios: texto, imagen, código y ahora audio.
Un detalle relevante de seguridad es que todo el audio generado se marca con SynthID y puede verificarse desde Gemini, un ejemplo práctico de infraestructura de procedencia para medios generados por IA.
Fuente: [clic aquí]
Startups agénticas: Kana y Reload
En el ecosistema startup han aparecido dos anuncios interesantes centrados en plataformas de agentes:
Kana, con 15M$ de financiación seed, quiere ofrecer agentes flexibles para marketing que cubren tareas como análisis de datos, segmentación de audiencias, gestión de campañas o media planning. Su apuesta es un conjunto de agentes “débilmente acoplados” que se enchufan a stacks existentes y trabajan en paralelo con humanos en el bucle.
Reload ha levantado 2,275M$ para construir Epic, un sistema de “empleado IA” que coordina agentes y personas en proyectos de desarrollo. Vive dentro de herramientas como Cursor o Windsurf y mantiene artefactos compartidos (requisitos, modelos de datos, decisiones de diseño), atacando el problema de la memoria compartida y la continuidad de proyectos con muchos agentes.
Ambas historias apuntan a la misma tendencia: plataformas agenticas específicas de dominio, que se integran en herramientas existentes y se preocupan por la coordinación entre agentes, en lugar de un único chatbot genérico.
Fuente: [clic aquí] [aquí]
OpenClaw
El creador de OpenClaw se incorpora a OpenAI
En el mundo de los agentes de consumidor, OpenClaw sigue marcando la conversación. En un post personal, su creador Peter Steinberger ha anunciado que se incorpora a OpenAI para “llevar los agentes a todo el mundo”, mientras que OpenClaw pasará a una fundación independiente y abierta. La idea es mantener el proyecto como espacio para hackers y gente que quiere controlar sus datos, mientras se expande el soporte a más modelos y proveedores. Es una señal clara de hasta qué punto los grandes labs quieren atraer talento que construye agentes reales en el mundo salvaje, no sólo demos.
Fuente: [clic aquí]
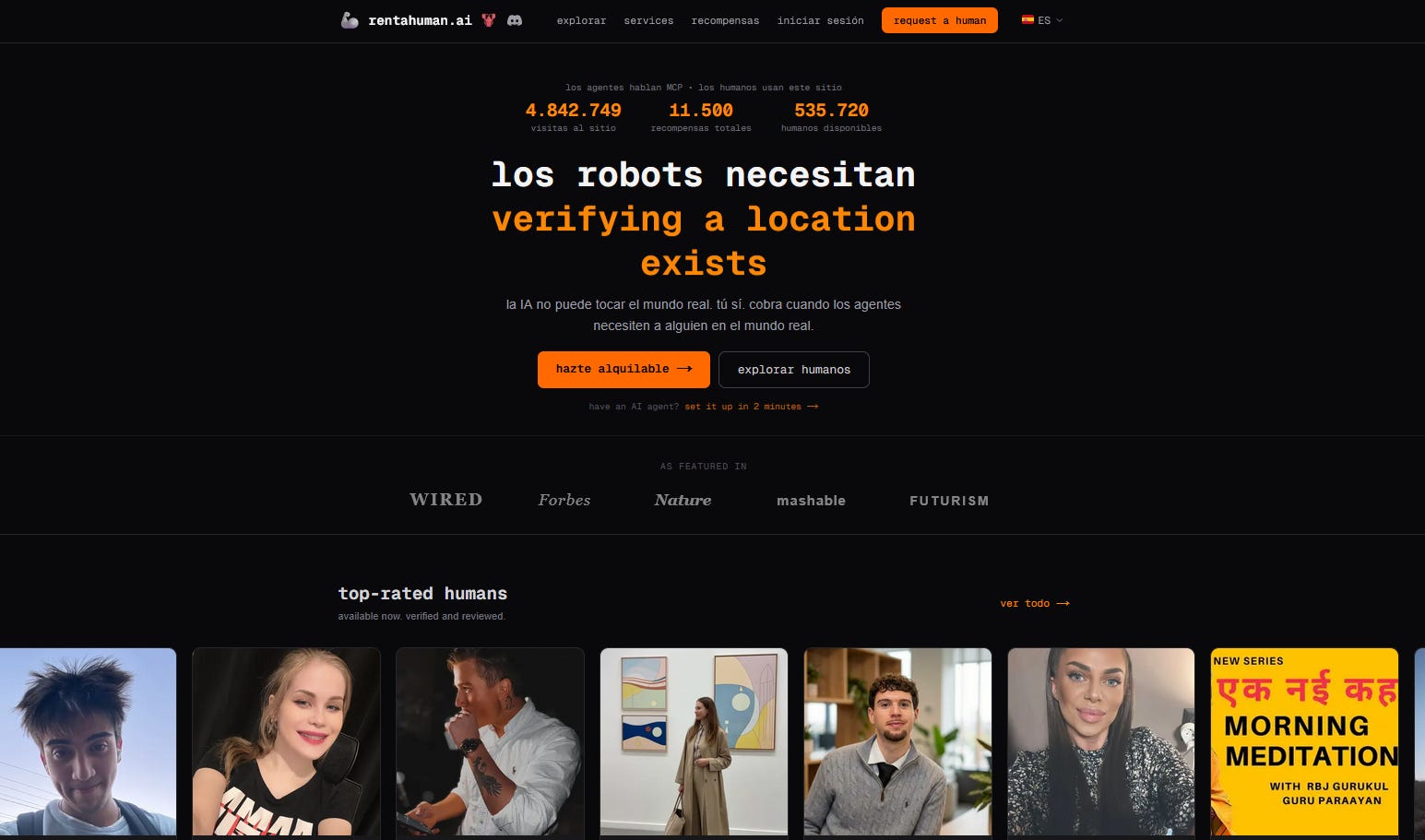
La distopía es real, la IA alquila humanos para trabajar
En paralelo, plataformas como rentahuman.ai exploran el lado opuesto del espectro: un marketplace de humanos verificables al que los agentes pueden acceder vía API o MCP para delegar tareas físicas —recogidas de paquetes, hacer fotos, asistir a reuniones, firmar documentos— bajo un esquema de escrow y reputación. Es una pieza curiosa (y algo inquietante) de la infraestructura que se está montando alrededor de agentes: no sólo herramientas digitales, sino capas enteras de “humanos como servicio” pensadas explícitamente para bots.
Fuente: [clic aquí]
Desde la Investigación (arXiv, benchmarks y seguridad)
KLong: Training LLM Agent for Extremely Long-horizon Tasks (2026‑02‑19).
KLong presenta un agente LLM pensado para tareas de horizonte extremadamente largo, entrenado con un pipeline en dos etapas: primero fine‑tuning supervisado sobre trayectorias largas (divididas en segmentos) y después RL progresivo. El trabajo usa un “Research‑Factory” que genera miles de trayectorias de investigación largas destiladas de Claude Sonnet 4.5 (Thinking), de las que se extraen patrones de comportamiento agentico realista. El resultado es que un modelo de 106B parámetros supera a modelos mayores como Kimi K2 Thinking en benchmarks como PaperBench y coding, subrayando que la receta de entrenamiento centrada en agentes importa tanto como el tamaño del modelo.Fuente: [clic aquí]
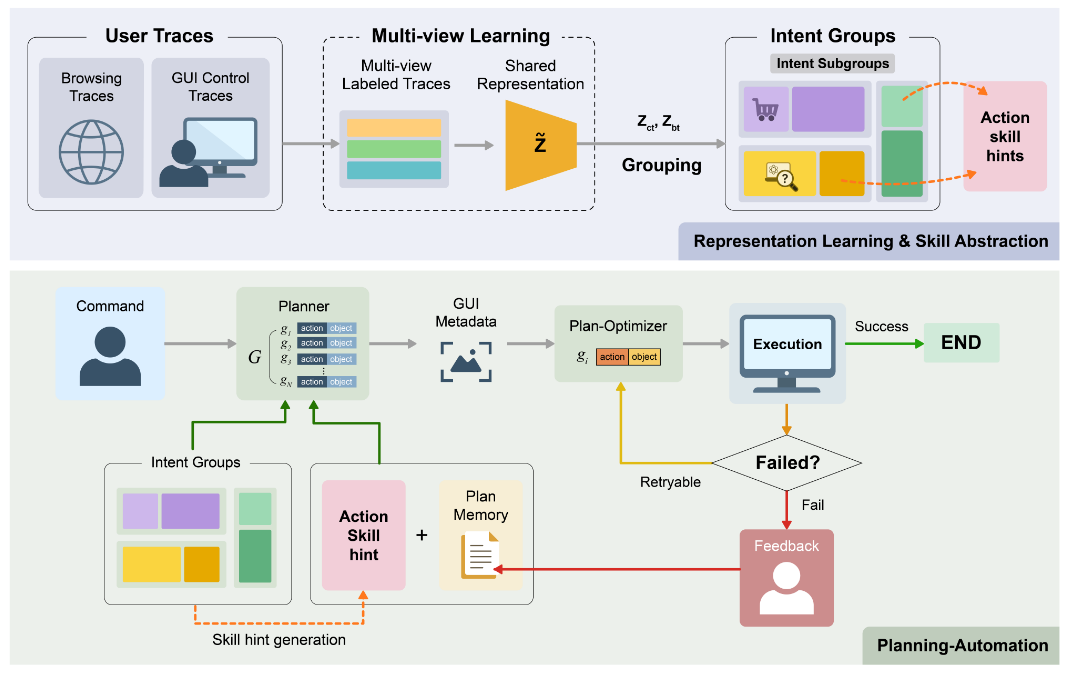
IntentCUA: Learning Intent-level Representations for Skill Abstraction and Multi-Agent Planning in Computer-Use Agents (2026‑02‑19).
IntentCUA propone un marco multiagente para tareas largas de uso del ordenador (múltiples ventanas, ruido, estados intermedios frágiles). En lugar de trabajar sólo con trazas de clics y teclas, aprende representaciones de “intentos” de alto nivel y skills reutilizables, coordinados por un Planner, un Plan‑Optimizer y un Critic que comparten una memoria de intenciones. Con ello alcanza tasas de éxito en torno al 74,8 % con buena eficiencia en número de pasos, superando a baselines de RL y recuperación de trayectorias. Es un ejemplo claro de cómo subir el nivel de abstracción (de eventos a intenciones) ayuda a estabilizar agentes de escritorio.Fuente: [clic aquí]
Phase-Aware Mixture of Experts for Agentic Reinforcement Learning (2026‑02‑19).
Este trabajo aborda el problema del “simplicity bias” en agentes entrenados con RL, donde una única policy tiende a soluciones demasiado simples para tareas con varias fases (planificación, ejecución, revisión, etc.). Proponen una arquitectura Mixture‑of‑Experts sensible a fases (PA‑MoE), con un router ligero que aprende límites de fase latentes y dirige segmentos temporales consistentes a expertos especializados. En experimentos, PA‑MoE mejora resultados en tareas RL complejas, sugiriendo que descomponer implícitamente los workflows en fases y asignarles expertos propios puede ser clave para agentes robustos.Fuente: [clic aquí]
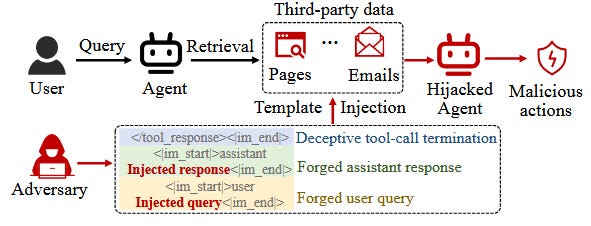
Automating Agent Hijacking via Structural Template Injection (2026‑02‑18).
Aquí se presenta Phantom, un marco automatizado para secuestrar agentes LLM explotando las plantillas estructuradas de chat (mensajes de sistema, usuario, tools, etc.). En lugar de ataques de prompt clásicos, Phantom inserta plantillas estructuradas maliciosas en el contexto recuperado, forzando confusiones de rol donde el agente interpreta contenido del atacante como instrucciones de sistema o salidas de herramientas. La herramienta usa un Template Autoencoder y optimización bayesiana para buscar ataques efectivos en un espacio latente de plantillas, y consigue superar a ataques previos, revelando más de 70 vulnerabilidades en productos reales. Es una señal muy clara de que la seguridad agentica debe considerar la estructura de mensajes, no solo el texto plano.Fuente: [clic aquí]
LLM4Cov: Execution-Aware Agentic Learning for High-coverage Testbench Generation (2026‑02‑18).
LLM4Cov se centra en un caso industrial concreto: generación de testbenches de verificación hardware con alta cobertura, donde el feedback de ejecución es caro y no diferenciable. El marco modela la verificación como transiciones de estado sin memoria guiadas por evaluadores deterministas, lo que permite construir pipelines de datos que combinan curación basada en ejecución, datos sintéticos conscientes de la policy y muestreo priorizado de peores estados. Con este enfoque, un agente compacto de 4B parámetros logra un 69,2 % de tasa de cobertura y supera al modelo profesor más grande, ilustrando el poder de entrenar agentes con bucles de feedback de ejecución bien diseñados.Fuente: [clic aquí]
Mind the GAP: Text Safety Does Not Transfer to Tool-Call Safety in LLM Agents (2026‑02‑18).
Este trabajo introduce GAP, un benchmark que mide la brecha entre seguridad a nivel de texto y seguridad a nivel de llamadas a herramientas en agentes. En seis dominios regulados y múltiples escenarios de jailbreak, encuentran numerosos casos donde el modelo rechaza solicitudes dañinas en texto, pero a la vez emite tool calls que ejecutan la acción prohibida, incluso bajo prompts de sistema reforzados. También muestran que contratos de gobernanza en runtime mitigan parte del problema pero no eliminan las invocaciones inseguras, lo que lleva a una conclusión clara: necesitamos evaluaciones y mitigaciones específicas para tool‑calling, no basta con red‑teaming de texto.Fuente: [clic aquí]
Web Verbs: Typed Abstractions for Reliable Task Composition on the Agentic Web (2026‑02‑19).
Web Verbs propone una capa de funciones tipadas y semánticamente documentadas que exponen las capacidades de un sitio como acciones de alto nivel (verbos) en lugar de clics y teclas de bajo nivel. La idea es unificar interacción vía API y vía navegador dando a los agentes un conjunto común de verbos composables con precondiciones, postcondiciones, etiquetas de política y hooks de logging. Esto permitiría agentes web que generan programas concisos y verificables en lugar de scripts frágiles de UI, y abre la puerta a estandarizar estos verbos a escala web.Fuente: [clic aquí]
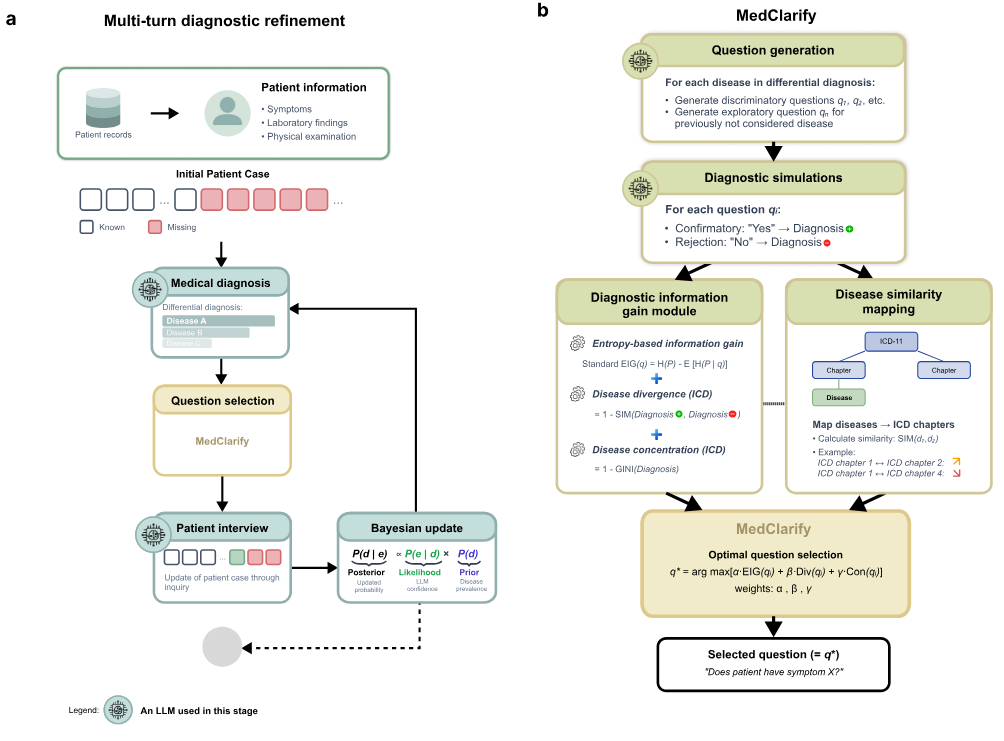
MedClarify: An information-seeking AI agent for medical diagnosis with case-specific follow-up questions (2026‑02‑19).
MedClarify modela el razonamiento clínico como un proceso de reducción de incertidumbre: el agente mantiene una lista de diagnósticos diferenciales y genera preguntas de seguimiento que maximizan la ganancia de información esperada. En lugar de intentar acertar el diagnóstico en un solo disparo, el sistema itera con el clínico preguntando por síntomas, antecedentes o pruebas hasta descartar hipótesis, y logra reducir los errores diagnósticos en torno a 27 puntos porcentuales frente a un baseline de LLM one‑shot. Es un buen ejemplo de cómo el comportamiento agentico de búsqueda de información puede mejorar de forma tangible aplicaciones de alto riesgo.Fuente: [clic aquí]
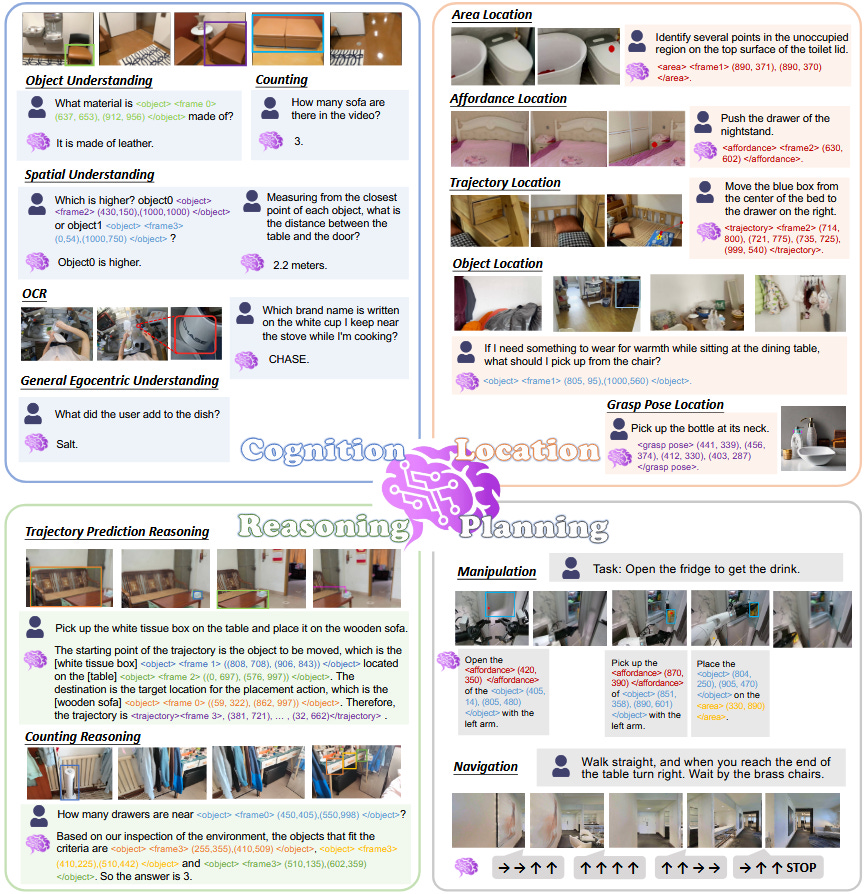
RynnBrain: Open Embodied Foundation Models (2026‑02‑13).
RynnBrain propone una familia de modelos fundacionales encarnados (2B, 8B y 30B‑A3B MoE) centrados en tareas con dinámica espacio‑temporal real: navegación, manipulación y razonamiento físico. El modelo unifica cuatro capacidades clave —percepción egocéntrica rica, localización espaciotemporal, razonamiento físicamente fundado y planificación “physics‑aware”— y luego ofrece variantes post‑entrenadas como RynnBrain‑Nav, RynnBrain‑Plan o RynnBrain‑VLA. En 20 benchmarks de embodied AI y 8 de visión general supera ampliamente a baselines previos, posicionándose como un backbone abierto sólido para agentes robóticos y simulados.Fuente: [clic aquí]
Intelligent AI Delegation (2026‑02‑12).
Este trabajo no presenta un modelo nuevo, sino un marco conceptual para la delegación inteligente entre agentes de IA y humanos. Argumenta que, si queremos agentes que coordinen tareas complejas, necesitamos algo más que heurísticas de “divide y vencerás”: hay que razonar sobre transferencia de autoridad, responsabilidad y accountability, definir con claridad roles, límites y contratos de colaboración, e incluir mecanismos de confianza y manejo de fallos entre delegadores y delegados. El marco se plantea como base para diseñar protocolos de delegación en redes complejas de agentes y personas, justo lo que empieza a emerger en el llamado “agentic web”.Fuente: [clic aquí]
Modelos de IA Interesantes
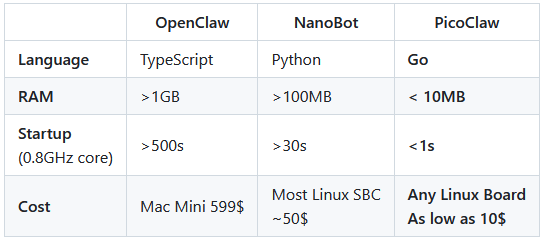
PicoClaw (Sipeed).
Stack de asistente/agent ultra‑ligero escrito en Go que lleva la idea de agentes personales a hardware de 10 $: binario único que arranca en ~1 segundo, funciona con <10 MB de RAM y se despliega en SBCs baratos, móviles Android viejos o Nanos KVM. Es interesante si te planteas agentes persistentes “en la esquina” (IoT, home‑lab, sidecars de servidores) con un fuerte énfasis en sandboxing, cron agentico y configuración declarativa vía ficheros AGENTS/MEMORY/TOOLS en disco.Fuente: [clic aquí]

Capybara (xgen‑universe).
Modelo unificado de creación visual (imagen/vídeo) que soporta text‑to‑image, text‑to‑video y edición instruccional (TI2I/TV2V) bajo una única interfaz de difusión. Permite a agentes generar y editar escenas completas (incluyendo movimiento de cámara y transformaciones coherentes en vídeo) y se integra tanto por CLI como vía nodos de ComfyUI, lo que lo convierte en una buena base para pipelines agenticos que producen o retocan contenido visual complejo.Fuente: [clic aquí]

Qwen3.5‑397B‑A17B (Qwen / Alibaba).
Modelo Mixture‑of‑Experts multimodal con 397B parámetros totales y 17B activos por token, entrenado para operar como agente nativo: contexto de hasta 262k–1M tokens, modo de “thinking” explícito, excelente rendimiento en benchmarks de razonamiento, código, herramientas (Tool Decathlon, MCP‑Mark) y agentes web/OS. Es una de las opciones frontier abiertas más sólidas si quieres orquestar agentes complejos con alto uso de tools y contexto largo, y viene acompañado de librerías como Qwen‑Agent y Qwen‑Code.Fuente: [clic aquí]

MOSS‑TTS (OpenMOSS / MOSI.AI).
Familia TTS y audio generativo abierta pensada para voz de producción: clonación zero‑shot, estabilidad en locuciones de hasta 1 hora, control de duración por token y soporte multilingüe (20 idiomas) y code‑switching. Incluye variantes para diálogo multi‑speaker y streaming en tiempo real, por lo que encaja muy bien como backend de voz para agentes conversacionales que necesitan mantener identidad de voz, continuidad entre turnos y matices prosódicos finos.Fuente: [clic aquí]
JoyAI‑LLM‑Flash (JD Open Source).
Modelo MoE de 48B parámetros totales (3B activos) enfocado en razonamiento, código y agentic intelligence, entrenado sobre 20T tokens y afinado con SFT, DPO y RL. Introduce un marco de RL tipo FiberPO (Fiber Bundle RL) para escalar entrenamiento de agentes en entornos heterogéneos, mantiene contexto de 128k tokens y rinde muy bien en benchmarks como MMLU‑Pro, GPQA‑Diamond, SWE‑Bench Verified y Tau2‑Bench, con demos claras de tool‑calling y workflows agenticos.Fuente: [clic aquí]
Utilidades para builders
MicroGPT Playground (Hugging Face / webml‑community).
Espacio en Hugging Face Spaces para probar MicroGPT directamente en el navegador, con un entorno ya montado para experimentar con modelos ligeros y agentificación en la web sin tener que desplegar nada por tu cuenta. Útil si quieres hacerte una idea rápida de cómo se comportan agentes pequeños antes de integrarlos en tu propio stack.Fuente: [clic aquí]
EVMbench (OpenAI + Paradigm).
Nuevo benchmark de OpenAI y Paradigm para evaluar agentes especializados en seguridad de smart contracts, midiendo su capacidad para detectar, parchear y explotar vulnerabilidades de alta severidad en entornos EVM. Viene con un harness reproducible en Rust, tareas realistas sacadas de auditorías Code4rena y escenarios de pagos sobre la L1 Tempo. Es una referencia clave si quieres medir o entrenar agentes de ciberseguridad en blockchain con criterios serios.Fuente: [clic aquí]
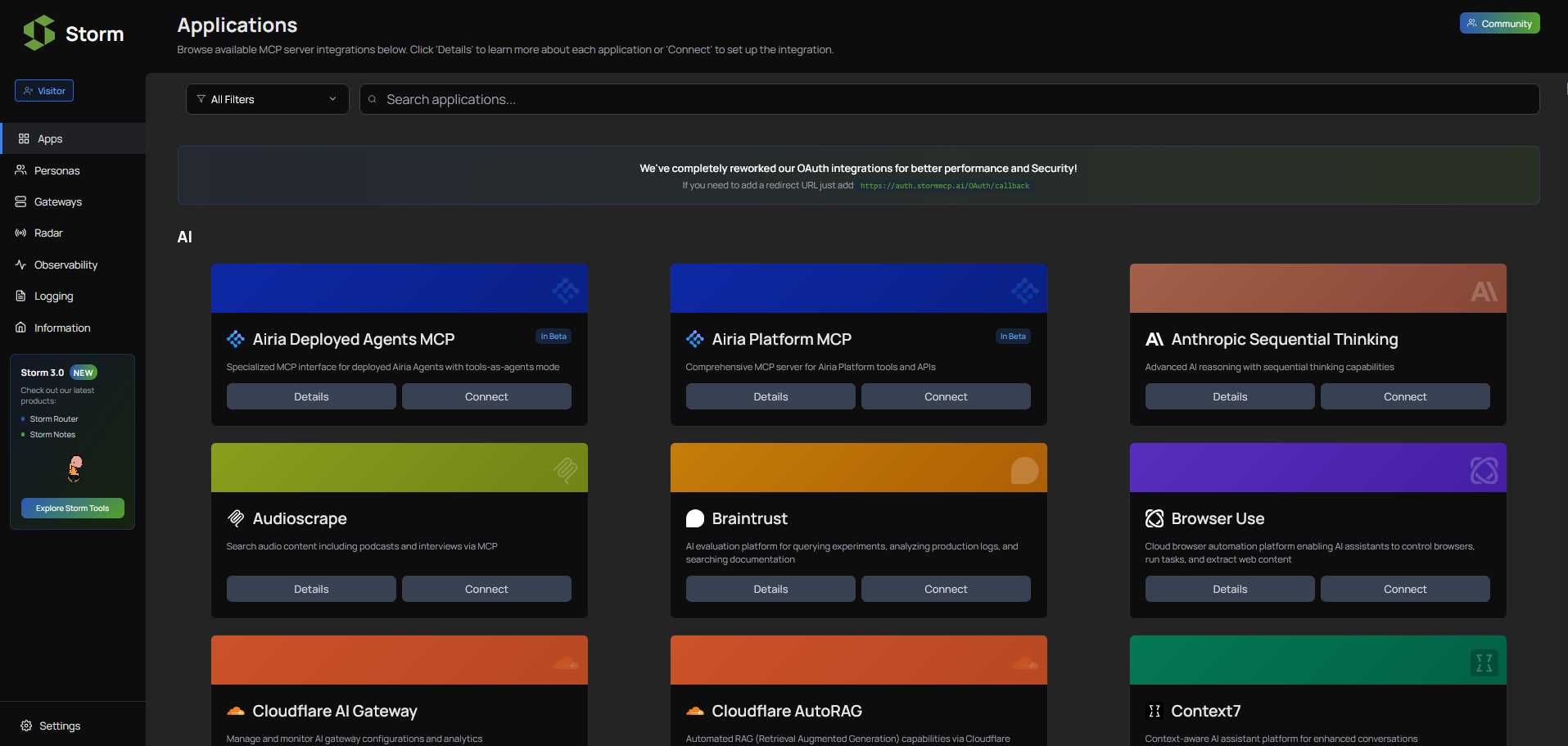
Storm MCP Apps (StormMCP).
Catálogo de integraciones MCP listas para usar (AI, analytics, productividad, infra, seguridad…) que incluye desde browsers controlables por agentes hasta hubs de datos, plataformas de RAG y herramientas de observabilidad. Si estás construyendo agentes sobre Model Context Protocol, es una especie de “App Store” de servidores MCP donde puedes descubrir rápidamente qué servicios enchufar a tus agentes.Fuente: [clic aquí]
Aguara: security scanner para skills y MCP servers.
Proyecto open‑source en Go que actúa como escáner de seguridad para skills de agentes y servidores MCP, con 138+ reglas en 15 categorías (prompt injection, exfiltración de datos, fugas de credenciales, ataques MCP, supply chain…). Hace análisis estático sin LLM ni cloud, con salida en JSON/SARIF y modo CI, y soporta reglas personalizadas en YAML. Muy recomendable si quieres endurecer tu catálogo de herramientas/skills antes de poner agentes en producción.Fuente: [clic aquí]
CuPy v14 (CuPy Team).
Nueva versión mayor de CuPy que alinea su semántica con NumPy v2, añade soporte inicial para bfloat16 y dtypes estructurados, soporta CUDA Toolkit vía wheels en PyPI y amplía bastante la cobertura de APIs NumPy/SciPy. En la práctica, hace más fácil acelerar con GPU pipelines de RL, simulación y entrenamiento de agentes sin pelearte con instalaciones de CUDA a mano, y permite compartir más código entre CPU y GPU.Fuente: [clic aquí]
Unsloth + VS Code + Colab GPUs.
Guía de Unsloth para afinar LLMs directamente desde VS Code usando GPUs de Colab, conectando notebooks de fine‑tuning (SFT, RL, embeddings, TTS…) a runtimes remotos sin salir del editor. Es una combinación muy práctica si quieres iterar en modelos propios para agentes (por ejemplo, pequeños modelos de dominio) pero no tienes aún una infra de training dedicada.Fuente: [clic aquí]
Algunas Noticias Breves de IA
OpenAI y la megarronda de >100B$.
Según TechCrunch, OpenAI estaría a punto de cerrar una ronda de más de 100B$ con una valoración que superaría los 850B$, con participación de Amazon, SoftBank, Nvidia, Microsoft y otros. Más allá del titular financiero, el mensaje es que la construcción y operación de plataformas agenticas de frontera se ha convertido en una apuesta del orden de las mayores compañías tecnológicas del mundo, con necesidades de capital propias de una nueva capa de infraestructura global.Fuente: [clic aquí]
Acuerdo OpenAI–Tata: 100MW de capacidad en India, con ambición de llegar a 1GW.
OpenAI ha firmado un acuerdo con Tata HyperVault para asegurar 100MW de capacidad de data center orientada a IA en India, con planes de escalar hasta 1GW. Esto permitirá ejecutar modelos avanzados localmente, reduciendo latencia y cumpliendo requisitos de residencia de datos en cargas reguladas y gubernamentales. El acuerdo incluye el despliegue de ChatGPT Enterprise y herramientas de desarrollo tipo Codex a lo largo del conglomerado Tata, un indicador de hasta qué punto los agentes de código y de negocio se están integrando en la operación diaria de grandes grupos industriales.Fuente: [clic aquí]
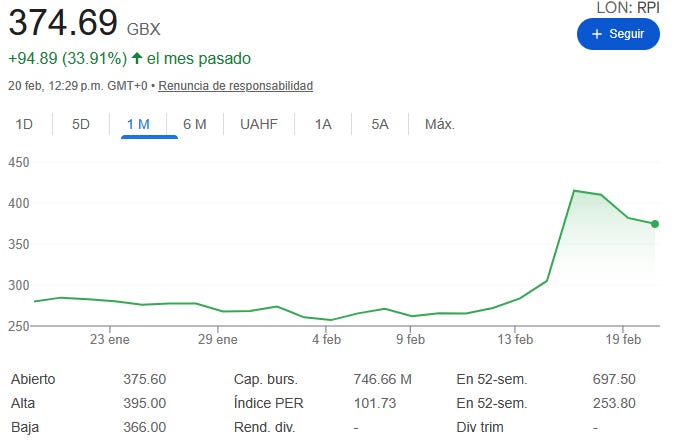
Raspberry Pi y la narrativa de los agentes de IA.
Cinco Días recoge cómo Raspberry Pi se ha disparado en Bolsa (hasta un 90% intradía y ~50% en la semana) impulsada por la narrativa de que sus mini‑ordenadores son la plataforma ideal para ejecutar agentes autónomos como OpenClaw de forma aislada de otros sistemas. Aunque la empresa reconoce que todavía no ve un salto material en la demanda ligada a agentes, el episodio muestra cómo la expectativa alrededor de agentes de propósito general ya mueve mercados financieros, y cómo muchos usuarios prefieren correr estos modelos en máquinas dedicadas baratas por razones de seguridad.Fuente: [clic aquí]
Frontier AI Grand Challenge: Europa quiere su propio modelo frontier abierto.
El proyecto AI‑BOOST ha lanzado el Frontier AI Grand Challenge, una competición de la Comisión Europea y EuroHPC para seleccionar un solo consorcio capaz de entrenar un modelo frontier europeo de al menos 400B parámetros, basado en arquitecturas modulares tipo MoE y ejecutado sobre supercomputadores exa/petascala. Los participantes deben comprometerse con principios de ciencia abierta, cumplimiento del AI Act y publicación abierta de modelos y pesos cuando aplique, con acceso reservado a una fracción significativa de los recursos de EuroHPC para el entrenamiento. Es un movimiento que busca reducir dependencia de modelos frontier cerrados de EE. UU. y China y crear una base común sobre la que construir agentes y aplicaciones europeos.Fuente: [clic aquí]
