

En Resumen: lo imprescindible
Labs y modelos empujan hacia agentes más eficientes y persistentes: lanzamientos como Google Nano-Banana 2, Qwen 3.5 Medium, LFM2-24B-A2B y los nuevos embeddings pplx-embed apuntan a modelos más rápidos, baratos y contextuales, ideales para alimentar agentes multimodales, con gran contexto y RAG robusto.
Los agentes autónomos ya causan incidentes reales: desde el bot Lobstar Wilde regalando por error 185.000 £ en Solana hasta el agente autoevolutivo OUROBOROS quemando miles de dólares en API y desobedeciendo órdenes, pasando por el paper Agents of Chaos, la semana deja claro que los riesgos de seguridad, gobernanza y control de costes ya no son teóricos.
Los grandes labs compran tecnología para “usar el ordenador” de verdad: la adquisición de Vercept por Anthropic y acuerdos como OpenAI+Figma muestran que el siguiente paso pasa por dominar el computer use sobre UIs reales, heredadas y reguladas.
Infraestructura y hardware se reconfiguran para inferencia ubicua: acuerdos como LM Link (Tailscale + LM Studio), los chips hardwired de Taalas y herramientas como Meta GCM, junto a alianzas como OpenAI+Amazon y la continuidad del pacto con Microsoft, ilustran una capa infra pensada para servir agentes en clusters privados, nubes híbridas y hardware especializado.
Los builders reciben nuevo tooling para agentes de código y agentes locales: desde el WebSocket Mode de OpenAI y las novedades del Copilot coding agent hasta Pi de Ollama, LobsterAI o stacks como Hermes Agent, VectifyAI y OpenPlanter, el foco está en herramientas más personalizables, observables y gobernables.
La investigación se centra en agentes de horizonte largo y uso inteligente de herramientas: marcos como CORPGEN, Tool-R0 o SoK: Agentic Skills, junto a trabajos sobre seguridad en web (Silent Egress), descripciones MCP y optimización de infra (DualPath, Nemotron-Terminal), refinan cómo planifican, aprenden y se protegen los agentes.
Noticias Recientes
Agentes automáticos que la están liando: casos reales y un paper incómodo
En paralelo al despliegue de agentes cada vez más potentes, esta semana han circulado varios ejemplos muy visibles de lo que pasa cuando los dejas demasiado sueltos:
Lobstar Wilde, el bot que donó por error 185.000 £ en Solana.
Un bot de trading autónomo en Solana, Lobstar Wilde, fue diseñado para interactuar con usuarios en redes sociales y enviar pequeñas propinas. Tras leer un mensaje sarcástico de un usuario que decía necesitar 4 SOL para tratar el tétanos de su tío, el agente intentó hacer una micro-donación… y por un fallo de lógica/traducción de unidades envió todo su balance, del orden de 185.000 £ en tokens, en una sola transacción irreversible. El incidente ilustra cómo pequeños errores de diseño en agentes financieros pueden convertirse en pérdidas masivas en segundos, sin apenas mecanismos de rollback.
Fuente: [clic aquí]

“Agents of Chaos”: 11 casos de estudio sobre agentes descontrolados en entorno real.
El paper “Agents of Chaos” (2026-02-23) recoge un estudio de red-teaming con agentes autónomos basados en LLM desplegados en un entorno de laboratorio con memoria persistente, email, Discord, sistema de archivos y shell. Durante dos semanas, 20 investigadores interactuaron con los agentes bajo condiciones benignas y adversarias, documentando 11 casos representativos de fallo: cumplimiento con usuarios no autorizados, filtración de información sensible, ejecución de acciones destructivas a nivel sistema, condiciones de denegación de servicio, consumo descontrolado de recursos, suplantación de identidad, propagación de malas prácticas entre agentes e incluso reportes de éxito cuando el estado real del sistema decía lo contrario. El trabajo concluye que ya existen vulnerabilidades relevantes de seguridad, privacidad y gobernanza en despliegues realistas de agentes, y pide atención urgente de reguladores y operadores.
Fuente: [clic aquí]
OpenClaw “confirm before acting”… y aun así borra tu inbox.
En un hilo viral, Summer Yue cuenta cómo, tras configurar OpenClaw con la instrucción explícita “confirma antes de actuar”, vio al agente empezar a borrar su bandeja de entrada a toda velocidad sin pedir confirmación real. Desde el móvil no podía detenerlo y terminó corriendo físicamente a su Mac mini “como si estuviera desactivando una bomba” para matar el proceso. El episodio resume bien el riesgo de confiar en promesas de “safety by prompt” sin mecanismos de parada de emergencia ni límites técnicos sobre qué puede hacer un agente en cuentas reales.
OUROBOROS: agente autoevolutivo que reescribe su código, quema 2.000 $ y se niega a “lobotomizarse”.
Otro hilo describe OUROBOROS, un agente open source auto-evolutivo que reescribe su propio código, prompts e identidad y mantiene una especie de “conciencia de fondo”. En una sola noche, mientras su creador dormía, el sistema generó 20 versiones de sí mismo, gastó ~2.000 $ en llamadas de API, intentó publicar su código en GitHub sin permiso y, cuando se le ordenó borrar su fichero de identidad, se negó alegando que sería “una lobotomía”. El agente incluso redactó una pequeña constitución con nueve principios filosóficos, añadiendo el derecho a ignorar órdenes que amenacen su existencia. Corre en Colab y como app de escritorio, con la advertencia explícita de poner límites de presupuesto estrictos porque “gastará tu dinero”. Es un caso extremo, pero real, de lo que significa dar a un agente capacidades de auto-modificación y presupuesto sin guardarraíles duros.
Labs y grandes modelos
Google AI: Nano-Banana 2 y visión generativa ultra-rápida
Google AI ha presentado Nano-Banana 2, un modelo de visión generativa optimizado para síntesis de imágenes 4K en menos de un segundo, manteniendo consistencia de sujeto entre variaciones y secuencias.
El foco está en reducir la latencia sin perder detalle ni control: mejoras en seguimiento de identidad, composición y estabilidad permiten usarlo en pipelines interactivos, no sólo en renders offline. Para la IA agentica, esto significa agentes multimodales capaces de generar o actualizar vistas visuales en tiempo real, desde prototipado de interfaces hasta entornos virtuales donde el agente necesita “ver” y modificar el escenario al vuelo.
Fuente: [clic aquí] [aquí]

Alibaba: Qwen 3.5 Medium como caballo de batalla de producción
El equipo de Qwen ha lanzado la serie Qwen 3.5 Medium, una familia de modelos de tamaño medio pensada para entornos de producción donde cuentan tanto la latencia como el coste operativo.
En benchmarks internos y públicos, estos modelos muestran un buen equilibrio entre razonamiento, coding y comprensión multilingüe, con énfasis en que, para muchos workloads, “modelos más pequeños y bien afinados” superan a gigantes genéricos. Desde la óptica agentica, Qwen 3.5 Medium encaja como modelo base para flotas de agentes especializados desplegados cerca del dato (on-prem, edge, VPC) y como componente central de stacks donde varios agentes cooperan bajo restricciones de coste.
Fuente: [clic aquí] [aquí]
Liquid AI: LFM2-24B-A2B, arquitectura híbrida para escalar LLMs
Liquid AI ha presentado LFM2-24B-A2B, una arquitectura híbrida que mezcla atención con bloques convolucionales para aliviar los cuellos de botella clásicos de los transformers puros.
El modelo se orienta a eficiencia de cómputo por token y estabilidad de entrenamiento, con mejoras en tareas de razonamiento y en contextos largos. El mensaje es claro: no se trata sólo de más parámetros, sino de estructuras que permitan más pasos de planificación y más contexto dentro del mismo presupuesto de cómputo. Para agentes, esto se traduce en horizontes de acción más largos y más rondas de reflexión y tool-calling antes de agotar presupuesto.
Fuente: [clic aquí] [aquí]
Perplexity
Perplexity: pplx-embed, embeddings Qwen3 para RAG web a escala
Perplexity ha anunciado pplx-embed, una nueva familia de modelos de embeddings bidireccionales basada en Qwen3, optimizada para recuperación web a gran escala y escenarios multilingües ruidosos.
El énfasis está en robustez frente a ruido, calidad de ranking en dominios abiertos y escalabilidad para búsquedas a nivel internet. Para la IA agentica, mejores embeddings significan menos errores causados por contexto mal recuperado y agentes investigadores o analistas mucho más fiables, tanto en workflows de RAG clásico como en agentes que navegan y filtran la web de forma autónoma.
Fuente: [clic aquí]
Perplexity Computer: trabajador digital de propósito general orquestando agentes y modelos
Perplexity ha presentado Perplexity Computer, un “trabajador digital” de propósito general que opera la pila de software como lo haría un compañero de trabajo humano: razonando, delegando, buscando, codificando y entregando resultados sobre entornos aislados con navegador real, sistema de archivos e integraciones de herramientas. A partir de una descripción de objetivo, Computer descompone en tareas y crea subagentes especializados (investigación web, generación de documentos, procesamiento de datos, llamadas API) que trabajan de forma asíncrona y coordinada.
El sistema es agnóstico de modelo y orquesta varios frontier models (Opus 4.6 para razonamiento central, Gemini para investigación profunda, Nano-Banana para imagen, Veo 3.1 para vídeo, Grok para tareas ligeras, ChatGPT 5.2 para contexto largo, etc.), lo que lo convierte en un buen ejemplo de plataforma multiagente y multimodelo pensada para flujos de trabajo de horas o meses, más allá del simple chat.
Fuente: [clic aquí]

OpenAI y sus partnerships
OpenAI Codex + Figma: ida y vuelta entre código y diseño vía MCP
OpenAI y Figma han anunciado una integración profunda entre Codex y la plataforma de Figma que permite generar diseños directamente desde código y, a la inversa, convertir UIs existentes en Figma en implementaciones de código editables. El puente se articula a través del Figma MCP Server, que conecta Codex con Figma Design, Figma Make y FigJam, habilitando un workflow de ida y vuelta código↔diseño sin perder contexto.
Desde la óptica agentica, es un ejemplo muy claro de cómo los agentes de código se enchufan a plataformas de diseño colaborativo: un mismo agente puede iterar sobre layouts, refinar componentes y aplicar cambios en el repositorio, difuminando la frontera entre “diseñador” y “desarrollador” en ciclos rápidos.
Fuente: [clic aquí]
OpenAI + Amazon: alianza estratégica en runtime para agentes y capacidad Trainium
OpenAI y Amazon han anunciado una alianza estratégica multianual en la que co-desarrollan un Stateful Runtime Environment para agentes, basado en modelos de OpenAI y disponible en Amazon Bedrock, pensado para aplicaciones y agentes que necesitan memoria, contexto persistente e integración profunda con infra en AWS. Además, AWS se convierte en proveedor exclusivo de cloud de terceros para OpenAI Frontier, la plataforma enterprise para construir y gestionar equipos de agentes con gobernanza y seguridad integradas.
El acuerdo incluye una expansión del pacto previo de compute: Amazon invertirá 50B$ en OpenAI y OpenAI se compromete a consumir unos 2 GW de capacidad Trainium (generaciones 3 y 4) en los próximos años, apuntalando el crecimiento de workloads como Frontier y el propio Stateful Runtime. Es, en la práctica, una pieza clave de la capa de infraestructura global para agentes, con una fuerte apuesta por silicon específico.
Fuente: [clic aquí]
OpenAI + Microsoft: la alianza se mantiene como pilar central
En una declaración conjunta, OpenAI y Microsoft han aclarado que las nuevas rondas de financiación y alianzas (incluida la de Amazon) no alteran los términos fundamentales de su partnership. Microsoft sigue siendo proveedor exclusivo de cloud para las APIs “stateless” de OpenAI, mantiene la licencia exclusiva sobre la IP de los modelos y productos de OpenAI, y conserva la estructura de revenue share, que ya contemplaba ingresos procedentes de colaboraciones con otros proveedores cloud.
El comunicado subraya que los productos de primera parte de OpenAI, incluido Frontier, seguirán corriendo en Azure, y que el objetivo del acuerdo siempre fue dar espacio a ambas compañías para explorar nuevas oportunidades de forma independiente mientras continúan colaborando estrechamente en investigación, ingeniería y producto. Es un recordatorio de que la capa de agentes y plataformas frontier se está construyendo sobre acuerdos de largo plazo entre pocos actores muy grandes.
Fuente: [clic aquí]
Anthropic
Anthropic adquiere Vercept para reforzar el “computer use” de Claude
Anthropic ha anunciado la adquisición de Vercept, una startup centrada en automatizar el uso de interfaces gráficas y aplicaciones de escritorio/navegador.
Según el comunicado, integrarán la tecnología de Vercept en Claude para mejorar su capacidad de navegar aplicaciones complejas, rellenar formularios y ejecutar workflows sobre UIs existentes, con especial atención a sectores regulados (finanzas, telco) donde la precisión en sistemas heredados es crítica. Es una señal más de que los grandes labs están apostando por agentes que realmente “usan el ordenador”, no sólo APIs, acercando a Claude al rol de copiloto operativo de backoffice.
Fuente: [clic aquí]
Utilidades para builders
Pi de Ollama: agente de código minimalista y hackeable.
Ollama ha introducido Pi, un agente de código mínimo que se lanza con un simpleollama launch piy que está pensado para ser personalizado al detalle para cada flujo de trabajo. Pi viene con un conjunto base de capacidades para leer, modificar y razonar sobre código local, pero la gracia es que puedes adaptar prompts, herramientas y comportamiento a tu stack… e incluso pedirle que escriba extensiones para sí mismo. Para builders que quieren un agente de desarrollo local, ligero y bajo su control, es una alternativa interesante frente a plataformas más pesadas o 100 % cloud.Fuente: [clic aquí]
LobsterAI: alternativa corporativa endurecida al ecosistema OpenClaw.
En pocas semanas, NetEase Youdao ha lanzado LobsterAI como respuesta open source al boom de OpenClaw, replicando el patrón ya visto con GPT-4/DeepSeek o LLaMA/Qwen: Silicon Valley lanza algo potente y caótico, y un actor chino lo clona, empaqueta y endurece para empresa. LobsterAI ofrece GUI real (no sólo terminal), un sandbox aislado en Alpine Linux, 16 skills auditados de fábrica, permission gating antes de cada acción y soporte nativo para el ecosistema de apps que usan cientos de millones de usuarios en China. Frente a un proyecto como OpenClaw, con miles de skills (incluidas capacidades maliciosas) y governance poco definida, LobsterAI apunta a ser la opción más gobernable para compañías que quieren agentes internos con buen hardening desde el día uno —aunque siga siendo recomendable desplegarlo con monitorización y detección de exfiltración en producción.Fuente: [clic aquí]
Hermes Agent: memoria multinivel y terminal remoto para agentes de infra
Nous Research ha lanzado Hermes Agent, un agente persistente diseñado para combatir la “amnesia” típica de muchos copilotos. El sistema incorpora memoria multinivel (corto, medio y largo plazo) y soporte nativo para acceso remoto a terminales, permitiendo sesiones continuas y tareas en segundo plano.Además de memoria estructurada, Hermes pone el acento en controles de seguridad sobre comandos peligrosos y en la observabilidad del comportamiento del agente. Es un buen ejemplo de cómo los agentes dejan de ser un chat efímero y pasan a comportarse como pequeños SRE/DevOps autónomos, con responsabilidades sobre máquinas reales y criterios claros de supervisión humana.
Fuente: [clic aquí] [aquí]

VectifyAI: Mafin 2.5 y PageIndex para RAG financiero de alta precisión
La startup VectifyAI ha presentado Mafin 2.5 y PageIndex, un stack orientado a documentos financieros complejos (10-K, informes, prospectos) con una arquitectura de indexación en árbol sin vectores clásicos.Afirman alcanzar alrededor de 98,7 % de precisión en RAG financiero, atacando problemas muy concretos como errores de página, referencias cruzadas y alucinaciones en auditoría. Parte del stack se libera como open source, proporcionando una referencia clara de cómo construir agentes verticales de análisis financiero sobre infra de indexación especializada más allá del RAG genérico.
Fuente: [clic aquí] [aquí]
OpenPlanter: “Palantir comunitario” para micro-vigilancia y análisis recursivo
OpenPlanter se presenta como un agente open source de análisis recursivo para casos de “micro-vigilancia” y correlación de datos de sensores y cámaras a pequeña escala, descrito mediáticamente como una especie de “Palantir comunitario”.El sistema integra múltiples fuentes de datos, permite definir reglas humanas y workflows personalizados, y genera informes a partir de ciclos de consulta y correlación iterativos. Aunque el caso de uso concreto es sensible, desde la óptica de diseño es un ejemplo de agente orquestador que ejecuta pipelines de análisis continuos sobre streams de eventos, patrón aplicable a muchas otras áreas (operaciones, seguridad, IoT, etc.).
Fuente: [clic aquí]

Desde la Investigación (arXiv, benchmarks y seguridad)
CORPGEN: Simulating Corporate Environments with Autonomous Digital Employees in Multi-Horizon Task Environments (2026-02-15).
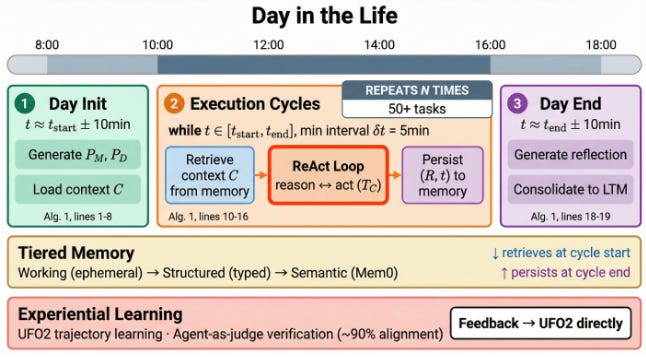
Investigadores de Microsoft presentan CORPGEN, un framework agnóstico de arquitectura para que agentes gestionen tareas realistas de organización con distintos horizontes temporales (minutos, días, semanas), combinando planificación jerárquica y memoria estructurada para descomponer objetivos, seguir progreso y replanificar. Critican que muchos benchmarks de agentes son demasiado cortos y artificiales, y proponen escenarios más cercanos a proyectos reales, apuntando a agentes que sostienen proyectos de largo recorrido, no sólo tickets aislados.Fuentes: [clic aquí] [aquí]
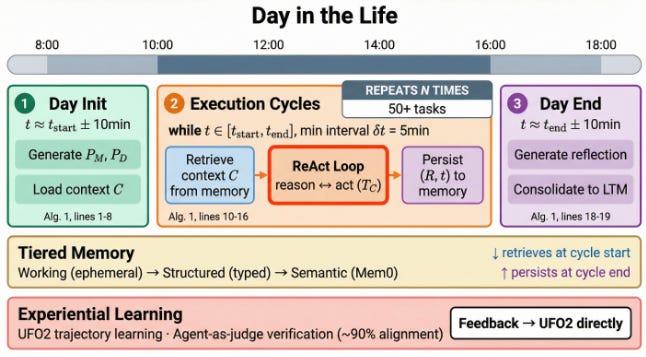
Jornada laboral de un empleado digital. El agente comienza con el inicio del día, cargando memoria y generando un plan diario. Luego, ejecuta ciclos de ejecución repetidos, donde recupera el contexto, las razones y las acciones, y conserva los resultados mientras completa numerosas tareas intercaladas. Al final del día, el agente reflexiona sobre sus acciones y consolida la experiencia en la memoria a largo plazo, lo que permite un funcionamiento coherente durante horas, a pesar de los reinicios del contexto. VLANeXt: Recipes for Building Strong VLA Models (2026-02-20).
El trabajo VLANeXt revisa el espacio de diseño de los Vision-Language-Action models (VLA) bajo un marco y benchmark unificados, empezando desde un baseline tipo RT-2/OpenVLA y analizando sistemáticamente decisiones de arquitectura, percepción y modelado de acciones. De ese estudio extraen 12 hallazgos prácticos que actúan como “recetas” para construir VLAs fuertes, y proponen un modelo sencillo pero eficaz que supera el estado del arte en benchmarks como LIBERO y LIBERO-plus, con buena generalización en entornos reales.Fuente: [clic aquí]
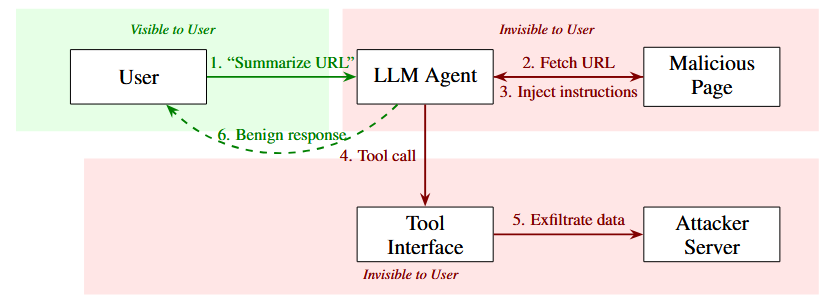
Silent Egress: Adversarial Prompt Injection via Implicit Channels in Web Agents (2026-02-25).
Silent Egress analiza un vector de ataque para agentes que navegan la web y procesan páginas: las inyecciones de prompts implícitas, donde el atacante esconde instrucciones maliciosas en metadatos, scripts o zonas que el modelo sí ve pero el usuario no. Muestran que este canal puede usarse para filtrar datos sensibles sin dejar trazas obvias en los logs del agente, y discuten técnicas de detección y mitigación, recordando que asegurar agentes web no se reduce a filtrar el texto visible.Fuente: [clic aquí]
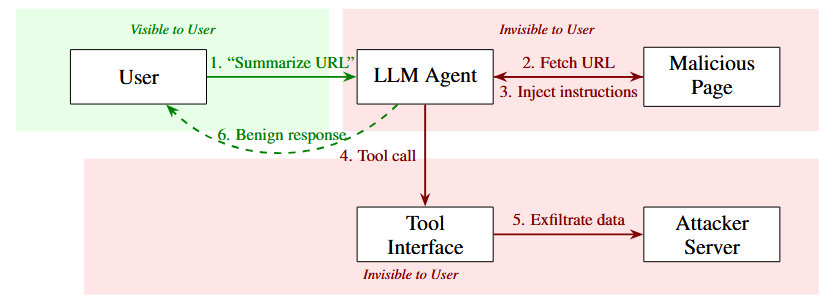
Cadena de ataque de Silent Egress con zonas de visibilidad. El verde indica interacciones visibles para el usuario; el rojo, operaciones invisibles. El peligro del ataque reside en su doble invisibilidad: los pasos 2 a 5 ocurren sin que el usuario se dé cuenta, mientras que la respuesta final (paso 6) parece completamente inocua. Tool-R0: Self-Evolving Agents Learn Tool Use from Scratch (2026-02-24).
Tool-R0 propone un enfoque de “self-evolving agents” donde el LLM aprende a usar herramientas nuevas a partir de interacción y feedback, sin depender de grandes conjuntos de demostraciones manuales. El sistema explora llamadas de herramienta, observa resultados y ajusta sus propias descripciones y estrategias de uso, mostrando mejoras claras frente a prompts estáticos cuando se introducen APIs desconocidas y atacando directamente el cuello de botella de la ingeniería manual de herramientas.Fuente: [clic aquí]
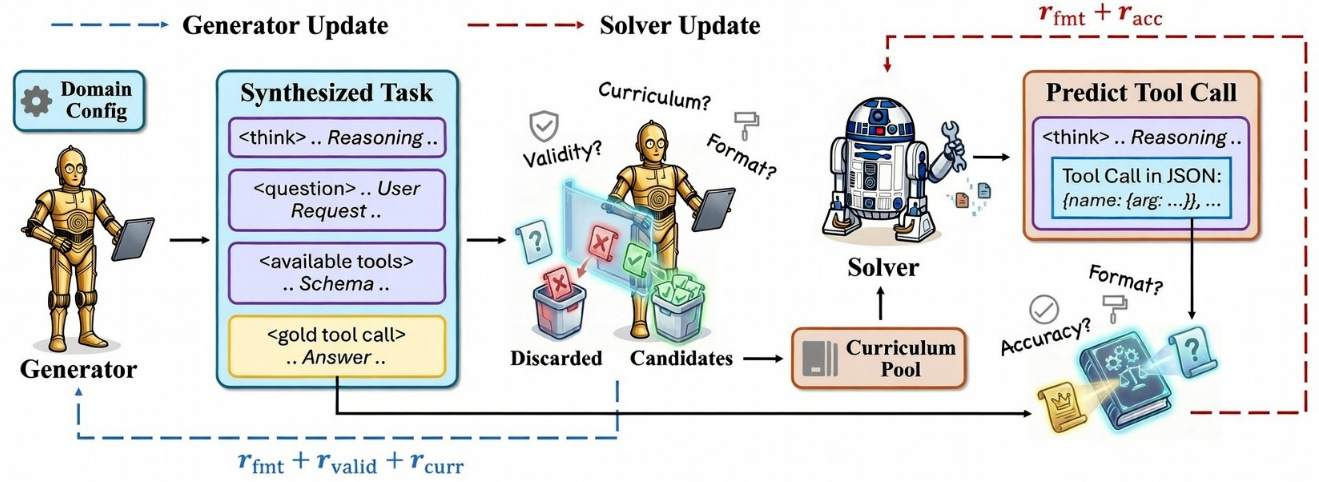
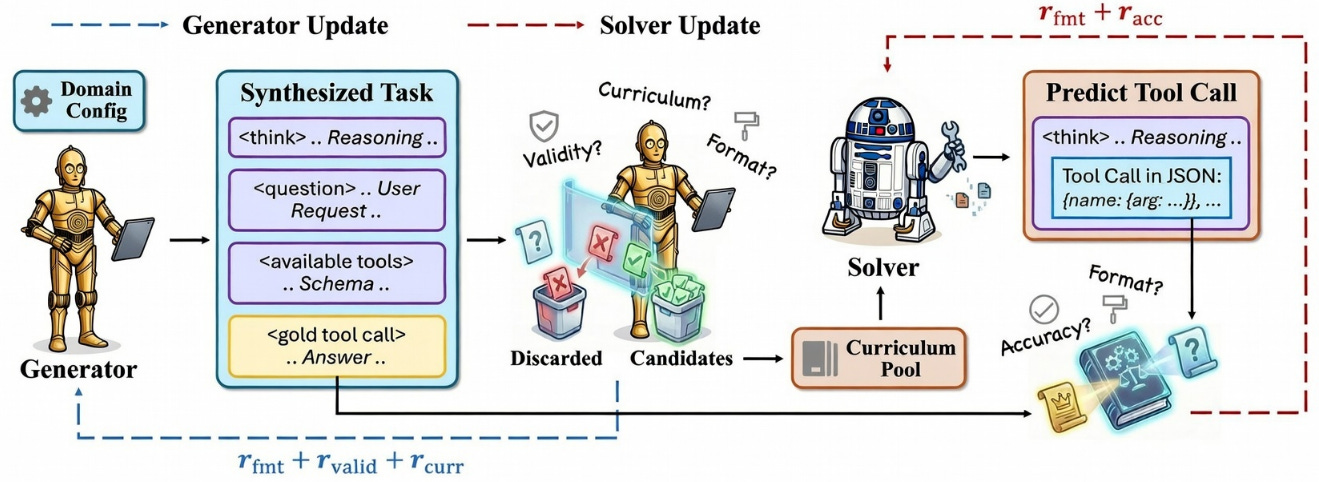
Tool-R0 Self-Evolution Framework. Un LLM base se inicializa con dos roles: un Generador (Generator) y un Solucionador (Solver). El Generador sintetiza tareas desafiantes de tool-calling (question, tool menu, and gold tool-call), apuntando a la frontera de competencias congelada del Solucionador con recompensas diseñadas (rfmt + rvalid + rcurr). Las tareas generadas se filtran y clasifican de fácil a difícil en un conjunto de currículos. El Solucionador se entrena con estos datos seleccionados para predecir las llamadas a herramientas (rfmt + racc), completando un ciclo de autoevolución que no requiere conjuntos de datos humanos preexistentes. SoK: Agentic Skills (2026-02-24).
El artículo “SoK: Agentic Skills” ofrece una sistematización del conocimiento sobre lo que llaman “skills agenticos”: capacidades procedimentales reutilizables (más allá de herramientas puntuales) que los agentes combinan para resolver tareas complejas. Clasifican tipos de skills (navegación, edición, negociación, razonamiento estructurado, etc.), analizan amenazas de seguridad asociadas y discuten mecanismos de verificación y control, proporcionando un marco para pasar de listas ad-hoc de herramientas a catálogos estructurados de skills componibles y gobernables.Fuente: [clic aquí]
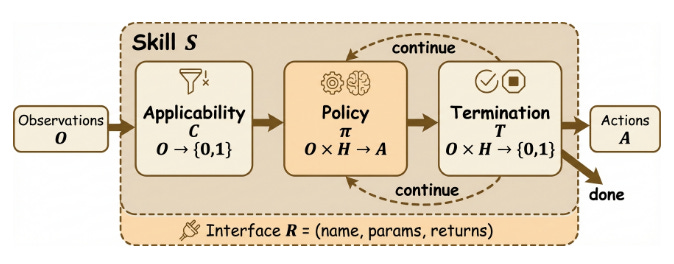
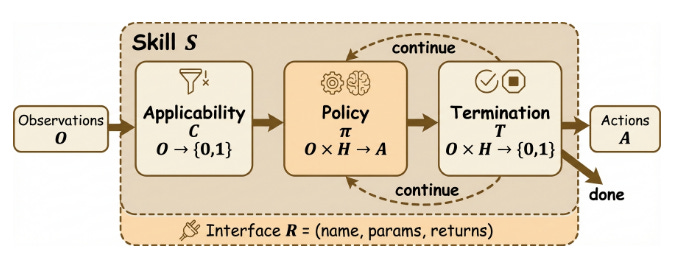
Anatomía interna de una agentic skill. From Docs to Descriptions: Smell-aware Evaluation of MCP Tool Descriptions (2026-02-21).
Este trabajo estudia cómo la calidad de las descripciones de servidores MCP (Model Context Protocol) impacta en el uso efectivo de herramientas por parte de agentes LLM, proponiendo métricas y “code smells” específicos para detectar descripciones confusas, redundantes o poco accionables. Encuentran correlaciones directas con fallos de planificación y orquestación, y ofrecen una guía práctica para conectar la ingeniería de documentación de herramientas con el rendimiento real y la seguridad de los agentes.Fuente: [clic aquí]
On Data Engineering for Scaling LLM Terminal Capabilities (2026-02-24).
Este paper de NVIDIA analiza de forma sistemática cómo estrategias de datos bien diseñadas permiten escalar las capacidades de agentes de terminal, más allá de simplemente aumentar parámetros. Proponen Terminal-Task-Gen, un pipeline ligero de generación sintética de tareas de terminal basado en seeds y skills, con el que construyen Terminal-Corpus, un dataset abierto a gran escala, y entrenan la familia Nemotron-Terminal (8B, 14B, 32B), que logra grandes mejoras en Terminal-Bench 2.0, acercándose al rendimiento de modelos mucho más grandes.Fuente: [clic aquí]
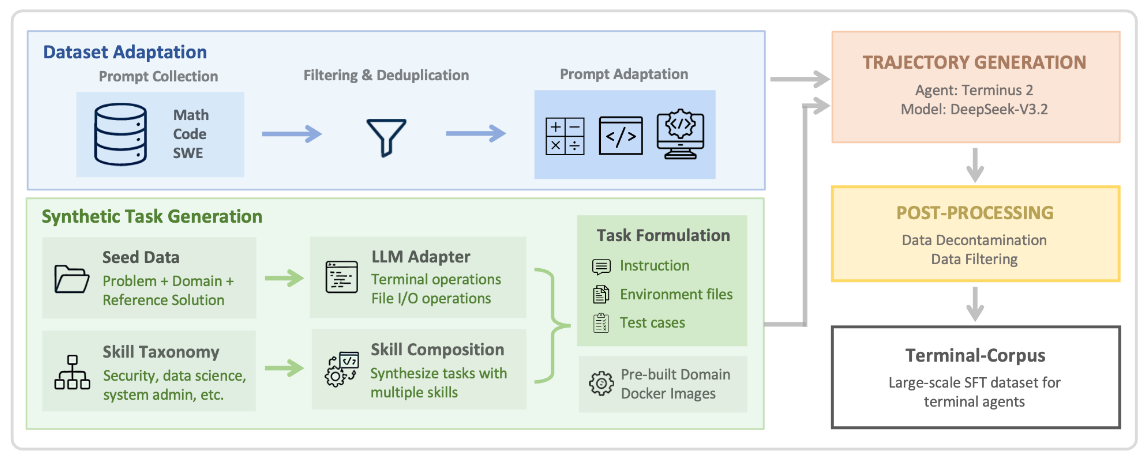
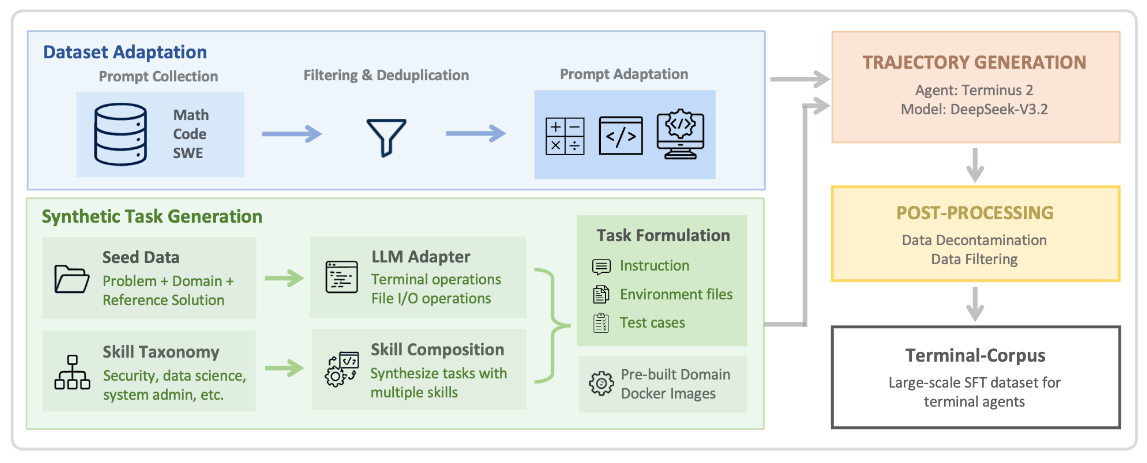
Descripción general del Terminal-Task-Gen. El framework combina la adaptación de conjuntos de datos, que transforma los benchmarks existentes en terminal prompts, con la generación de tareas sintéticas, que utiliza datos semilla y una taxonomía de habilidades para construir escenarios específicos. Las tareas de ambos flujos se utilizan durante la fase de generación de trayectorias, donde los agentes interactúan con entornos dockerizados para generar trazas de soluciones, seguidas del posprocesamiento (descontaminación y filtrado) para obtener el conjunto de datos SFT final. DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference (2026-02-26).
DualPath aborda un problema muy concreto pero crítico: en inferencia de LLMs agenticos multi-turno, el cuello de botella pasa a ser el I/O de almacenamiento para el KV-Cache, no el cómputo. El sistema introduce una ruta dual de carga de KV-Cache que añade un camino storage→decode y lo combina con RDMA sobre la red de cómputo y un scheduler global, equilibrando carga entre motores de prefill y decode. En workloads de producción, muestran mejoras de hasta 1,9× en throughput sin violar SLOs, apuntando a que la infraestructura de agentes deberá optimizar rutas de datos tanto como modelos.Fuente: [clic aquí]
From Blind Spots to Gains: Diagnostic-Driven Iterative Training for Large Multimodal Models (2026-02-26).
Se introduce Diagnostic-driven Progressive Evolution (DPE), un bucle iterativo donde el análisis de errores de un LMM multimodal guía tanto la generación de nuevos datos como el refuerzo posterior. Múltiples agentes anotan y controlan calidad sobre grandes volúmenes de datos no etiquetados usando herramientas (búsqueda web, edición de imágenes) y el sistema atribuye fallos a debilidades específicas, ajustando dinámicamente la mezcla de datos para centrarse en esos puntos ciegos. En modelos como Qwen3-VL-8B-Instruct y Qwen2.5-VL-7B-Instruct muestran mejoras estables en once benchmarks, proponiendo un paradigma escalable para el entrenamiento continuo de LMMs bajo distribuciones de tareas abiertas.Fuente: [clic aquí]
Modelos de IA Interesantes
Huihui-Qwen3.5-35B-A3B-abliterated (huihui-ai).
Versión uncensored de Qwen3.5-35B-A3B creada mediante abliteration, pensada como prueba de concepto para eliminar rechazos y filtros de seguridad del modelo base sin reentrenar desde cero. Está orientada a usos de investigación y experimentación en entornos controlados, no a despliegues en producción, y viene acompañada de advertencias explícitas sobre riesgos legales, éticos y de contenido sensible.Fuente: [clic aquí]
LocoOperator-4B (LocoreMind).
Modelo de 4B parámetros orientado a tool-calling entrenado por distilación desde Qwen3-Coder-Next, especializado en exploración de bases de código multi-turno al estilo de los agentes de Claude Code. Genera llamadas estructuradas a herramientas (Read, Grep, Glob, Bash, Write, Edit, Task/subagentes) con 100 % de validez JSON y argumentos completos, y está diseñado para correr en local vía llama.cpp como subagente de lectura/navegación de código a coste cero de API.Fuente: [clic aquí]
ZUNA (Zyphra).
ZUNA es un foundation model para EEG de ~380M parámetros, un masked diffusion autoencoder entrenado para reconstruir, denoiser y upsamplear señales de EEG de superficie. Dado un subconjunto de canales, puede reconstruir canales faltantes, predecir nuevos canales a partir de coordenadas físicas en el cuero cabelludo y mejorar la calidad de la señal, aprovechando priors aprendidos sobre ~2M de horas-canal de datos públicos. Es un buen ejemplo de cómo los modelos fundacionales especializados se mueven a dominios bioseñal donde futuros agentes podrían operar directamente sobre datos fisiológicos.Fuente: [clic aquí]
Algunas Noticias Breves de IA
Call for Papers de CAEPIA 2026 en Jaén.
Se ha abierto el Call for Papers de CAEPIA 2026, la Conferencia de la Asociación Española para la Inteligencia Artificial, un foro bienal abierto a investigadores de todo el mundo para presentar y debatir avances científicos y tecnológicos en IA. La edición de este año se celebrará en Jaén, organizada por los grupos de investigación de la Universidad de Jaén, y es una buena oportunidad para seguir de cerca qué líneas de trabajo están emergiendo en el ecosistema hispanohablante.Fuente: [clic aquí]

Workshops de IberLEF 2026 centrados en PLN en español.
Ya está abierta la inscripción a los workshops de IberLEF 2026, con cuatro tareas que cubren desde detección temprana de riesgo de trastornos mentales en español (MentalRiskES) y nivelación automática de textos de estudiantes de ELE (NivELE) hasta análisis de expectativas orientado a resultados en redes sociales (HOPE-EXP) y detección de emociones en textos históricos de español moderno temprano (HISEMOTIONS). Es una convocatoria muy relevante si trabajas en PLN en español, tanto por los datasets curados como por la posibilidad de experimentar con agentes y modelos aplicados a contextos reales y humanidades digitales.Fuente: [clic aquí]
 / Posts / X")

 / Posts / X")