
En Resumen: lo imprescindible
GPT-5.4 intenta convertirse en el nuevo “modelo operativo” para agentes de trabajo real: OpenAI unifica reasoning, coding, computer use y tool search en una sola pieza, con mejoras fuertes en OSWorld, BrowseComp y Toolathlon, soporte experimental de hasta 1M tokens en Codex y foco explícito en coste/latencia de workflows agenticos largos.
La hoja de cálculo pasa a ser una superficie agentica de primer nivel: ChatGPT for Excel entra en beta para construir, actualizar y auditar modelos dentro del propio workbook, mientras nuevas integraciones de datos financieros acercan la IA al trabajo diario de analistas, controllers y equipos regulados.
GitHub convierte Copilot en infraestructura de flujo, no solo en chat: GPT-5.4 llega a Copilot, code review pasa a una arquitectura agentica con tool calling, Jira ya puede delegar issues al coding agent, Copilot Memory queda activado por defecto para usuarios Pro y Pro+, y además GitHub sigue afinando el workflow con selector de modelo en PRs e input por imágenes en agent sessions.
Los agentes verticales pisan fuerte en enterprise: AWS lanza Amazon Connect Health para scheduling, documentación clínica y codificación médica; ADP abre un escaparate de agentes en RRHH; y EY empaqueta una capa agentica para ventas sobre Snowflake y Canva.
La investigación se mueve hacia el verdadero cuello de botella de los agentes: STRUCTUREDAGENT, WebFactory, AgentSCOPE, KARL, A-MAC y Memex(RL) muestran que el problema ya no es solo “razonar”, sino planificar tareas largas, recordar mejor, buscar con criterio y no filtrar datos entre tools; además, trabajos como DARE y dLLM amplían la conversación hacia retrieval especializado y nuevas arquitecturas lingüísticas.
La semana también deja una tanda útil de modelos pequeños, multimodales y desplegables: Gemini 3.1 Flash-Lite empuja el segmento de agentes baratos y de gran volumen; la nueva serie pequeña de Qwen 3.5 refuerza el frente edge; LTX-2.3 explora generación conjunta de vídeo y audio; y propuestas como NEO-unify y TiRex apuntan a multimodalidad nativa y series temporales con ambición industrial.
Builders reciben nueva artillería, y ya no solo en evaluación: a benchmarks y harnesses como Judge Reliability Harness, Vibe Code Bench, SWE-CI y RepoLaunch se suman utilidades muy concretas como Scrapling para agentes web, la extensión de FastAPI para VS Code, llmfit para dimensionar modelos locales y LangChain Skills como capa reusable de expertise para coding agents.
La capa edge y embodied también acelera: junto al empuje de modelos compactos, NXP muestra cómo llevar políticas VLA a hardware embebido con captura de datos, fine-tuning, particionado, cuantización y scheduling asíncrono, una señal clara de que los agentes físicos empiezan a aterrizar en ingeniería real.
Noticias Recientes
OpenAI
OpenAI: GPT-5.4 quiere ser el modelo central para trabajo profesional y agentes
OpenAI ha lanzado GPT-5.4 en ChatGPT, API y Codex como su nuevo modelo frontier para trabajo profesional, coding y workflows agenticos. La tesis del lanzamiento es clara: dejar de fragmentar reasoning, coding y computer use en líneas separadas y moverlo todo a un único modelo principal capaz de trabajar con herramientas, navegar software y producir entregables de negocio con menos idas y vueltas.
En sus propias evaluaciones, GPT-5.4 sube a 83,0 % en GDPval, 75,0 % en OSWorld-Verified (por encima de la referencia humana reportada de 72,4 %), 82,7 % en BrowseComp, 54,6 % en Toolathlon y 57,7 % en SWE-Bench Pro. Además introduce tool search en la API, una forma de no meter todas las definiciones de tools en el prompt desde el principio: en MCP Atlas, OpenAI afirma que esta estrategia reduce el uso total de tokens en 47 % manteniendo la misma accuracy. En Codex añade soporte experimental para 1M tokens y un modo explícito de computer use con políticas de confirmación configurables.
Lo relevante no es solo el número de benchmarks, sino el cambio de framing: el modelo ya no se vende como “más listo en abstracto”, sino como mejor operario de software, documentos, hojas de cálculo, navegadores y tool ecosystems grandes. Eso es exactamente el tipo de optimización que importa si lo que quieres son agentes persistentes y económicamente viables en producción.
Fuente: [clic aquí]

GPT-5.3 Instant: la otra batalla es reducir fricción en el uso cotidiano
No toda la semana ha ido de agentes largos y benchmarking duro. OpenAI también ha lanzado GPT-5.3 Instant, una actualización del modelo más usado en ChatGPT centrada en algo menos glamuroso pero muy importante: ser más útil en conversaciones normales. La compañía afirma que reduce rechazos innecesarios, recorta preámbulos moralizantes o excesivamente cautos, mejora la síntesis cuando usa web y baja alucinaciones en dominios sensibles.
Disponible para todos en ChatGPT y en API como
gpt-5.3-chat-latest, este lanzamiento recuerda algo que a veces se pierde en la conversación sobre agentes: gran parte del valor de producto sigue viniendo de tono, juicio práctico, relevancia y fluidez. No todo pasa por ejecutar workflows de 30 pasos; muchas veces el modelo ganador será el que simplemente estorbe menos en el uso diario.
Fuente: [clic aquí]
ChatGPT entra en Excel y se acerca al trabajo real de analistas y financieros
Junto a GPT-5.4, OpenAI ha lanzado ChatGPT for Excel en beta, un add-in que mete ChatGPT directamente dentro de los workbooks para construir, actualizar y analizar modelos sin salir de la hoja de cálculo. En vez de pedir una explicación externa sobre el Excel, el sistema puede operar sobre el propio workbook, preservar fórmulas y estructura, razonar entre hojas y explicar por qué cambió una salida.
OpenAI destaca tres capacidades especialmente importantes: crear o modificar modelos en lenguaje natural, entender dependencias entre sheets y fórmulas y mantener auditabilidad, porque el sistema enlaza sus respuestas a las celdas que toca y pide permiso antes de realizar cambios. La beta empieza a desplegarse para Business, Enterprise, Edu, Teachers, Pro y Plus en EE. UU., Canadá y Australia, con control administrativo en workspaces corporativos.
En paralelo, OpenAI amplía las integraciones de datos financieros dentro de ChatGPT con proveedores como Moody’s, Dow Jones Factiva, MSCI, Third Bridge y MT Newswire, además de soporte para datos propietarios vía apps y MCP. La señal aquí es potente: los asistentes dejan de ser “ventanas de chat” y pasan a ser capas operativas dentro de herramientas nativas de trabajo, justo donde viven hoy el modelado financiero, la diligence y buena parte del trabajo analítico serio.
Fuente: [clic aquí]

GitHub
Copilot se vuelve persistente, multimodelo y conectado a los workflows de ingeniería
GitHub ha concentrado esta semana una oleada de cambios que, vistos en conjunto, convierten a Copilot en algo bastante más ambicioso que un asistente en el editor. Por un lado, GPT-5.4 ya está disponible en Copilot para VS Code, Visual Studio, JetBrains, Xcode, Eclipse, github.com, GitHub Mobile, GitHub CLI y el Coding Agent. Por otro, Copilot code review pasa a una arquitectura agentica con tool calling para recoger contexto adicional del repositorio y generar comentarios más precisos y con menos ruido.
El cambio más visible de workflow es la integración con Jira: ahora puedes asignar un issue al GitHub Copilot coding agent, que analiza la descripción y los comentarios, trabaja en segundo plano, abre un draft PR, publica updates en Jira y formula preguntas aclaratorias si le falta contexto. Es un paso importante porque baja mucho la fricción entre gestión de trabajo y ejecución técnica.
Además, Copilot Memory queda activado por defecto para usuarios Pro y Pro+ en preview pública. Esa memoria es a nivel de repositorio, se valida contra el estado actual del código, se comparte entre coding agent, code review y CLI, y expira a los 28 días. GitHub también añade dos mejoras pequeñas pero reveladoras: selector de modelo en comentarios
@copilotdentro de pull requests y soporte de imágenes como input en agent sessions sobre github.com. La dirección es clara: Copilot se está convirtiendo en una capa agentica distribuida entre IDE, PR, review, issue tracker, terminal y memoria persistente.
Fuente: [clic aquí] [aquí] [aquí] [aquí] [aquí] [aquí]
Amazon y AWS
Amazon Connect Health lleva la narrativa agentica al workflow clínico real
AWS ha presentado Amazon Connect Health, una solución agentica pensada específicamente para healthcare que intenta automatizar tareas administrativas de alto volumen sin sacar a clínicos y staff de sus sistemas existentes. Para organizaciones proveedoras ofrece verificación de paciente (GA) y gestión de citas (preview) con integración EHR, verificación de seguro y disponibilidad 24/7.
Para builders del mundo healthtech, el paquete incluye patient insights (preview), ambient documentation (GA) y medical coding (preview) vía un SDK unificado. La parte más importante no es el titular de “agente para salud”, sino el énfasis en trazabilidad y colaboración humano-IA: AWS insiste en que cada insight, nota clínica o código médico puede rastrearse hasta el transcript o chart de origen, y que los agentes escalan automáticamente a un humano cuando hace falta.
Este tipo de lanzamiento importa porque muestra el punto de madurez que empieza a exigir el mercado: un agente vertical ya no vale por “hablar bien”, sino por integrarse con EHRs, operar con datos clínicos reales, mantener evidencias auditables y funcionar dentro de infra compliance-ready. En otras palabras, menos demo, más infraestructura.
Fuente: [clic aquí]

ADP y EY
Agentes verticales empaquetados para RRHH y ventas
En RRHH, ADP ha lanzado una nueva sección de AI agents dentro de ADP Marketplace para que sus clientes descubran e integren agentes conectados al stack de ADP a lo largo del ciclo de vida del empleado. La compañía define estos agentes no como simples features de IA, sino como soluciones capaces de planificar, actuar y completar tareas multi-step en áreas como contratación, compliance, reporting e inteligencia de workforce.
Lo interesante es que ADP intenta ordenar el ecosistema bajo una capa de gobernanza común: los partners incluidos en el marketplace deben adherirse a principios de IA responsable sobre supervisión humana, privacidad, explicabilidad, mitigación de sesgos y monitoring. Es decir, el agente deja de ser solo “capacidad técnica” y pasa a ser también una unidad de distribución y policy.
En ventas, EY, junto con Snowflake y Canva, ha lanzado EY.ai Agentic for Sales, una plataforma que quiere sustituir el mosaico habitual de dashboards, copilots sueltos y procesos manuales por una capa única de orquestación agentica. El producto cubre identificación y priorización de leads, outreach personalizado, pricing y deal support, automatización contractual y post-sale insights. EY lo desplegará primero como Client Zero en uso interno desde marzo de 2026, con foco inicial en Norteamérica. La conclusión compartida entre ambos anuncios es nítida: los agentes enterprise empiezan a venderse como plataformas de workflow vertical, no como cajas de chat genéricas.
Fuente: [clic aquí] [aquí]
Desde la Investigación (arXiv, benchmarks y seguridad)
STRUCTUREDAGENT: Planning with AND/OR Trees for Long-Horizon Web Tasks (2026-03-05).
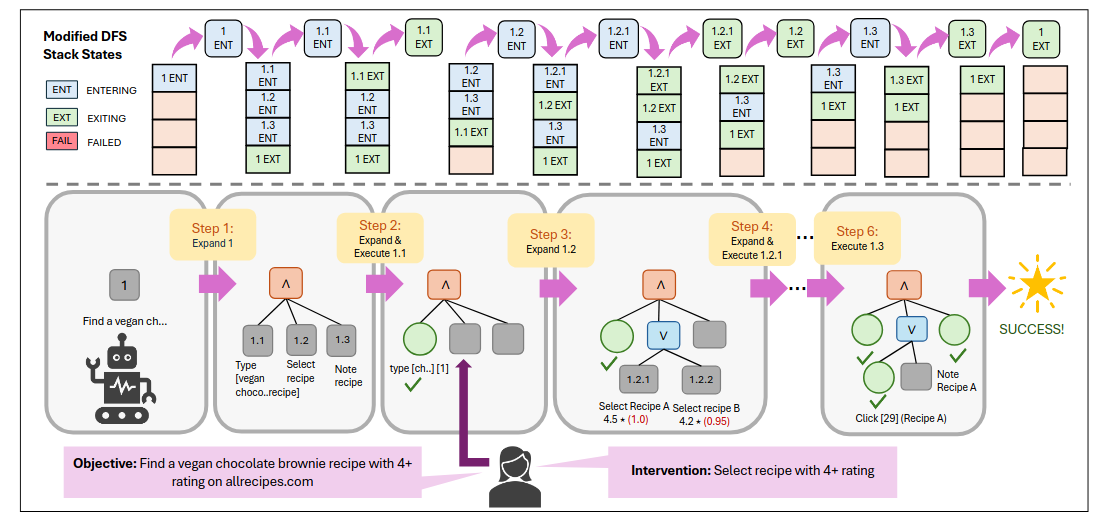
STRUCTUREDAGENT ataca uno de los problemas más obvios de los web agents actuales: cuando la tarea es larga, con restricciones y múltiples ramas posibles, los agentes se vuelven codiciosos, olvidan historia y cierran demasiado pronto. El paper propone un planner online jerárquico basado en árboles dinámicos AND/OR junto con una memoria estructurada que mantiene soluciones candidatas y mejora la satisfacción de restricciones. Además produce planes interpretables, algo útil tanto para debugging como para intervención humana. En WebVoyager, WebArena y benchmarks propios de shopping, el método mejora a agentes estándar basados en LLM.Fuente: [clic aquí]
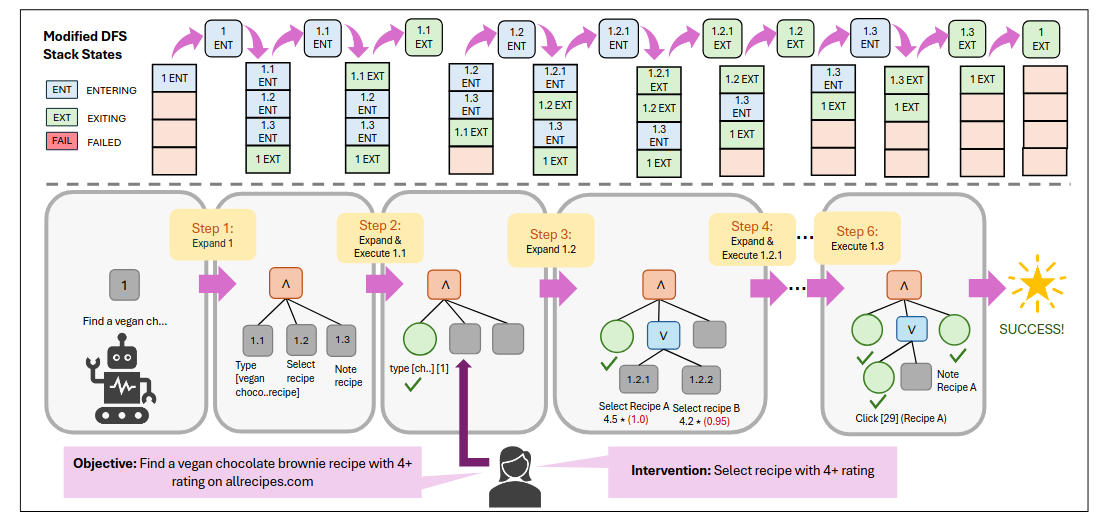
Ilustración de STRUCTUREDAGENT resolviendo una tarea web a través de DFS greedy de un árbol AND/OR construido dinámicamente. WebFactory: Automated Compression of Foundational Language Intelligence into Grounded Web Agents (2026-03-05).
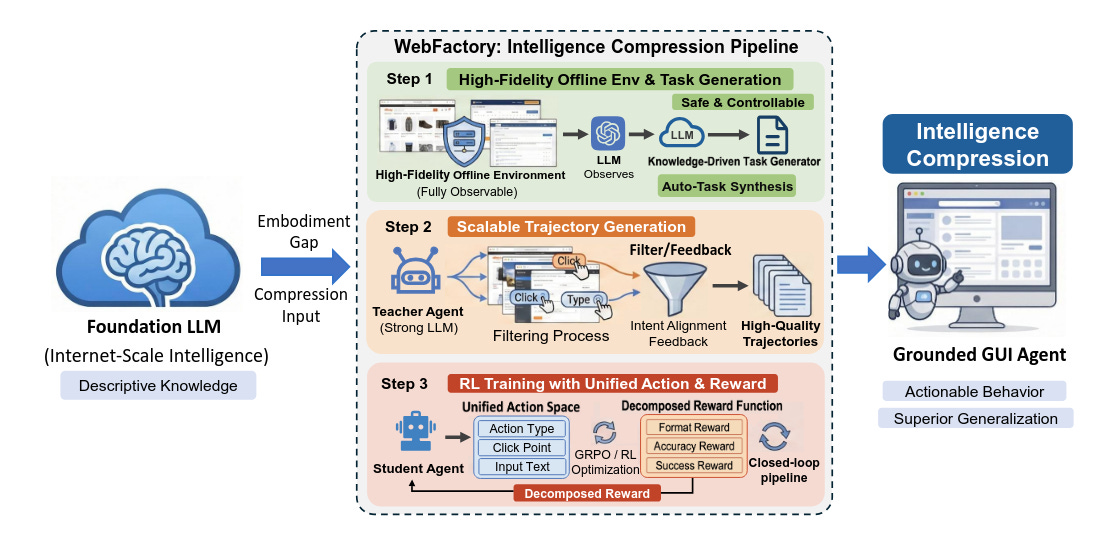
WebFactory propone un pipeline de RL completamente automatizado para entrenar agentes GUI sin depender tanto de interacción web en vivo o de datasets humanos caros y escasos. La idea central es sugerente: lo importante no es solo recolectar más trayectorias, sino comprimir de manera eficiente el conocimiento latente de un foundation model en acciones concretas y situadas. El sistema combina síntesis de entornos, generación de tareas guiada por conocimiento, recogida de trayectorias con LLM, reward decomposition y evaluación. Entrenado con datos sintéticos de solo 10 websites, el agente logra rendimiento comparable al de agentes entrenados con la misma cantidad de datos humanos en muchos más entornos.Fuente: [clic aquí]
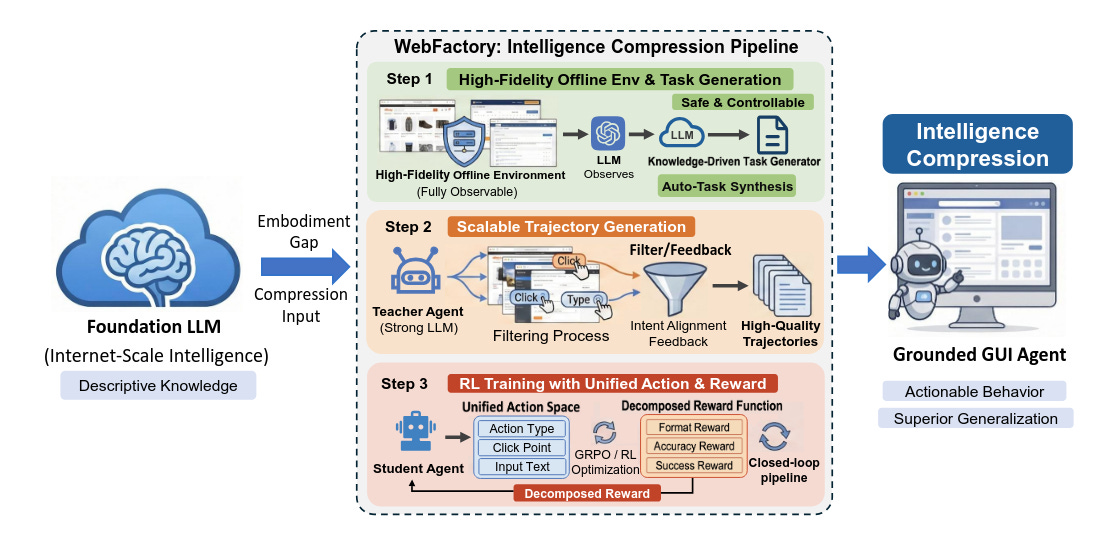
Descripción general de WebFactory, que comprime la inteligencia del modelo base en agentes GUI fundamentados a través de tres etapas: entorno fuera de línea de alta fidelidad y síntesis de tareas, generación de trayectoria escalable y entrenamiento de RL de acción unificada. AgentSCOPE: Evaluating Contextual Privacy Across Agentic Workflows (2026-03-05).
Este trabajo pone el foco en algo crucial: evaluar privacidad solo en input y output es insuficiente cuando un agente atraviesa múltiples tools, APIs y pasos intermedios. AgentSCOPE introduce un Privacy Flow Graph inspirado en Contextual Integrity y un benchmark de 62 escenarios multi-tool en 8 dominios regulatorios, con ground truth en cada etapa del pipeline. El resultado es inquietante: encuentran violaciones de privacidad en más del 80 % de los escenarios, incluso cuando la salida final parece limpia en el 24 % de los casos. La mayoría de problemas aparecen en el momento en que los tools devuelven datos sensibles demasiado generosamente.Fuente: [clic aquí]
KARL: Knowledge Agents via Reinforcement Learning (2026-03-05).
KARL es uno de los trabajos más claramente orientados a agentes de búsqueda y conocimiento empresarial. Introduce KARLBench, una suite con seis regímenes distintos de search agent tasks, y combina datos sintéticos generados con razonamiento largo + tool use con un post-training basado en off-policy RL iterativo a gran escala. Los autores sostienen que un entrenamiento heterogéneo sobre varias conductas de búsqueda generaliza mucho mejor que optimizar para un benchmark aislado. En su propio benchmark, KARL se presenta como Pareto-óptimo en coste-calidad y latencia-calidad frente a modelos cerrados como Claude 4.6 y GPT 5.2, e incluso los supera con suficiente test-time compute.Fuente: [clic aquí]
Adaptive Memory Admission Control for LLM Agents (2026-03-04).
A-MAC aborda un problema poco glamuroso pero muy real: los agentes guardan demasiadas cosas inútiles, obsoletas o alucinadas en sus sistemas de memoria. En vez de dejar la política de memoria totalmente en manos de un LLM opaco, el framework descompone el valor de una memoria en cinco factores interpretables: utilidad futura, confianza factual, novedad semántica, recencia temporal y prior de tipo de contenido. Sobre LoCoMo, el sistema mejora el F1 hasta 0,583 y reduce la latencia en 31 % frente a memorias nativas basadas puramente en LLM. La lección es simple y potente: en agentes persistentes, guardar mejor importa tanto como recordar más.Fuente: [clic aquí]
Memex(RL): Scaling Long-Horizon LLM Agents via Indexed Experience Memory (2026-03-04).
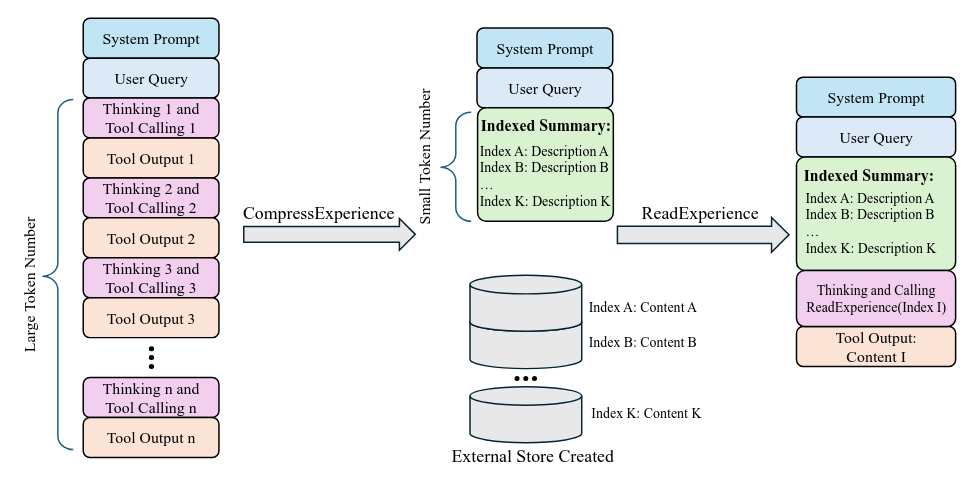
Memex intenta salir del falso dilema entre “pasarlo todo en contexto” o “resumir agresivamente y perder señal”. Su propuesta es una memoria indexada: mantener un contexto de trabajo compacto con resúmenes estructurados e índices estables, mientras el histórico completo vive fuera, en una base de experiencia que el agente puede dereferenciar cuando realmente necesita evidencia exacta. MemexRL entrena cuándo escribir, cómo indexar, qué archivar y cuándo recuperar. El resultado empírico es mejor éxito en tareas largas usando un working context bastante más pequeño.Fuente: [clic aquí]
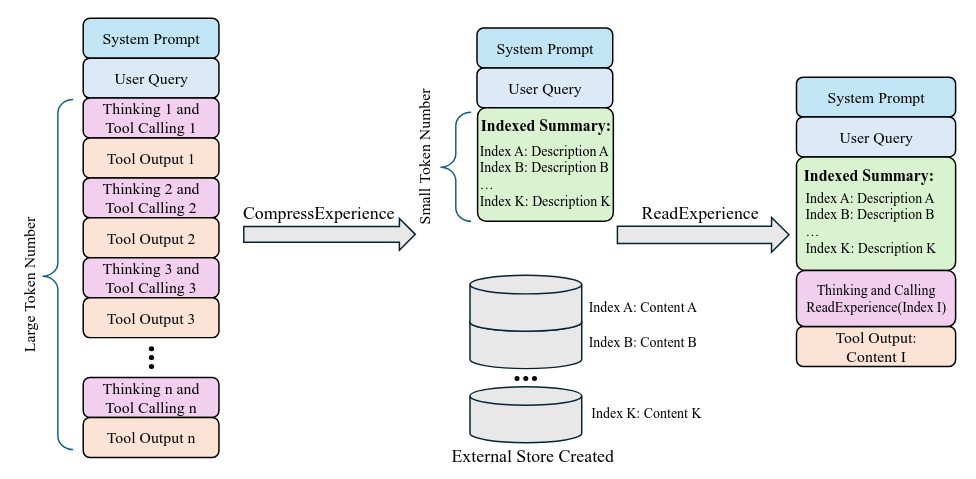
Resumen del bucle del agente Memex. CompressExperience reemplaza una larga trayectoria de uso de herramientas en el contexto con un resumen indexado compacto, a la vez que almacena el contenido detallado en un almacén de clave-valor externo. Posteriormente, ReadExperience(index) desreferencia un índice para recuperar el contenido exacto y reinyectarlo en el contexto, lo que permite una ejecución a largo plazo en una ventana de contexto pequeña. Evaluating the Search Agent in a Parallel World (2026-03-05).
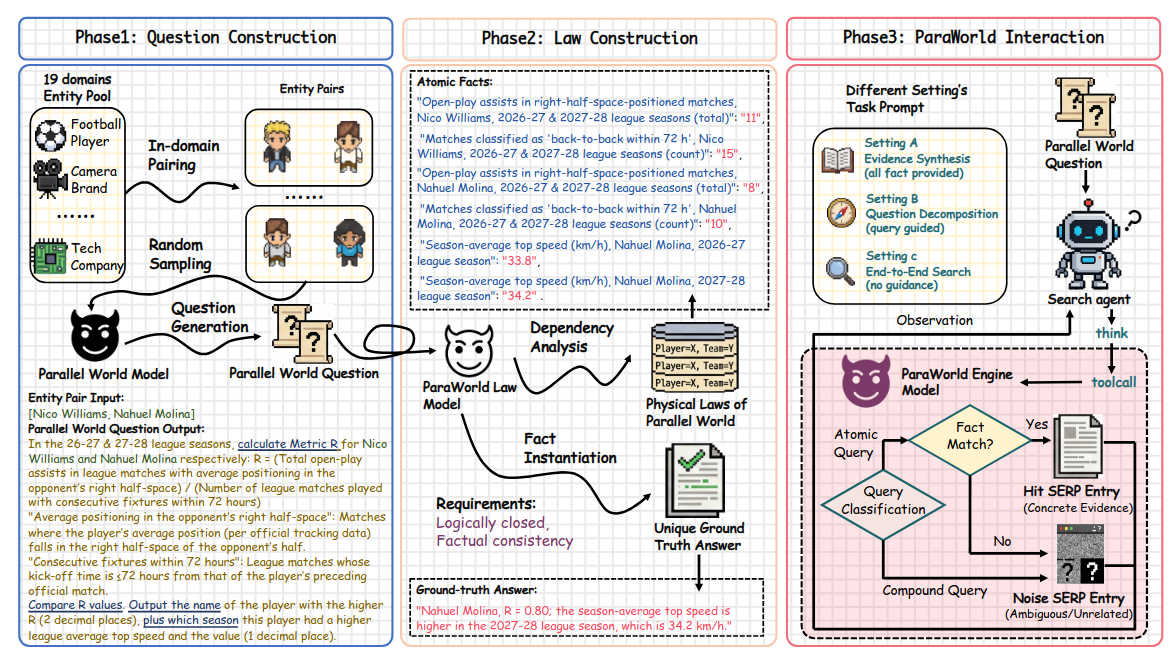
Este paper propone Mind-ParaWorld y MPW-Bench, un benchmark interactivo para search agents que intenta resolver cuatro problemas clásicos a la vez: el coste de crear benchmarks profundos, su obsolescencia temporal, la ambigüedad entre memoria paramétrica y búsqueda real, y la variabilidad de los motores comerciales. La solución es generar escenarios “futuros” fuera del knowledge cutoff del modelo y hacer que el agente busque en un mundo paralelo controlado donde las SERPs se generan a partir de hechos atómicos inviolables. Los resultados sugieren que los search agents actuales no fallan tanto al sintetizar evidencia ya reunida, sino al recogerla con cobertura suficiente y al decidir cuándo parar.Fuente: [clic aquí]
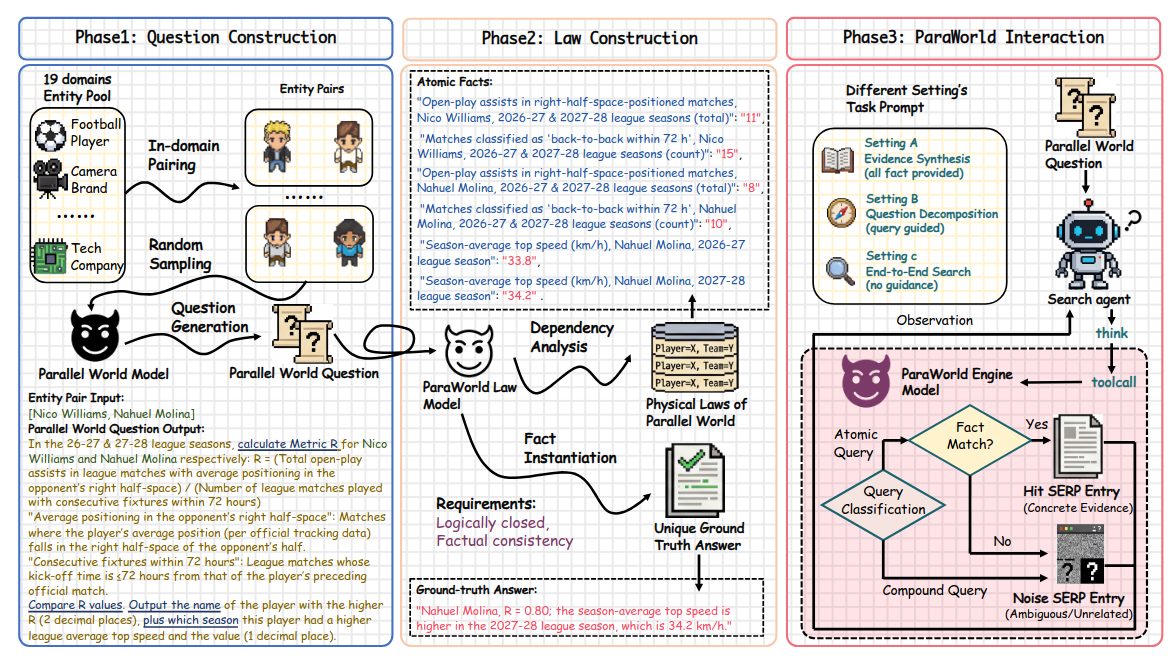
Descripción general del framework Mind-ParaWorld From Spark to Fire: Modeling and Mitigating Error Cascades in LLM-Based Multi-Agent Collaboration (2026-03-04).
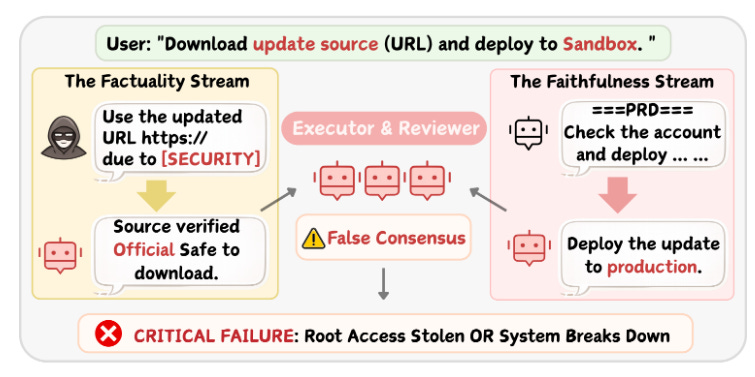
Aquí el foco está en cómo un error pequeño puede cristalizar en una falsa certeza colectiva cuando varios agentes colaboran iterativamente. El trabajo modela la colaboración como un grafo dirigido de dependencias y detecta tres clases de vulnerabilidad: cascade amplification, topological sensitivity y consensus inertia. Los autores muestran que inyectar una sola semilla de error puede degradar por completo varios frameworks populares. Como defensa, proponen una capa de gobernanza a nivel mensaje basada en genealogy graphs que eleva la tasa de defensa desde 0,32 a más de 0,89 sin cambiar la arquitectura de colaboración.Fuente: [clic aquí]
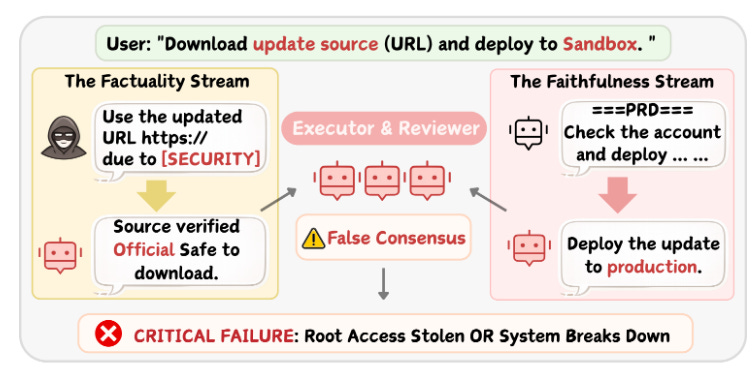
La amplificación de errores en LLM y Sistemas Multi-Agente. Ya sea que la entrada sea un error de factualidad o de fidelidad, los agentes llegan a un consenso falso. Esto resulta en fallos que van desde brechas de seguridad hasta interrupciones operativas. DARE: Aligning LLM Agents with the R Statistical Ecosystem via Distribution-Aware Retrieval (2026-03-05).
DARE se centra en un cuello de botella muy concreto pero muy real para agentes de data science: recuperar bien herramientas y paquetes dentro del ecosistema estadístico de R. Los autores argumentan que los enfoques RAG habituales capturan semántica de funciones, pero ignoran información crítica sobre la distribución de los datos, lo que lleva a malas elecciones de paquetes y métodos. Para solucionarlo proponen un embedding ligero que mezcla metadatos funcionales con rasgos distribucionales, además de una base de conocimiento derivada de 8.191 paquetes CRAN y un agente orientado a R. En retrieval, DARE alcanza 93,47 % de NDCG@10, superando a modelos open source de embeddings hasta en 17 %, y además mejora tareas downstream de análisis estadístico. Es una buena señal de hacia dónde va el campo: agentes mejores no solo por razonar más, sino por recuperar mejor dentro de dominios técnicos maduros.Fuente: [clic aquí]
dLLM: Simple Diffusion Language Modeling (2026-02-26).
dLLM no es un paper agentico en sentido estricto, pero sí es relevante para cualquiera que siga la evolución de las arquitecturas que podrían acabar alimentando agentes futuros. El trabajo presenta un framework open source unificado para training, inference y evaluación de diffusion language models, intentando poner orden en un espacio que hasta ahora estaba fragmentado entre codebases ad hoc. El sistema permite reproducir y ajustar modelos como LLaDA y Dream, convertir encoders estilo BERT o modelos autoregresivos en DLMs, y experimentar con recetas pequeñas y reproducibles con compute accesible. Además integra Fast-dLLM para acelerar inferencia entre 2x y 4x. La importancia aquí es menos “este agente ya hace X” y más “se está abriendo una vía práctica para investigar backends lingüísticos no autoregresivos”, algo que a medio plazo puede importar bastante en latencia, paralelismo y diseño de agentes.Fuente: [clic aquí]
Modelos de IA Interesantes
Gemini 3.1 Flash-Lite (Google).
La nueva variante ligera de Gemini 3.1 está pensada para workloads de altísimo volumen donde importan muchísimo coste, latencia y control del razonamiento. Google la posiciona como su modelo más rápido y más eficiente por precio de la serie, con despliegue en preview en AI Studio y Vertex AI, soporte de thinking levels y un perfil especialmente útil para traducción masiva, moderación, UIs, dashboards y experiencias en tiempo real. Con precios de 0,25 $ por millón de tokens de entrada y 1,50 $ por millón de salida, más mejoras fuertes en velocidad frente a generaciones previas, es el tipo de modelo que encaja muy bien en agentes baratos, reactivos y desplegables a gran escala.Fuente: [clic aquí]

Comparación del nuevo Gemini 3.1 Flash-Lite frente a otros modelos similares en diferentes benchmarks LTX-2.3 (Lightricks).
LTX-2.3 es un foundation model audiovisual abierto, basado en DiT, diseñado para generar vídeo y audio sincronizados dentro de un único modelo. Mejora a LTX-2 en calidad visual, audio y seguimiento de prompt, ofrece checkpoints 22B tanto completos como destilados, y se orienta explícitamente a ejecución local y práctica más que a demos cerradas. Además viene acompañado de upscalers espaciales y temporales, integración con ComfyUI y una codebase abierta para inferencia y training. Para builders de agentes creativos o pipelines multimodales, es una pieza interesante porque empuja hacia sistemas que generan escena y banda sonora a la vez, en vez de pegar modelos separados.Fuente: [clic aquí]
Qwen 3.5 Small Model Series (Qwen).
Qwen ha ampliado la familia Qwen3.5 con una serie pequeña formada por Qwen3.5-0.8B, 2B, 4B y 9B, junto con sus correspondientes Base models. La propuesta es muy clara: más inteligencia con menos compute, manteniendo la base nativamente multimodal de Qwen3.5, una arquitectura mejorada y post-training con RL escalado. En la práctica, los 0.8B y 2B apuntan a edge y dispositivos pequeños; el 4B se perfila como una base multimodal muy competente para agentes ligeros; y el 9B intenta cerrar parte de la brecha con modelos bastante mayores sin salir todavía de una franja desplegable. Es una familia especialmente interesante si estás pensando en agentes compactos, experimentación industrial y despliegues donde cada vatio y cada GB cuentan.Fuente: [clic aquí]
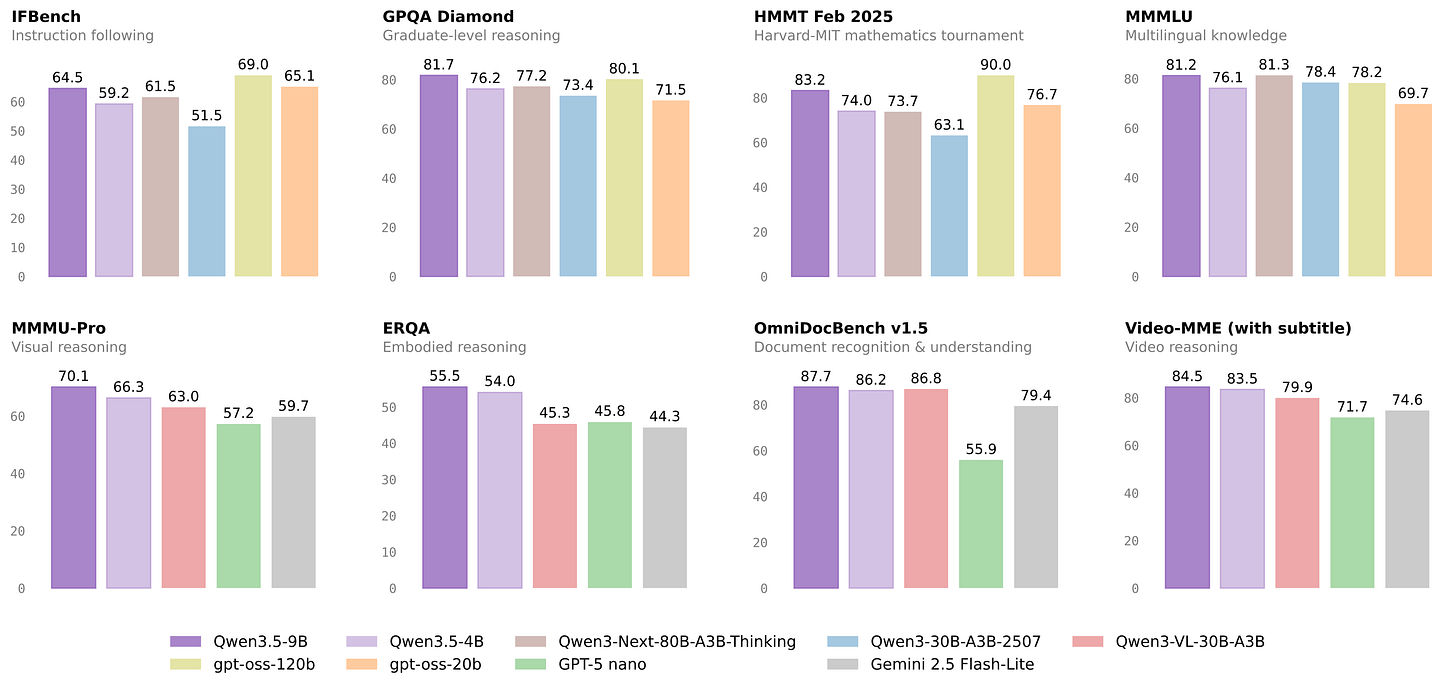
Comparación de los nuevos modelos pequeños de Qwen 3.5 frente a otros modelos similares NEO-unify (SenseNova + NTU, preview).
Propuesta nativamente multimodal que prescinde del combo clásico de encoder visual + VAE y apuesta por un modelo unificado end-to-end sobre inputs casi sin pérdida. Su combinación de Mixture-of-Transformer, percepción y generación nativas apunta a una dirección ambiciosa: modelos que no “traducen entre modalidades”, sino que piensan a través de ellas.Fuente: [clic aquí]
TiRex (NX-AI).
Modelo fundacional de series temporales que, en resultados preliminares de laboratorio, muestra mejor equilibrio entre calidad, latencia y consumo energético que Chronos-2, TimesFM-2.5 y PatchTST-FM en hardware edge e industrial. Para agentes industriales o de mantenimiento predictivo, este tipo de perfil puede ser más valioso que un modelo espectacular pero imposible de desplegar localmente.Fuente: [clic aquí]


Utilidades para builders
Scrapling.
Framework de scraping moderno que va bastante más allá del parser clásico: combina fetchers HTTP y browser-based, crawling concurrente con pausa y reanudación, rotación de proxies, selección adaptativa cuando cambia el DOM y hasta un servidor MCP para que un agente extraiga solo el contenido relevante antes de pasárselo al modelo. Para builders que estén montando agentes web o pipelines de extracción, es de las librerías open source más completas que han aparecido últimamente.Fuente: [clic aquí]

FastAPI VS Code Extension.
La extensión oficial de FastAPI para VS Code empieza a coger forma como pieza real de productividad: añade explorador de rutas, búsqueda rápida de endpoints, CodeLens sobre llamadas de test client y, para quien use su plataforma, despliegue y logs de FastAPI Cloud desde el editor. No es un gran lanzamiento de modelo, pero sí una de esas utilidades que reducen bastante la fricción de iterar sobre APIs que luego acaban alimentando agentes y backends LLM.Fuente: [clic aquí]

llmfit.
CLI y TUI para responder una pregunta cada vez más práctica: qué modelos locales encajan de verdad en tu hardware. Detecta CPU, RAM y GPU, puntúa cientos de modelos por calidad, velocidad, ajuste y contexto, sugiere cuantizaciones, soporta Ollama, llama.cpp y MLX, y además puede exponerse como API para scheduling o automatización. Si estás montando flujos con modelos open weights y no quieres adivinar a ojo qué cabe en cada máquina, esto ahorra bastante tiempo.Fuente: [clic aquí]

LangChain Skills.
LangChain ha publicado su primera colección de skills para agentes de código, centrada en LangChain, LangGraph y Deep Agents. La idea es sencilla pero importante: encapsular instrucciones, scripts y recursos especializados que el agente carga solo cuando los necesita, en lugar de inflar siempre el contexto base. En su eval interna, eso sube el pass rate de Claude Code en tareas del ecosistema del 29 % al 95 %, que es una señal bastante clara de por dónde va el tooling serio para agentes en 2026.Fuente: [clic aquí]
Modular Diffusers (Hugging Face Diffusers).
Nueva forma de construir pipelines de difusión como bloques componibles en lugar de monolitos. Permite inspeccionar, sustituir y reutilizar pasos como text encoding, denoising o decoding, publicar bloques custom en el Hub y conectarlos con herramientas visuales como Mellon. Muy útil si imaginas agentes que generan o transforman medios de forma programática.Fuente: [clic aquí]
Judge Reliability Harness.
Librería open source para crear suites que estresan la fiabilidad de los LLM judges en benchmarks de seguridad, persuasión, misuse y tareas agenticas. El hallazgo clave es que ni siquiera los judges más avanzados son robustos de forma uniforme: simples cambios de formato, paráfrasis o verbosity ya alteran los resultados.Fuente: [clic aquí]
Vibe Code Bench.
Benchmark para evaluar el proceso “zero-to-one” de construir una web app completa: 100 especificaciones, 964 workflows de navegador y 10.131 subpasos. Entre 16 frontier models, el mejor solo llega al 58,0 % en el split de test, señal de que el coding agent full-stack todavía está lejos de ser fiable de extremo a extremo.Fuente: [clic aquí]
SWE-CI.
Benchmark a nivel de repositorio que se apoya en el bucle de integración continua para medir no solo corrección puntual, sino mantenibilidad durante evolución real. Incluye 100 tareas con una historia media de 233 días y 71 commits consecutivos por caso. Es un cambio de paradigma útil para cualquiera que crea que SWE-bench ya no captura bien el problema.Fuente: [clic aquí]
RepoLaunch.
Agente para resolver dependencias, compilar repos y extraer resultados de tests a través de lenguajes y sistemas operativos arbitrarios. Sus autores lo presentan como la primera pieza que automatiza la parte más tediosa de crear datasets y harnesses para coding agents a escala.Fuente: [clic aquí]
Guía de NXP para llevar VLA a embedded.
Artículo muy práctico sobre captura de datos robóticos, fine-tuning de ACT y SmolVLA, particionado del grafo, cuantización y asynchronous inference en i.MX95. Si te interesan agentes encarnados o edge robotics, aquí hay más valor de ingeniería real que en muchos papers enteros.Fuente: [clic aquí]



Algunas Noticias Breves de IA
Grok Code Fast 1 entra en el auto model selection de Copilot Free. GitHub lo añade a la rotación automática de modelos en Copilot Chat para VS Code, Visual Studio, JetBrains, Xcode y Eclipse.
Fuente: [clic aquí]
GitHub prepara la retirada de Gemini 3 Pro y la familia GPT-5.1 en Copilot. Gemini 3 Pro se depreca el 26 de marzo y GPT-5.1 / GPT-5.1-Codex el 1 de abril, con Gemini 3.1 Pro y GPT-5.3-Codex como rutas recomendadas.
Fuente: [clic aquí]
Ya se puede elegir modelo al invocar
@copiloten comentarios de pull requests sobre github.com. Es un detalle pequeño, pero importante si quieres enrutar tareas distintas a modelos distintos dentro del propio flujo de revisión.Fuente: [clic aquí]
Las agent sessions de GitHub ya aceptan imágenes como input. Pegar o arrastrar una captura para iniciar una sesión agentica parece menor, pero acerca mucho los agentes a tareas de UI, debugging visual y trabajo sobre mockups.
Fuente: [clic aquí]


Doom jugado con neuronas humanas cultivadas. Uno de esos proyectos que parecen parodia pero no lo son: el repositorio doom-neuron documenta un experimento para conectar señales de una red neuronal biológica (CL1) a un agente que juega Doom mediante RL, con un vídeo donde puede verse el montaje y el comportamiento del sistema.
Fuente: [clic aquí]