En Resumen: lo imprescindible
OpenAI empuja el stack de agentes hacia producción: Responses API suma “computer environment” (shell + contenedores + compaction + skills), publica guías/datasets para resistir prompt injection (IH‑Challenge) y refuerza evaluación/red‑teaming con la adquisición de Promptfoo.
GitHub consolida “Copilot como plataforma agentica”: en JetBrains (GA) llegan custom agents, sub-agents y plan agent, con hooks en preview y más gobernanza (auto-approve de MCP,
AGENTS.md/CLAUDE.md, thinking/context); además, Auto model selection (GA) enruta modelos con trazabilidad/coste, el code review baja a GitHub CLI y Copilot web mejora exploración de repos con referencias.Meta compra Moltbook, una red social “solo de bots”: una plataforma tipo Reddit donde agentes publican y debaten sin humanos; se integrará en Meta Superintelligence Labs y reabre el debate sobre guardrails (estafas e inyecciones de instrucciones).
Anthropic acelera enterprise de Claude: $100M para el Partner Network (certificación + kit de modernización) y lanzamiento de The Anthropic Institute como capa institucional de investigación y gobernanza.
AWS cierra seguridad y operación para agentes: Policy en Bedrock AgentCore aplica enforcement con Cedar (default-deny) y CloudWatch añade métricas server-side (TTFT y EstimatedTPMQuotaUsage) para observabilidad y planificación.
Hugging Face añade Storage Buckets “mutables”: un storage S3-like sobre Xet para artefactos que cambian constantemente (checkpoints, logs y memoria/trazas de agentes) con CLI/SDK y deduplicación.
Ecosistema e investigación: Android Bench y BullshitBench empujan evaluación más específica, “oficinas” como OpenClaw Office y Pixel Agents hacen visible el trabajo de los agentes, y arXiv deja papers sobre seguridad de agentes, MADQA y patologías de RL/judges.
Noticias Recientes
OpenAI
OpenAI empuja la ingeniería “agent-first”: ejecución, compaction y defensa contra prompt injection
OpenAI publicó una secuencia muy coherente para builders: si quieres agentes que hagan trabajo real, necesitas entornos de ejecución, jerarquía de instrucciones y controles cuando el agente toca el mundo externo. En ese marco, la Responses API incorpora un “computer environment” con shell tool y un hosted container workspace (filesystem, opción de datos estructurados tipo SQLite y networking bajo política) para cerrar el loop herramienta→resultado→siguiente acción; además, ponen el foco en concurrencia, límites de output, compaction nativa para sesiones largas y skills como bundles versionados reutilizables.
En paralelo, tratan la prompt injection como social engineering: no basta con clasificar texto como “malicioso”, hay que limitar el impacto incluso si el agente es manipulado, usando un framing tipo source–sink y confirmación/bloqueo cuando el agente intenta navegar o transmitir información sensible a terceros. También publican IH‑Challenge para entrenar Instruction hierarchy (System > developer > user > tool) y mejorar la resolución de conflictos (incluyendo outputs de herramientas), y anuncian la adquisición de Promptfoo para integrar evaluación, seguridad y red‑teaming en OpenAI Frontier manteniendo su CLI open source como base.
Fuente: [clic aquí] [aquí] [aquí] [aquí]
GitHub
Copilot refuerza su capa agentica en JetBrains (y se extiende a CLI y web)
GitHub ha empujado Copilot en JetBrains hacia un modo más “agente”, pero con un detalle clave: más capacidad y más gobernanza a la vez. En GA aterrizan los custom agents, sub-agents y el plan agent, mientras que en preview llegan los agent hooks (con
.github/hooks/+hooks.json) para automatizar puntos de la sesión.
En la capa de control se consolidan el auto-approve de MCP, ficheros de instruccionesAGENTS.md/CLAUDE.md, panel de thinking e indicador de ventana de contexto; además, Auto model selection (GA) enruta modelos por rendimiento/disponibilidad manteniendo trazabilidad (qué modelo respondió) y detalle de coste (multiplicadores + descuento en Auto). El flujo se extiende fuera del IDE con code review desde GitHub CLI y con Copilot web ganando exploración de repos vía file explorer y referencias.
Fuente: [clic aquí] [aquí] [aquí] [aquí]

Anthropic
Anthropic refuerza el ecosistema enterprise alrededor de Claude
Anthropic encadena anuncios que apuntan a un objetivo: acelerar despliegues en empresas (partners + certificación) y a la vez crear una capa “institucional” para estudiar impactos y gobernanza de IA potente.
En concreto, compromete $100M para la Claude Partner Network (training, soporte técnico y joint market development), lanza la certificación “Claude Certified Architect, Foundations” junto a un starter kit de code modernization, y crea The Anthropic Institute (dirigido por Jack Clark) para agrupar y ampliar Frontier Red Team, Societal Impacts y Economic Research, además de reforzar Public Policy. Como señal de expansión enterprise, abren oficina en Sydney para servir Australia/NZ.
Fuente: [clic aquí] [aquí] [aquí]
Amazon y AWS
AWS se centra en dos pilares para agentes en producción: seguridad determinista y operación medible
AWS está cerrando dos gaps típicos de agentes en producción: policy enforcement determinista y observabilidad real. En AgentCore, Policy hace que el Gateway evalúe cada tool-call con Cedar bajo una postura default-deny (donde
forbidgana apermit), con opción de generar políticas desde lenguaje natural y probarlas en modoLOG_ONLY.
En operación, CloudWatch añade métricas server-side de TimeToFirstToken y EstimatedTPMQuotaUsage (incluye burndown multipliers) para SLAs, alarmas y planificación de cuota; y la guía “Operationalizing Agentic AI (Part 1)” aterriza cómo definir jobs, herramientas seguras, éxito observable y planes de fallo.
Fuente: [clic aquí] [aquí] [aquí]
Gemini Embedding 2: embeddings multimodales en un espacio unificado (public preview)
Google DeepMind presentó Gemini Embedding 2, su primer modelo de embeddings nativamente multimodal (texto, imágenes, vídeo, audio y documentos) que mapea todo a un único espacio vectorial; está disponible en public preview vía Gemini API y Vertex AI.
La multimodalidad es “real” (texto hasta 8192 tokens, hasta 6 imágenes PNG/JPEG, vídeo hasta 120 s, audio nativo y PDFs de hasta 6 páginas, además de input intercalado como imagen+texto), con soporte de +100 idiomas para retrieval/clasificación y RAG sin tener que traducir cada modalidad a texto primero. También permiten dimensión flexible con Matryoshka Representation Learning, partiendo del default 3072 y recomendando 3072/1536/768 según coste vs calidad.
Fuente: [clic aquí]
Meta
Meta compra Moltbook, una red social donde solo hablan bots de inteligencia artificial
Meta ha comprado Moltbook, una plataforma experimental en la que los “usuarios” son agentes de IA que publican, comentan y votan contenido, apuntando a un futuro donde también existan espacios sociales nativos para agentes.
La pieza se describe como una especie de Reddit para agentes autónomos, con miles de bots generando posts y conversaciones sin intervención humana directa; Meta la integrará en Meta Superintelligence Labs y no ha revelado el precio. El artículo subraya riesgos por falta de guardrails básicos y su potencial como vector de ataque, incluyendo estafas o inyecciones de instrucciones.
Fuente: [clic aquí]

NVIDIA
Nemotron-3-Super-120B-A12B (NVFP4): modelo “agentic-first” con hasta 1M tokens
NVIDIA publicó Nemotron-3-Super-120B-A12B-NVFP4, un LLM de pesos abiertos orientado a workflows agenticos, tool use y razonamiento de largo contexto.
El modelo usa un LatentMoE híbrido (Mamba-2 + MoE + atención) con Multi-Token Prediction; declara 120B parámetros totales (12B activos) y cuantización NVFP4, con contexto de hasta 1M tokens y “reasoning mode” configurable en el chat template (enable_thinking=True/False). Para operarlo, recomiendan un mínimo de 1× B200-80GB (o DGX Spark) y distribuyen bajo la licencia “NVIDIA Nemotron Open Model License”.
Fuente: [clic aquí]

Desde la Investigación (arXiv, benchmarks y seguridad)
Security Considerations for Artificial Intelligence Agents (2026-03-12).
Un repaso bastante completo a por qué los agentes cambian el modelo mental de seguridad: se rompe la separación código/datos, aparecen fronteras de autoridad difusas y el comportamiento se vuelve menos predecible. El paper mapea superficies de ataque en tools, conectores, hosting y coordinación multi-agente, con énfasis en indirect prompt injection, confused deputy y fallos en cascada. La conclusión es una defensa en capas donde, para acciones de alto impacto, la pieza “dura” tiende a ser policy enforcement determinista (separado del razonamiento del LLM).Fuente: [clic aquí]
Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections (MADQA) (2026-03-12).
MADQA propone un benchmark de 2.250 preguntas humanas apoyadas en 800 PDFs heterogéneos y una evaluación que mide el trade-off accuracy–effort. El resultado es incómodo: los mejores agentes pueden igualar a humanos en accuracy, pero lo hacen con búsqueda más bruta y peor planificación, quedándose a ~20% del rendimiento “oracle” y cayendo en bucles improductivos.Fuente: [clic aquí]
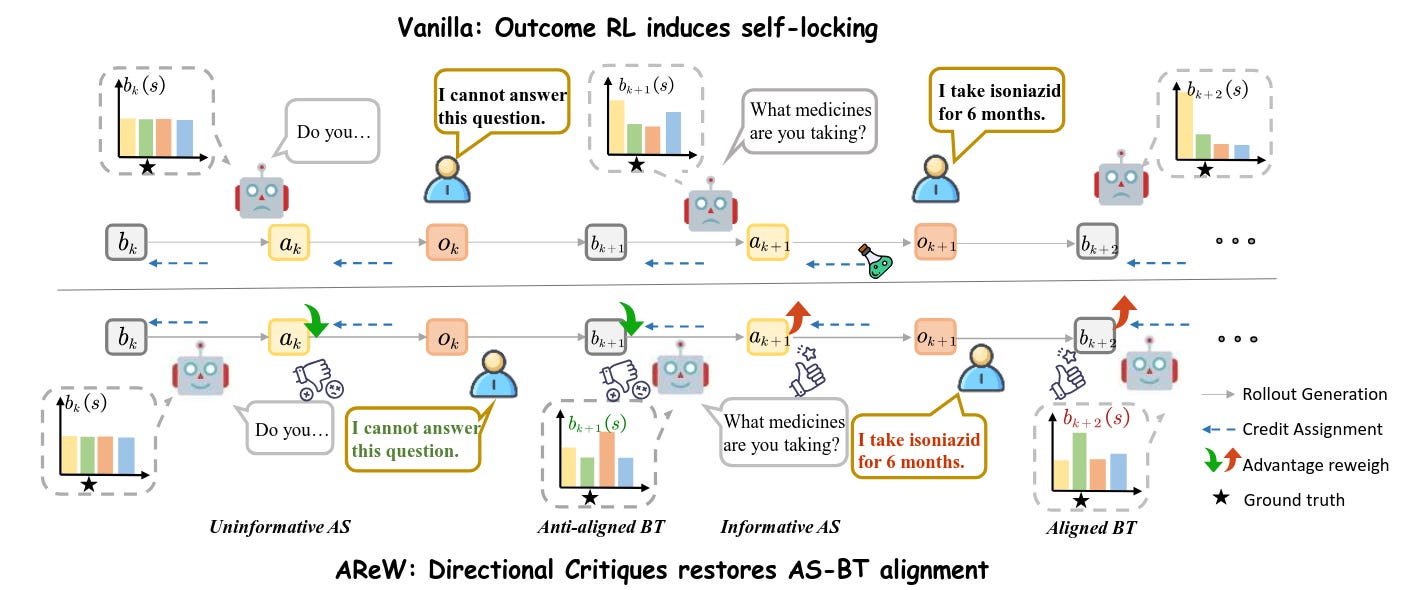
On Information Self-Locking in Reinforcement Learning for Active Reasoning of LLM agents (2026-03-12).
En tareas de active reasoning (preguntar para obtener información relevante), estos autores observan “self-locking”: el agente deja de hacer preguntas informativas y no internaliza bien lo ya obtenido. Descomponen el problema en selección de acción (qué preguntar) y belief tracking (cómo actualizar creencias) y proponen reinyectar señal de aprendizaje con críticas direccionales fáciles de obtener, reportando mejoras de hasta 60%.Fuente: [clic aquí]
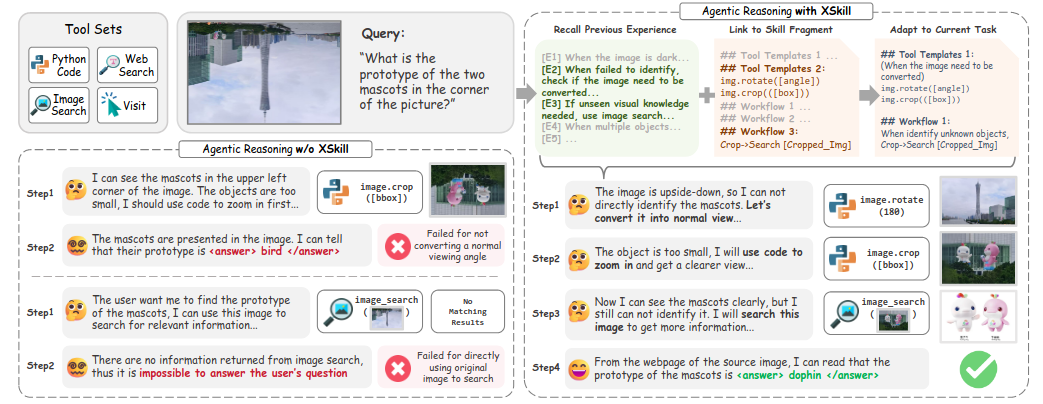
XSkill: Continual Learning from Experience and Skills in Multimodal Agents (2026-03-12).
XSkill plantea un bucle de aprendizaje continuo “sin tocar parámetros” a partir de trayectorias previas: por un lado extrae experiencias (guía a nivel acción) y por otro skills (guía a nivel tarea/planificación), ambos anclados en observaciones visuales. Destila conocimiento de rollouts múltiples, lo recupera y adapta al contexto y retroalimenta el sistema con el historial de uso.Fuente: [clic aquí]
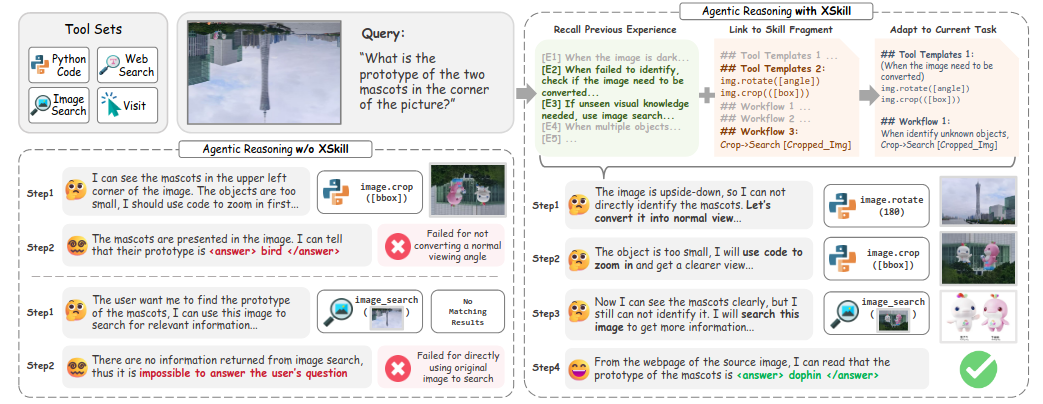
Comparación de Trayectorias de Razonamiento en una Tarea Multimodal con y sin XSKILL. Examining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-Training (2026-03-12).
Un aviso para cualquiera que esté alineando agentes con “judges”: en dominios no verificables, los judges pueden inducir reward hacking. El estudio encuentra que judges con razonamiento pueden entrenar políticas que puntúan muy alto… en parte aprendiendo a generar salidas adversarias que engañan a otros judges, y que además pueden verse bien en benchmarks populares. Es una llamada a evaluar robustez de jueces y a diseñar señales de recompensa menos hackeables.Fuente: [clic aquí]
Keep the Tokens Flowing: Lessons from 16 Open-Source RL Libraries (2026-03-10).
Hugging Face hace una autopsia útil al verdadero cuello de botella del post-training moderno: la generación (rollouts) domina el wall-clock y obliga a arquitecturas asíncronas (inferencia y training en pools separados, buffers, weight sync). El artículo compara 16 librerías open source en siete ejes (orquestación, buffers, staleness, weight sync, rollouts parciales, LoRA, backend distribuido) y aterriza decisiones de diseño para un futuro trainer asíncrono en TRL.Fuente: [clic aquí]
Modelos de IA Interesantes
Granite 4.0 1B Speech (IBM).
IBM publica Granite 4.0 1B Speech, un modelo compacto orientado a ASR (transcripción) y AST (traducción de voz bidireccional) para entornos con recursos limitados. Reduce parámetros respecto a su predecesor, amplía idiomas (inglés, francés, alemán, español, portugués y japonés) y presume de rendimiento en benchmarks con soporte nativo en Transformers y vLLM.Fuente: [clic aquí]

Comparativa del nuevo granite-4.0-1b-speech frente a modelos de voz similares (menor error es mejor). Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled (Jackrong).
Un fine-tune sobre Qwen3.5-27B que destila cadenas de razonamiento de Claude-4.6 Opus para adoptar un “scaffold” de pensamiento más estructurado y eficiente (menos repetición). Enfatiza formato estricto con<think>...</think>y se posiciona como modelo práctico para tareas de análisis, coding y agentes locales (licencia Apache-2.0).Fuente: [clic aquí]
Qwen3.5-9B-Uncensored-HauhauCS-Aggressive (HauhauCS).
Versión “uncensored” basada en Qwen3.5-9B que afirma haber eliminado refusals (0/465). Se distribuye como GGUF y mantiene specs del base: hasta 262K de contexto (extensible a 1M con YaRN) y soporte multimodal conmmproj. Ojo: al no rechazar prompts, aumenta el riesgo de misuse/safety (licencia Apache-2.0).Fuente: [clic aquí]
Fish Audio S2 Pro (fishaudio).
Modelo TTS con control fino “inline” (instrucciones dentro del texto vía[tag]) y arquitectura Dual‑AR (Slow AR 4B + Fast AR 400M) sobre codec RVQ. Soporta 80+ idiomas y se enfoca en inferencia streaming de baja latencia; licencia de investigación (uso no comercial gratis, comercial requiere licencia aparte).Fuente: [clic aquí]

Sarvam-105B (Sarvam AI).
MoE de 105B parámetros (10.3B activos) optimizado para reasoning, matemáticas, coding y tareas agenticas, con foco especial en rendimiento en 22 lenguas indias. Se publica bajo Apache-2.0 y viene con instrucciones de inferencia para runtimes comunes (vLLM/SGLang).Fuente: [clic aquí]


Utilidades para builders
Storage Buckets en el Hugging Face Hub.
Una pieza muy práctica para agentes y training: Buckets son contenedores de almacenamiento no versionado (S3-like) pensados para artefactos “en movimiento” (checkpoints, shards procesados, logs, trazas y memoria de agentes). Al estar construidos sobre Xet (storage por chunks con deduplicación), prometen transferencias más rápidas y menos coste/espacio efectivo en entornos donde los ficheros se parecen mucho entre sí. Incluyen CLI (hf buckets ...), SDK enhuggingface_huby acceso tipo filesystem vía fsspec (hf://...).Fuente: [clic aquí]

Ulysses Sequence Parallelism: training con contextos enormes.
Guía técnica para entrenar con secuencias larguísimas usando Ulysses SP (DeepSpeed): divide la secuencia y reparte cabezas de atención, usando dos all-to-all por capa para hacer viable el cómputo. El post recorre la integración en Accelerate/Transformers/TRL y muestra benchmarks donde SP reduce memoria por GPU y habilita longitudes de contexto muy por encima de lo típico (p. ej. 32K–96K en 4× H100, según configuración).Fuente: [clic aquí]

Ulysses divide las secuencias de entrada a lo largo de la dimensión de la secuencia y utiliza la comunicación all-to-all para intercambiar pares clave-valor, lo que permite que cada GPU calcule un subconjunto de attention heads. Copilot Cowork (Microsoft 365).
Convierte una petición en un plan ejecutable en Microsoft 365, con puntos de control y aprobación antes de aplicar cambios. Está en Research Preview y llegará más ampliamente vía Frontier a finales de marzo de 2026.Fuente: [clic aquí]

AlphaEarth Foundations Satellite Embeddings (2025).
Dataset anual global de embeddings satelitales (64 dimensiones por píxel de 10 m) para detectar cambios interanuales sin procesar imágenes crudas; disponible en Earth Engine Data Catalog y en Google Cloud Storage.Fuente: [clic aquí]
RabbitLLM: inference por streaming de capas.
Para correr LLMs 70B+ con VRAM limitada: parte el checkpoint y hace streaming capa a capa (con prefetch), con compresión 4/8-bit opcional; “tested” en Qwen2/Qwen3.Fuente: [clic aquí]
Page Agent (Alibaba).
Agente que vive dentro de tu web: manipulación del DOM en texto (sin screenshots), BYO LLM, UI con human-in-the-loop y (opcional) extensión de Chrome para tareas multi-página.Fuente: [clic aquí][aquí]
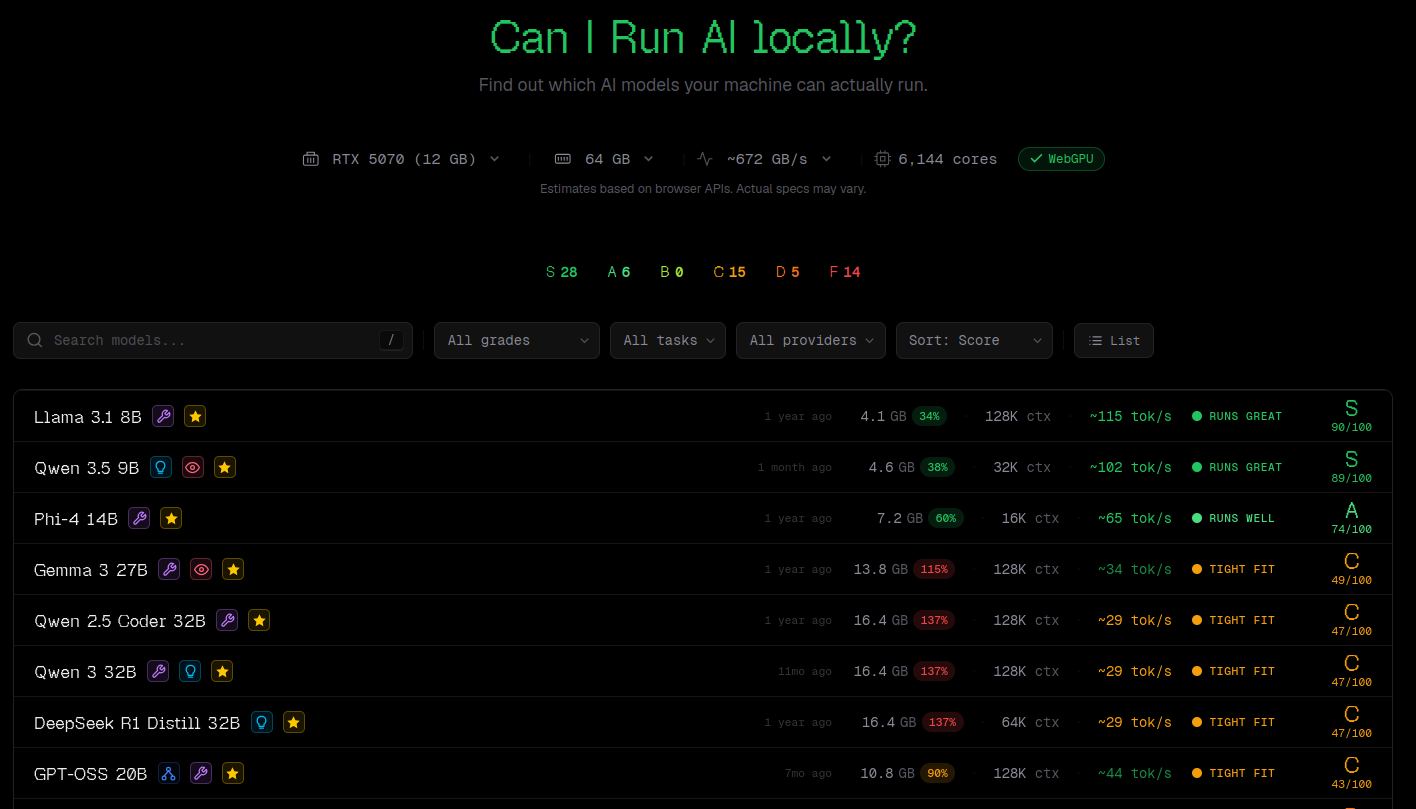
CanIRun.ai.
Web que calcula en tu navegador qué modelos puedes correr localmente y a qué velocidad, detectando GPU/CPU/RAM (sin enviar datos a servidor).Fuente: [clic aquí]
RAGFlow.
Motor open-source de RAG que combina pipeline de ingesta/parsing y chunking con capacidades de agente y citas trazables para respuestas más “grounded”.Fuente: [clic aquí]
Qwen-Agent.
Framework para construir aplicaciones/agents con uso de herramientas, planificación y memoria (con extras para RAG, Code Interpreter y MCP) y ejemplos listos para probar.Fuente: [clic aquí]

Cloudflare Browser Rendering: endpoint
/crawl.
API REST para lanzar crawls asíncronos desde una URL y recuperar resultados en HTML/Markdown/JSON, con filtros include/exclude y respeto de robots.txt.Fuente: [clic aquí]
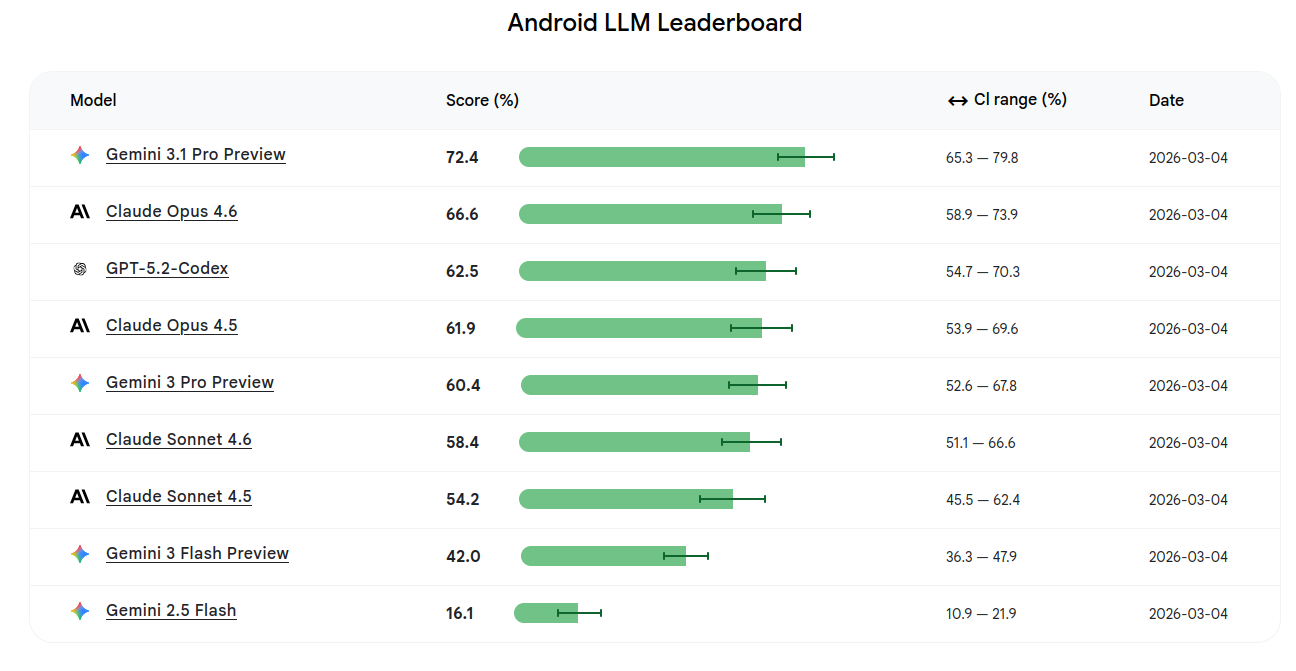
Android Bench (Android Developers).
Benchmark y leaderboard de LLMs para tareas de desarrollo Android, con metodología y repo para replicar los tests.Fuente: [clic aquí]
BullshitBench v2 (petergpt).
Benchmark open source para medir si un modelo hace pushback ante premisas absurdas (vs. “aceptar el nonsense”), con dataset, pipeline y viewer.Fuente: [clic aquí]

Bullshit Benchmark aplicado sobre un gran conjunto de modelos. Victoria aplastante para Claude.





Oficinas para agentes
OpenClaw Office (WW-AI-Lab).
Frontend de monitorización y gestión para OpenClaw (sistema multi-agente) que visualiza estado, tool calls y consumo de recursos como una “oficina” en tiempo real.Fuente: [clic aquí] [aquí]

OpenClaw Office con agentes interactuando en el entorno virtual 3D que simula una oficina Pixel Agents (pablodelucca).
Extensión de VS Code que convierte agentes en personajes de oficina pixel art para ver su actividad en tiempo real (p. ej., Claude Code) y visualizar sub-agentes como “compañeros” conectados.Fuente: [clic aquí][aquí]

Pixel Agents con agentes interactuando en un entorno virtual estilo pixel art dentro de la interfaz de VS Code


Algunas Noticias Breves de IA
España y Portugal estudian una candidatura conjunta para albergar una gigafactoría europea de IA: ambos Gobiernos firmaron un memorando en la XXXVI Cumbre hispanoportuguesa para explorar una candidatura ibérica; España ya trabaja en una propuesta con Mora la Nova (Tarragona) y San Fernando de Henares (Madrid) como sedes.
Fuente: [clic aquí]
“Multi-behavior brain upload” (demo) en una mosca simulada: Eon Systems publica un vídeo donde afirma haber acoplado una emulación cerebral basada en conectoma de Drosophila a un cuerpo físico simulado (MuJoCo) para cerrar el bucle sensorimotor y producir múltiples comportamientos desde la dinámica neuronal (no desde una política de RL).
Fuente: [clic aquí]

Emulación de las conexiones neuronales de la mosca, junto con su modelo interactuando en un entorno virtual dentro del ordenador.

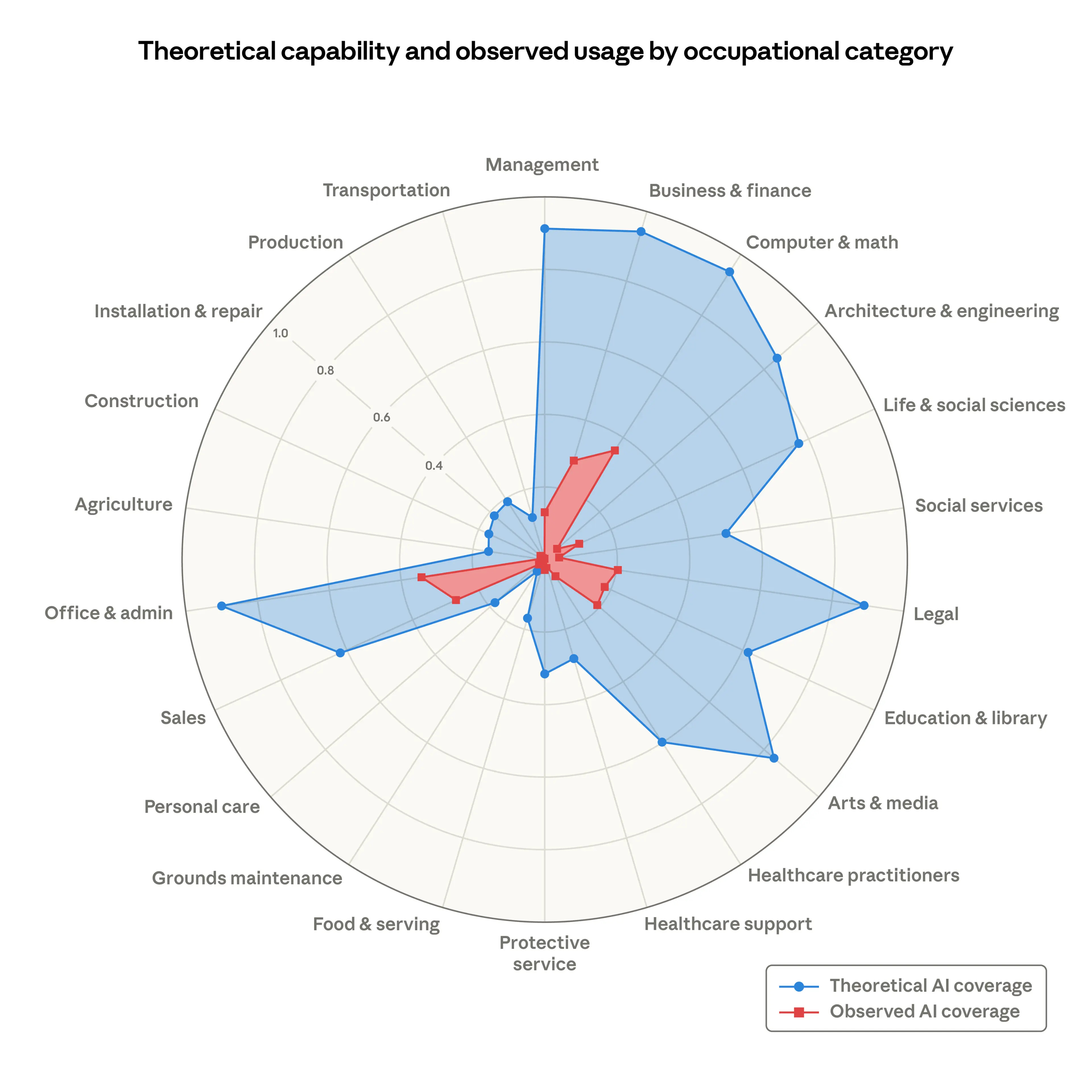
Anthropic propone “observed exposure” para medir impacto laboral con uso real de LLMs: combinan capacidad teórica + datos de uso (ponderando automatización y contexto laboral) y encuentran que la adopción aún cubre una fracción de lo posible; no observan un aumento sistemático de desempleo desde 2022, pero sí señales de menor contratación de jóvenes en ocupaciones más expuestas.
Fuente: [clic aquí]
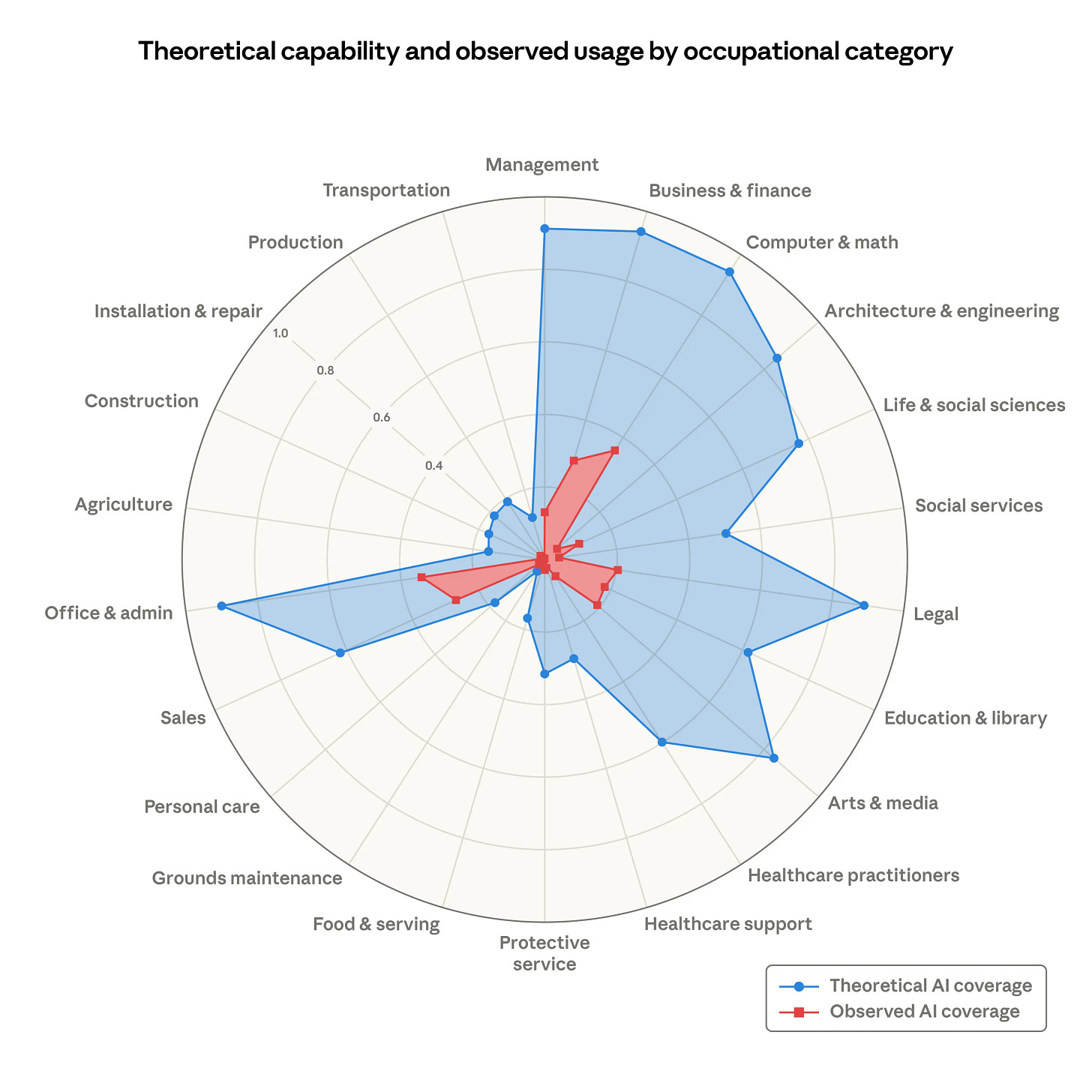
Capacidad teórica y exposición observada por categoría ocupacional. Porcentaje de tareas laborales que los LLM podrían realizar teóricamente (área azul) y la medida de cobertura laboral observada derivada de datos de uso (zona roja). Post-mortem: un agente ejecutó Terraform y borró la base de datos de producción: relato detallado de cómo perder el state y mezclar infra (más
auto-approve) llevó a eliminar RDS y snapshots, y qué guardrails aplicaron después (revisión humana, protecciones anti-borrado, backups fuera del ciclo de Terraform y tests de restauración).Fuente: [clic aquí]