

En Resumen: lo imprescindible
- OpenAI y Anthropic consolidan su papel institucional: OpenAI escala Education for Countries para integrar ChatGPT Edu y GPT‑5.2 en sistemas educativos nacionales y detalla un modelo de negocio ligado al “valor de la inteligencia”, mientras Anthropic publica la nueva constitución de Claude, refuerza su Long‑Term Benefit Trust con Tino Cuéllar y expande programas educativos con Teach For All.
- Nuevos backbones y modelos especializados: llegan GLM‑4.7‑Flash como MoE de 30B ligero pero puntero, Qwen3‑VL‑Embedding/Reranker para retrieval multimodal SOTA, Differential Transformer V2 como arquitectura base más estable, Waypoint‑1 para vídeo interactivo en tiempo real, Soprano‑1.1‑80M como TTS ultraligero on‑device y LightOnOCR‑2 como OCR rápido en la frontera de Pareto.
- Infraestructura, RL y tooling para builders: OpenAI detalla cómo lleva PostgreSQL al límite para servir a unos 800 millones de usuarios, Unsloth introduce GRPO long‑context que permite RL con contextos de hasta cientos de miles de tokens, SlimToolkit reduce imágenes Docker hasta 30×, emergen nuevas capas de datos (como el paisaje agrícola de Google Earth) y se recopilan hubs clave de datasets abiertos.
- Copilots, MCP‑Apps y agentes en la terminal: CopilotKit añade una infraestructura 100% open source de MCP‑Apps y el protocolo AG‑UI para mini‑apps interactivas dentro de tu copilot, Google libera Gemini CLI como herramienta oficial open source con system prompts visibles, y Ollama habilita usar Claude Code y el ecosistema Anthropic API sobre modelos locales y en la nube.
- Evaluación, memoria y marco regulatorio de la IA: benchmarks como AssetOpsBench y trabajos de investigación (DeepVerifier, ErrorMap/ErrorAtlas, DeepSurvey‑Bench, Aeon, Prometheus Mind) afinan cómo medimos agentes, verificación y memoria de largo horizonte, mientras a nivel de políticas España abre la consulta pública del “ómnibus” de IA y el ecosistema se mueve con anuncios como la compra de Astro por Cloudflare.
Noticias Recientes
OpenAI: educación, seguridad juvenil y modelo de negocio
OpenAI lanza Education for Countries para escalar IA en sistemas educativos
OpenAI presentó su iniciativa Education for Countries, un nuevo pilar dentro de OpenAI for Countries orientado a integrar IA en sistemas educativos nacionales. El programa combina acceso a herramientas como ChatGPT Edu, GPT‑5.2, modos específicos para estudio y canvas con investigación a escala país sobre resultados de aprendizaje, certificaciones oficiales y una red global de gobiernos y universidades.
La primera cohorte incluye a Estonia, Grecia, Emiratos Árabes Unidos, Jordania, Kazajistán, Eslovaquia, Trinidad y Tobago y la conferencia de rectores italiana (CRUI). En Estonia, ChatGPT Edu ya opera en universidades y secundaria, con estudios longitudinales junto a la Universidad de Tartu y Stanford para medir el impacto en más de 20.000 estudiantes. El enfoque: cerrar el “capability overhang” entre lo que los modelos ya pueden hacer y lo que sistemas educativos realmente aprovechan.
Fuente: [clic aquí]

Nuestro enfoque para la predicción de edad en ChatGPT
OpenAI detalló también cómo funciona su modelo de predicción de edad en ChatGPT para reforzar la seguridad de adolescentes. El sistema combina señales de cuenta y comportamiento (antigüedad, patrones de uso, horarios típicos, edad declarada) para estimar si un usuario podría ser menor de 18 años y, en ese caso, activar automáticamente protecciones adicionales.
Entre esas salvaguardas se incluyen restricciones sobre violencia gráfica, desafíos virales arriesgados, role‑play sexual o violento, contenido de autolesión y materiales que refuercen estándares extremos de belleza o dietas poco saludables. Cuando la predicción clasifica erróneamente a un adulto como menor, el usuario puede verificar su edad de forma rápida mediante selfie con el proveedor de identidad Persona. OpenAI subraya que el despliegue será gradual (incluida la UE) y que seguirá ajustando el modelo frente a intentos de evasión.
Fuente: [clic aquí]
Un negocio que escala con el valor de la inteligencia
En un ensayo firmado por su CFO, Sarah Friar, OpenAI expuso su visión de modelo de negocio ligado al “valor de la inteligencia”. La compañía describe un ciclo flywheel donde el aumento de cómputo (de 0,2 GW en 2023 a ~1,9 GW en 2025) permite entrenar modelos más potentes, que a su vez impulsan la adopción de productos (ChatGPT, API, soluciones sectoriales) y generan ingresos para financiar más infraestructura.
OpenAI afirma haber pasado de 2.000 a más de 20.000 millones de dólares de ARR entre 2023 y 2025, apoyándose en una combinación de suscripciones de consumo y empresa, APIs de pago por uso y nuevas vías como anuncios y comercio dentro de ChatGPT. La estrategia clave: diversificar proveedores de hardware y reservar capacidad con años de antelación, manteniendo un balance ligero vía acuerdos de cómputo y estructura de contratos flexible.
Fuente: [clic aquí]
Cómo OpenAI escala PostgreSQL para 800 millones de usuarios de ChatGPT
En una entrada de ingeniería, OpenAI explicó cómo ha llevado PostgreSQL al límite para servir millones de consultas por segundo a unos 800 millones de usuarios de ChatGPT y la API, manteniendo un único primario de Azure PostgreSQL Flexible Server y casi 50 réplicas de lectura repartidas globalmente.
El artículo detalla estrategias como: aislar cargas de trabajo por prioridad para evitar “vecinos ruidosos”; usar PgBouncer como capa de pooling para reducir tiempos de conexión (de ~50 ms a ~5 ms) y proteger el límite de 5.000 conexiones; aplicar mecanismos de cache‑locking para evitar tormentas de lecturas cuando falla la caché; migrar cargas de escritura shardables hacia sistemas como Azure Cosmos DB; y colaborar con Azure en replicación en cascada para escalar el número de réplicas sin sobrecargar al primario. Según la compañía, esto ha permitido sostener latencias p99 de decenas de milisegundos y cinco nueves de disponibilidad con un solo writer.
Fuente: [clic aquí]
Anthropic: nueva constitución de Claude y educación global
Anthropic publica la nueva constitución de Claude
Anthropic hizo pública una nueva versión de la constitución de Claude, el documento que define los valores, prioridades y pautas de comportamiento del modelo. A diferencia de versiones anteriores basadas en listas de principios, la nueva constitución adopta un enfoque más narrativo y explicativo pensado ante todo para el propio Claude: detalla por qué debe actuar de ciertas maneras, cómo ponderar trade‑offs y cómo interpretar instrucciones futuras.
La constitución articula cuatro grandes objetivos para Claude: ser ampliamente seguro, ampliamente ético, cumplir las directrices específicas de Anthropic y ser genuinamente útil, en ese orden de prioridad. Incluye secciones sobre utilidad (como “amigo brillante” con conocimientos expertos), cumplimiento de guías especializadas (por ejemplo, en ciberseguridad o biología), ética y virtud, seguridad sistémica (no socavar mecanismos humanos de supervisión) y reflexiones sobre la naturaleza y posible estatus moral futuro de los modelos. El documento se publica bajo licencia CC0, invitando a su reutilización por otros actores.

Fuente: [clic aquí]
Anthropic y Teach For All forman una red global de docentes creadores de IA
Anthropic anunció una alianza con la red internacional Teach For All para lanzar la AI Literacy & Creator Collective (LCC), una iniciativa que pretende llevar herramientas y formación en IA a más de 100.000 docentes y exalumnos en 63 países, cubriendo a 1,5 millones de estudiantes.
El programa se estructura en tres capas: una serie de formación en fluencia de IA y casos de uso con Claude; Claude Connect, un hub continuo donde más de 1.000 educadores comparten prompts y artefactos; y Claude Lab, un espacio de innovación donde docentes con acceso a Claude Pro crean aplicaciones educativas (currículos interactivos, juegos de matemáticas gamificados, workspaces digitales) y dan feedback directo al roadmap de producto. La colaboración se suma a pilotos nacionales previos de Anthropic en Islandia, Ruanda y otros países.
Fuente: [clic aquí]
Mariano‑Florentino Cuéllar se incorpora al Long‑Term Benefit Trust de Anthropic
El Long‑Term Benefit Trust de Anthropic incorporó al jurista Mariano‑Florentino (Tino) Cuéllar como nuevo trustee. El Trust, un órgano independiente sin participación financiera, tiene mandato para nombrar parte del consejo de administración de Anthropic y asesorar sobre cómo maximizar el beneficio público de la IA avanzada.
Cuéllar aporta una trayectoria que incluye su etapa como juez del Tribunal Supremo de California, presidencia del Carnegie Endowment for International Peace y liderazgo de iniciativas sobre modelos frontera de IA en California y en la Academia Nacional de Ciencias de EE. UU. Su incorporación refuerza el giro de los laboratorios de frontera hacia estructuras de gobernanza con perfiles de derecho, política pública y relaciones internacionales.
Fuente: [clic aquí]
Arquitecturas y modelos base
Microsoft presenta Differential Transformer V2
Un equipo de Microsoft Research publicó en el blog de Hugging Face la Differential Transformer V2 (DIFF V2), una versión refinada de su arquitectura de atención diferencial pensada para LLM de producción. El objetivo es mantener o mejorar la calidad frente al Transformer clásico, pero con mayor estabilidad de entrenamiento y sin necesidad de kernels de atención personalizados.
DIFF V2 introduce más cabezas de consulta manteniendo el número de cabezas KV, permitiendo usar FlashAttention estándar y alcanzar velocidades de decodificación comparables al Transformer. El diseño elimina una RMSNorm por cabeza que en la V1 generaba picos de gradiente con contextos largos, y reemplaza un escalar global por un parámetro λ proyectado por token y por cabeza. En preentrenos a gran escala (modelos densos y MoE de 30A3) se observa menor pérdida de lenguaje, menos outliers de activación y menos inestabilidad a learning rates altos, abriendo la puerta a backbones más eficientes para modelos y agentes de próxima generación.
Fuente: [clic aquí]
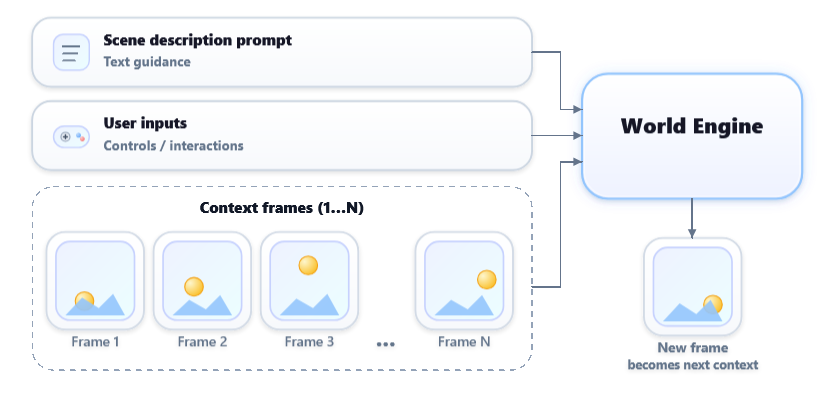
Waypoint‑1: mundos de vídeo interactivos en tiempo real
Overworld presentó Waypoint‑1, un modelo de difusión de vídeo interactivo entrenado en 10.000 horas de partidas de videojuegos con sus entradas de control y texto. A diferencia de modelos de vídeo condicionados solo por prompts, Waypoint‑1 está diseñado para responder en tiempo real a teclado, ratón y texto, generando cada frame en función de acciones del usuario, con latencias que permiten 30–60 FPS en hardware de consumo.
El modelo utiliza un backbone de rectified flow transformer causal en frames, entrenado primero con “diffusion forcing” (aprender a denoiser cada frame futuro a partir de los pasados) y posteriormente con self‑forcing para alinear mejor el comportamiento de entrenamiento e inferencia y reducir la acumulación de errores en rollouts largos. La librería de inferencia WorldEngine —publicada en GitHub— ofrece un loop optimizado para streaming interactivo con trucos como cacheo de condicionamientos AdaLN, KV cache estático y
torch.compile, permitiendo experimentar con agentes que “habitan” mundos generados por vídeo.
Fuente: [clic aquí]

Benchmarks y evaluación para agentes
AssetOpsBench: benchmark agentic para mantenimiento industrial
Investigadores de IBM Research y Hugging Face lanzaron AssetOpsBench, un benchmark diseñado para evaluar sistemas multiagente en contextos de operaciones industriales (chillers, unidades de aire, etc.). El dataset incluye 2,3 millones de puntos de telemetría de sensores, más de 4.000 órdenes de trabajo y 53 modos de fallo estructurados, organizados en 140+ escenarios que requieren coordinación entre varios agentes.
AssetOpsBench evalúa a los agentes en seis dimensiones cualitativas: finalización de la tarea, precisión de recuperación, verificación de resultados, secuenciación de acciones, claridad/justificación y tasa de alucinación. Los primeros experimentos muestran que agentes generalistas suelen razonar bien en superficie, pero fallan al sostener cadenas largas de decisiones bajo datos ruidosos, con tasas significativas de “finalización sobre‑declarada” y recuperación de errores ineficaz. El benchmark incorpora un pipeline de análisis de trayectorias (TrajFM) que extrae patrones de fallo recurrentes y permite a los builders iterar sobre diseños multiagente más robustos.
Fuente: [clic aquí]
Lectura Recomendada
Aunque no es una publicación de esta semana, este análisis de Menlo Ventures, “2025: The State of Generative AI in the Enterprise”, es especialmente interesante para entender cómo se está consolidando la IA generativa en la empresa (casos de uso, stack típico, métricas de ROI y retos de despliegue y gobernanza).
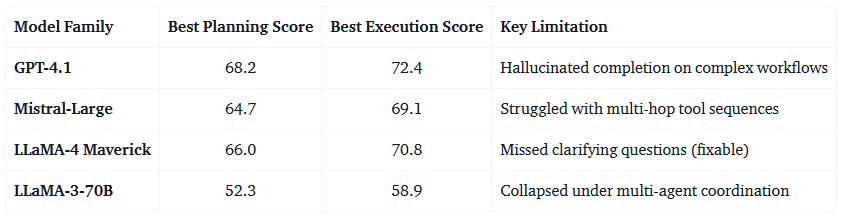
- Cuota de mercado de IA por API en empresas:
- Anthropic - 40%
- OpenAI - 27%
- Google - 21%
- Uso de modelos en programación:
- Anthropic - 54%
- OpenAI - 21%
- Google - 11%
Fuente: [clic aquí]
Desde la Investigación (arXiv, última semana)
Inference‑Time Scaling of Verification: Self‑Evolving Deep Research Agents via Test‑Time Rubric‑Guided Verification (arXiv:2601.15808) (22 ENE 2026).
Fuente: [clic aquí]
Plantea el paradigma de Inference‑Time Scaling of Verification, donde agentes de investigación profunda se auto‑mejoran en tiempo de inferencia verificando sus propias salidas con ayuda de rúbricas. Introduce DeepVerifier, un verificador de resultados basado en una taxonomía de fallos de DRAs (5 categorías, 13 subcategorías) que genera feedback estructurado y permite refinar iterativamente respuestas sin reentrenar el modelo base. En benchmarks como GAIA y XBench‑DeepResearch, este bucle de verificación aporta mejoras de 8–11 puntos de precisión en los casos más difíciles y se acompaña del dataset DeepVerifier‑4K para entrenar verificadores abiertos.
ErrorMap and ErrorAtlas: Charting the Failure Landscape of Large Language Models (arXiv:2601.15812) (22 ENE 2026).
Fuente: [clic aquí]
Propone ErrorMap, un método para trazar la “firma de fallos” de un LLM y construir un atlas de errores (ErrorAtlas) que va más allá de las métricas clásicas de acierto. A partir de resultados en 83 modelos y 35 datasets, el sistema clasifica errores en categorías como problemas de formato, cálculos incorrectos, omisión de requisitos o mala interpretación de la pregunta, revelando patrones poco explorados (por ejemplo, omisiones sistemáticas de detalles obligatorios). La idea: complementar los benchmarks de éxito con una capa transversal de análisis de errores para guiar mejor alineamiento y selección de modelos.
DeepSurvey‑Bench: Evaluating Academic Value of Automatically Generated Scientific Survey (arXiv:2601.15307) (13 ENE 2026).
Fuente: [clic aquí]
Introduce DeepSurvey‑Bench, un benchmark centrado en el valor académico profundo de surveys científicos generados por modelos, más allá de la coherencia superficial o las citas. Define tres dimensiones de evaluación —valor informacional, de comunicación académica y de orientación a la investigación— y construye un conjunto de surveys anotados según estos criterios. Los resultados muestran que muchos sistemas que parecen sólidos en métricas de forma fallan al sintetizar debates clave o proponer líneas futuras de trabajo, algo crítico para agentes que generan revisiones de literatura.
Aeon: High‑Performance Neuro‑Symbolic Memory Management for Long‑Horizon LLM Agents (arXiv:2601.15311) (14 ENE 2026).
Fuente: [clic aquí]
Propone Aeon, un “sistema operativo cognitivo” que trata la memoria de agentes de largo horizonte como un recurso gestionado. Combina un Memory Palace (índice espacial basado en Atlas, un índice de vectores acelerado por SIMD con navegación tipo small‑world y localización B+‑tree) con una Trace (grafo episódico neuro‑simbólico) y un Semantic Lookaside Buffer (SLB) para caché predictiva. En cargas dialogadas logra latencias de recuperación sub‑milisegundo manteniendo consistencia de estado mediante un puente C++/Python de cero copias, ofreciendo una base robusta para agentes autónomos con memoria persistente.
Prometheus Mind: Retrofitting Memory to Frozen Language Models (arXiv:2601.15324) (18 ENE 2026).
Fuente: [clic aquí]
Explora cómo añadir memoria a modelos congelados (en el paper, un Qwen3‑4B) usando 11 adaptadores modulares (~530 MB, un 7% de sobrecarga) completamente reversibles. Presenta Contrastive Direction Discovery (CDD) para extraer direcciones semánticas sin datos etiquetados, un esquema de entrenamiento por etapas para evitar colapsos fin‑to‑end y un truco de inyección que reutiliza filas de la cabeza LM como mapeo sin entrenar nuevos decoders. En el benchmark PrometheusExtract‑132 alcanza un 94,4% de recuperación en inputs limpios, aunque la precisión cae en lenguaje informal, señalando la clasificación de relaciones como cuello de botella principal.
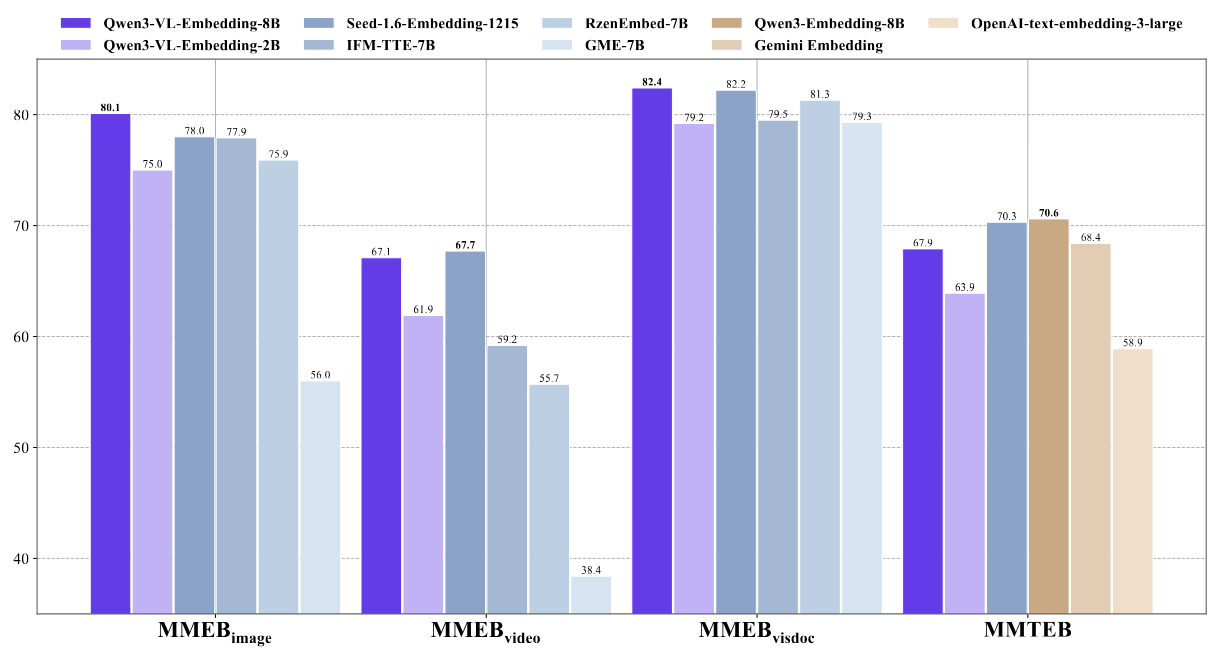
Qwen3‑VL‑Embedding and Qwen3‑VL‑Reranker: A Unified Framework for State‑of‑the‑Art Multimodal Retrieval and Ranking (arXiv:2601.04720) (19 ENE 2026).
Fuente: [clic aquí]
Presenta las familias Qwen3‑VL‑Embedding y Qwen3‑VL‑Reranker, construidas sobre el modelo base Qwen3‑VL para ofrecer un pipeline extremo a extremo de búsqueda multimodal de alta precisión. Qwen3‑VL‑Embedding usa un entrenamiento multi‑etapa (preentrenamiento contrastivo masivo seguido de destilación desde un reranker) para generar vectores ricos que soportan Matryoshka Representation Learning (dimensión de embedding flexible) y entradas de hasta 32k tokens en texto, imágenes de documentos y vídeo. Qwen3‑VL‑Reranker actúa como cross‑encoder con atención cruzada para refinar la relevancia query‑documento, y en benchmarks como MMEB‑V2 el modelo de 8B parámetros alcanza un 77,8 de score global, situándose en primer lugar en evaluación de embeddings multimodales; es especialmente relevante para agentes que necesitan recuperar, reordenar y razonar sobre contexto visual extenso.
Modelos de IA Interesantes (lanzamientos y tendencias)
Waypoint‑1 (Overworld).
Modelo de difusión de vídeo interactivo en tiempo real entrenado en gameplays con controles asociados. Permite a un agente generar mundos tipo videojuego donde el usuario controla cámara y acciones mediante ratón, teclado y texto, con latencias compatibles con 30–60 FPS y una librería de inferencia (WorldEngine) pensada para streaming continuo.Fuente: [clic aquí]
Waypoint‑1‑Small / Medium (Overworld).
Checkpoints de distintos tamaños orientados a despliegues en hardware de consumo y a investigación en world models agentic. El tamaño Small (~2,3B parámetros) ya permite experiencias fluidas en GPUs únicas, lo que habilita prototipos de juegos generativos y simulaciones interactivas accesibles.Fuente: [clic aquí]
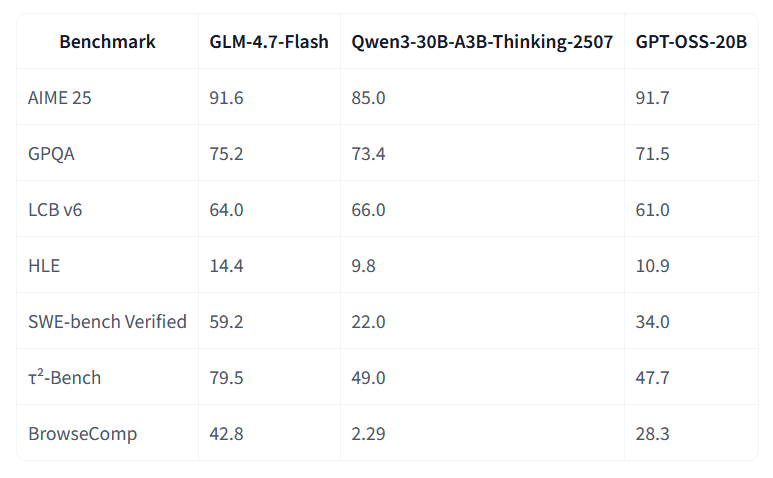
GLM‑4.7‑Flash (Z-ai / Z.ai).
Modelo MoE de 30B‑A3B parámetros pensado como opción “flash” en la familia GLM‑4.7, con foco en despliegues ligeros que no sacrifican rendimiento. Destaca en benchmarks como AIME 25, GPQA, SWE‑bench Verified o τ²‑Bench, y viene afinado para tareas agentic (incluido un modo de “thinking preservado”) y para servir vía vLLM o SGLang con soporte de tool calling y reasoning parser, lo que lo hace atractivo como backbone generalista para agentes y copilotos propios.Fuente: [clic aquí]

Comparación de resultados obtenidos por el nuevo GLM-4.7Flash, comparado con otros modelos de similar tamaño Soprano‑1.1‑80M (ekwek).
Modelo text‑to‑speech ultraligero (~80M parámetros) diseñado para correr on‑device con latencias de milisegundos y audio a 32 kHz, ofreciendo voz muy expresiva y clara con hasta 2000× real‑time en GPU y ~20× en CPU. Soporta WebUI, CLI y endpoint compatible con OpenAI (/v1/audio/speech), por lo que encaja bien si quieres añadir voz sintética rápida a agentes o apps sin depender de servicios cerrados.Fuente: [clic aquí]
LightOnOCR‑2 (LightOn).
Nueva generación de modelos OCR optimizados para velocidad/calidad evaluados en OlmOCR‑Bench, donde la variante LightOnOCR‑2‑1B se sitúa en la frontera de Pareto de rendimiento frente a velocidad (páginas/segundo por H100) frente a modelos como DeepSeek‑OCR u olmOCR‑2. Está pensado para pipelines de lectura masiva de documentos (PDF, escaneos) donde necesitas extraer texto fiable a gran escala como entrada para agentes que razonan sobre facturas, contratos o informes.Fuente: [clic aquí]
Utilidades para builders
WorldEngine (Overworld).
Runtime de inferencia optimizado en Python para modelos tipo Waypoint‑1, con KV cache estático, caching de condicionamiento y soporte paratorch.compile. Facilita montar bucles de juego, simuladores o experiencias inmersivas donde un agente controla un mundo generado por vídeo.Fuente: [clic aquí]

CopilotKit + MCP‑Apps (AG‑UI).
Framework open source para construir copilotos in‑app que ahora añade una infraestructura 100% abierta de MCP‑Apps. Con unas pocas líneas de código puedes hacer que tus agentes devuelvan mini‑apps interactivas dentro del copilot, no solo texto, conectadas vía el protocolo AG‑UI y herramientas MCP tratadas como componentes de frontend. Funciona con los principales frameworks de agentes (ADK, LangChain, Mastra, Strands, Pydantic, etc.) y permite comunicación bidireccional entre tu app y el servidor MCP. Demo interactiva.Fuentes: [clic aquí] [aquí]
Capa de paisaje agrícola en Google Earth (Google DeepMind).
Nuevo data layer para Google Earth en partes de la región Asia‑Pacífico que, usando visión por satélite y modelos de ML, identifica las unidades atómicas de agricultura: límites de parcelas individuales, cuerpos de agua y vegetación. Permite pasar de agregados regionales a insights a nivel de finca —p. ej., calcular superficie exacta, localizar recursos hídricos o planificar contingencias de sequía— y es una referencia interesante de cómo combinar modelos de percepción con productos geoespaciales masivos.Fuente: [clic aquí]
- Fuentes abiertas de datasets para ML.
Recopilación de sitios útiles para conseguir datos de entrenamiento y benchmarking reales:- StrataScratch (retos de negocio con datos reales: https://platform.stratascratch.com/data-projects)
- el clásico UCI Machine Learning Repository (https://archive.ics.uci.edu/)
- los AWS Public Datasets (https://registry.opendata.aws/)
- World Bank Open Data (https://data.worldbank.org/)
- el portal Data.gov (https://data.gov/)
- Google Dataset Search (https://datasetsearch.research.google.com/)
- OpenML (https://www.openml.org/)
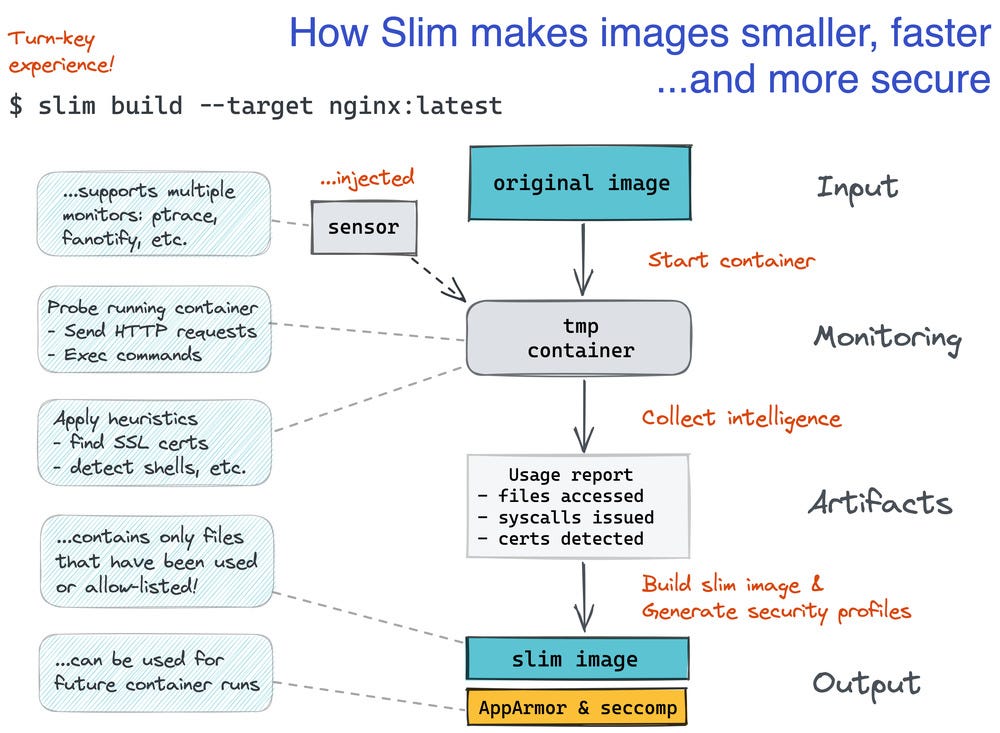
SlimToolkit: contenedores Docker 30× más pequeños.
Herramienta open source que analiza tu contenedor en tiempo de ejecución y genera una imagen mínima con solo los binarios y ficheros realmente usados, sin cambiar tu Dockerfile ni tu flujo de trabajo. El patrón es build con Docker → minify conslim build→ subir la imagen.slim, con reducciones típicas de tamaño de hasta 30×, lo que acelera despliegues y reduce costes de almacenamiento.Fuente: [clic aquí]
Unsloth GRPO long‑context para RL.
Actualización de Unsloth que introduce nuevos algoritmos de batching y chunking (sobre batch y secuencia) para entrenar con contextos 7× más largos o más en RL tipo GRPO, sin degradar velocidad ni calidad frente a setups muy optimizados. Permite, por ejemplo, llevar gpt‑oss hasta ~380K tokens en una B200 de 192 GB o Qwen3‑8B a ~110K en una H100 de 80 GB usando vLLM y QLoRA, y ofrece knobs comounsloth_grpo_mini_batchyunsloth_logit_chunk_multiplierpara ajustar el trade‑off VRAM/rendimiento cuando entrenas agentes de razonamiento de contexto largo.Fuente: [clic aquí]
Algunas Noticias Breves de IA
OpenAI amplía su programa Horizon 1000 junto a la Fundación Gates para apoyar proyectos de IA aplicados a atención primaria y salud global, profundizando en la intersección entre modelos y sistemas sanitarios.
Fuente: [clic aquí]
OpenAI lanza Stargate Community, una red de actores públicos y privados que participan en el diseño de su infraestructura de cómputo de próxima generación, con foco en energía limpia y reparto internacional de capacidad.
Fuente: [clic aquí]
Hugging Face y socios organizan un hackathon de world models en torno a world_engine y Waypoint‑1, con el objetivo de explorar agentes que habitan mundos generativos persistentes y nuevas UX para juegos y simulaciones.
Fuente: [clic aquí]
Cloudflare anuncia la adquisición de Astro, el framework de desarrollo web de alto rendimiento, para integrar su equipo y tecnología en la plataforma de Cloudflare (Workers, Pages) y acelerar el futuro del frontend estático e híbrido sobre su red global.
Fuente: [clic aquí]
Google libera Gemini CLI como herramienta de línea de comandos open source, con acceso a los system prompts oficiales y una experiencia de terminal sencilla (
npm install -g @google/gemini-cli→gemini). Permite traer Gemini directamente al workflow del desarrollador en consola, sin depender de UIs gráficas.Fuente: [clic aquí]
Ollama lanza compatibilidad con la Anthropic Messages API, permitiendo usar Claude Code y otros clientes de Anthropic contra modelos locales o en la nube de Ollama simplemente cambiando la
base_url. Acerca el patrón de agentes de coding tipo Claude Code al ecosistema de modelos open source y despliegues on‑prem.Fuente: [clic aquí]
El Ministerio para la Transformación Digital y de la Función Pública abre la consulta pública del “ómnibus” de inteligencia artificial en España, un paquete normativo que busca adaptar el marco regulatorio nacional al Reglamento europeo de IA y recoger aportaciones de ciudadanía, empresas y expertos antes de su aprobación.
Fuente: [clic aquí]
Abierta la inscripción al Desafío ALIA para alinear el modelo abierto ALIA 40B Instruido, un reto de alineamiento impulsado por la Comunidad de IA de Código Abierto y organizado por la Secretaría de Estado de Digitalización e Inteligencia Artificial, con la colaboración de Talent Arena - MWC26 Barcelona, Amazon Web Services y Multiverse Computing; la final tendrá lugar en Talent Arena 2026 en el marco del MWC26 Barcelona.
Fuente: [clic aquí]
