

En Resumen: lo imprescindible
- Clawdbot y la ola de asistentes local‑first con acceso real al sistema: Clawdbot/OpenClaw populariza el patrón de “empleado IA” que corre en tu propio equipo o servidor, habla contigo por Telegram, WhatsApp o Discord, tiene memoria persistente y acceso real al sistema, a cambio de tomarse muy en serio seguridad, puertos expuestos y costes de inferencia.
- OpenAI empuja la siguiente generación de agentes y workspace científico: lanza un agente interno de datos sobre GPT‑5.2 para su propia analítica, presenta Prism como editor LaTeX con IA integrada y endurece la seguridad de navegación de agentes con un sistema de “link safety”.
- Claude se consolida como motor de agentes empresariales y públicos: Anthropic convierte a Claude en modelo por defecto para Build Agent de ServiceNow, colabora con el gobierno del Reino Unido en un asistente piloto en GOV.UK y muestra casos de uso extremos como la planificación de recorridos del rover Perseverance en Marte.
- World models, vídeo generativo y la carrera por los mundos interactivos: Google DeepMind abre Project Genie como laboratorio web sobre Genie 3, mientras xAI lanza Grok Imagine para generación y edición de vídeo desde API, reforzando la convergencia entre modelos de mundo y creación audiovisual.
- Nuevas herramientas para builders y developers: Mistral publica Vibe 2.0 como agente de programación centrado en terminal; Hugging Face lanza Daggr para orquestar grafos de IA y upskill para destilar “skills” especializadas desde modelos frontier a modelos abiertos; y se consolidan stacks como VoxCPM, skills.sh, Mosaico y los modelos abiertos de Earth‑2 para montar agentes de voz, marketplaces de skills y tooling de datos/evaluación.
Infra y evaluación para RL agéntico y retrieval en producción: se documentan técnicas para escalar RL de agentes en GPT‑OSS‑20B, surgen benchmarks dialectales como Alyah y espaciales como SpatialGenEval/SpatialT2I, y el paper de Airbnb sobre recuperación a escala aporta números reales y trade‑offs (IVF vs HNSW, métricas de conversión) aplicables a RAG y búsqueda en producción.
Noticias Recientes
Clawdbot/Moltbot/OpenClaw: asistente local-first con acceso real al sistema
ClawdBot se ha convertido en uno de los proyectos más comentados de la semana: un asistente de código abierto que corre en tu propio equipo o servidor, con el que puedes hablar vía Telegram, WhatsApp, Discord u otras plataformas, y que tiene acceso real al sistema, memoria persistente y soporte para múltiples proveedores de modelos (Claude, GPT, Gemini, DeepSeek, etc.). La instalación se reduce a un único comando (
curl | bash), lo que refuerza la sensación de tener literalmente un “empleado IA” trabajando en tu máquina.El proyecto apuesta por la combinación open source + local first + memoria persistente, lo que transmite más control que muchos asistentes puramente en la nube, pero también exige tomarse muy en serio la seguridad: conviene aislarlo en una VM o en una máquina secundaria, vigilar puertos expuestos (un servicio accesible desde fuera equivale casi a un
sudoremoto) y revisar cuidadosamente los permisos que le das desde el primer día. A nivel de costes, puede usarse con modelos locales o con opciones más equilibradas como Minimax M2.1, y el propio Clawbot incluye comandos comoclawdbot statusyclawdbot security auditpara detectar configuraciones peligrosas (aunque no sustituyen a una auditoría de seguridad completa).
Fuentes: [clic aquí] [aquí]

OpenAI: agentes internos, seguridad y productividad científica
Cómo funciona el agente interno de datos de OpenAI
OpenAI ha publicado una visión en profundidad de su agente interno de datos, construido sobre GPT‑5.2 y desplegado en la propia compañía para responder preguntas complejas de negocio, explorar métricas y automatizar partes del análisis. El sistema combina varias capas de contexto (esquemas de tablas, documentación viva, anotaciones humanas y código auxiliar) con mecanismos de memoria y evaluación continua, buscando que el agente se comporte como un “compañero de equipo” que propone hipótesis, pide aclaraciones y genera SQL o dashboards cuando es necesario.
Fuente: [aquí]
Link safety: menos fugas de datos vía enlaces en agentes
En paralelo, OpenAI ha detallado un nuevo sistema de protección frente a enlaces maliciosos o sensibles en agentes con navegación web. El mecanismo cruza cada URL con un índice público de destinos permitidos, limita qué contenidos se recuperan automáticamente y muestra advertencias cuando el enlace no puede verificarse, reduciendo el riesgo de exfiltración de datos privados a través de rutas creativas. El post incluye un paper técnico que desgrana el modelo de amenazas y la arquitectura de verificación.
Fuente: [aquí]
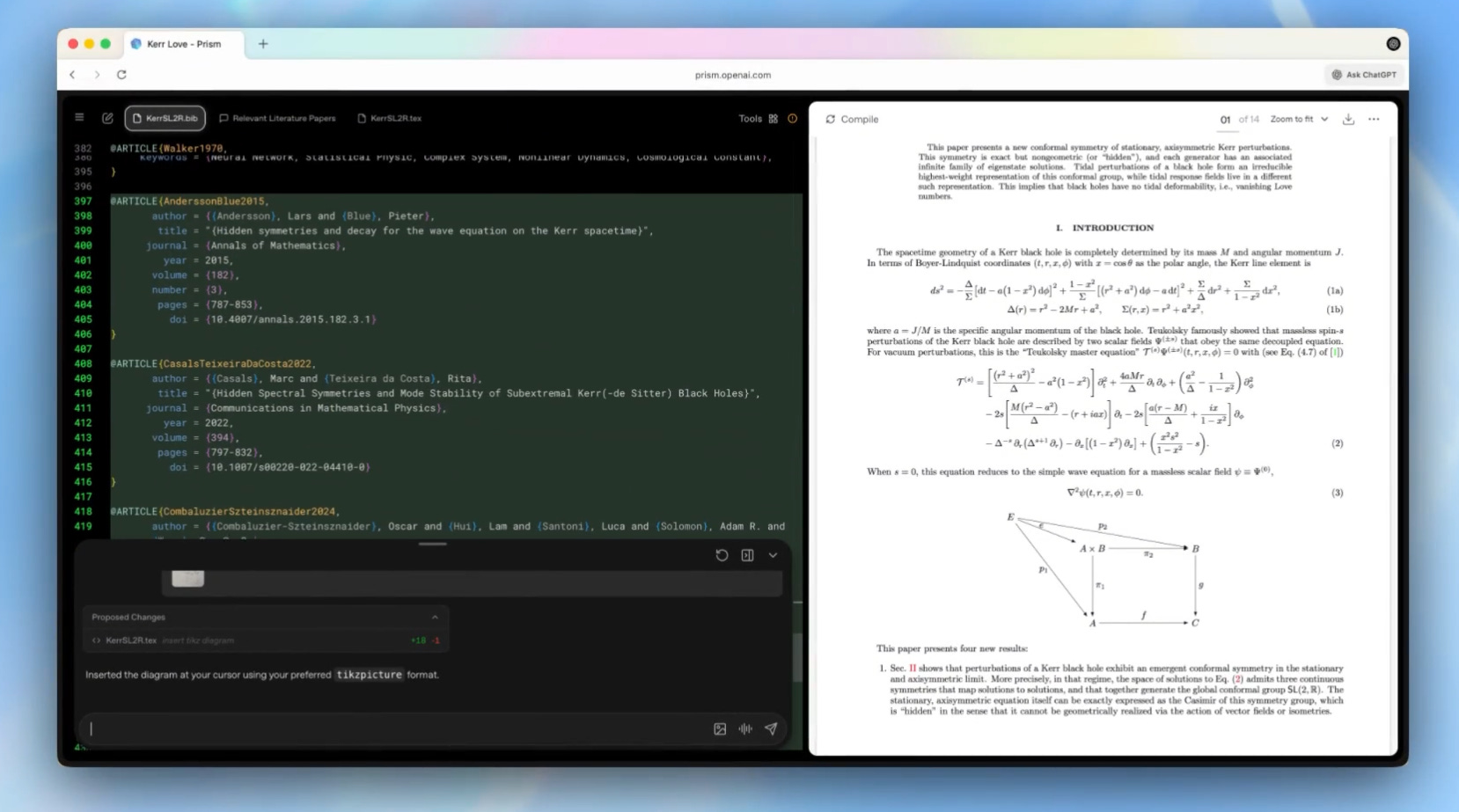
Prism: editor LaTeX con GPT‑5.2 para papers y notas técnicas
OpenAI también ha lanzado Prism, un espacio de trabajo centrado en LaTeX que integra GPT‑5.2 como asistente para redactar, revisar y comentar artículos científicos. Prism ofrece chat contextual sobre el documento, manejo robusto de ecuaciones, referencias y figuras, y colaboración en tiempo real, posicionándose como un potencial reemplazo “IA‑nativo” de los editores LaTeX tradicionales para grupos de investigación y equipos técnicos.
Fuentes: [aquí] [aquí]
OpenAI prepara la retirada de GPT‑4o y modelos heredados en ChatGPT
Finalmente, OpenAI ha comunicado que GPT‑4o, GPT‑4.1, GPT‑4.1 mini y o4‑mini dejarán de estar disponibles en ChatGPT el 13 de febrero de 2026 (aunque seguirán accesibles por API). La compañía argumenta que la mayoría de usuarios ya prefiere GPT‑5.1 y GPT‑5.2 por calidad, personalidad y creatividad, y recomienda migrar flujos de trabajo a los modelos más recientes en las próximas semanas.
Fuente: [aquí]
Anthropic: Claude en la empresa, el sector público y… Marte
Claude como modelo por defecto de Build Agent en ServiceNow
Anthropic y ServiceNow han anunciado que Claude se convierte en el modelo por defecto para Build Agent y en modelo de referencia dentro de ServiceNow AI. Esto permite a equipos empresariales generar flujos de trabajo, integraciones y automatizaciones a partir de lenguaje natural, con Claude actuando como “cerebro” que interpreta requisitos, escribe acciones en la plataforma y propone mejoras. El acuerdo incluye además el uso de Claude Code para acelerar desarrollo interno y operaciones.
Fuente: [aquí]
Piloto de asistente con Claude en GOV.UK
En el ámbito público, Anthropic colabora con el gobierno del Reino Unido en un piloto de asistente conversacional en GOV.UK, inicialmente orientado a apoyar a buscadores de empleo en la navegación de servicios y trámites. El proyecto se enmarca en el enfoque gubernamental de “Scan, Pilot, Scale” y se coordina con el UK AI Safety Institute, poniendo el foco en controles de seguridad, transparencia sobre limitaciones del modelo y supervisión humana antes de escalarlo a más dominios.
Fuente: [aquí]
Claude ayuda a planificar un trayecto del rover Perseverance
Anthropic también ha destacado un caso de uso llamativo en colaboración con NASA JPL: ingenieros utilizaron Claude Code y un lenguaje de marcado específico para rovers a la hora de simular y verificar un recorrido de unos 400 metros del rover Perseverance en Marte. Claude ayuda a generar y revisar comandos, evaluar rutas alternativas y detectar posibles riesgos en simulación antes de que se ejecuten en el planeta rojo.
Fuente: [aquí]
World models y vídeo generativo: Project Genie y Grok Imagine
Project Genie: mundos interactivos generados por Genie 3
Google DeepMind ha presentado Project Genie, un experimento web que permite a suscriptores de Google AI Ultra crear y explorar mundos interactivos generados por el modelo de mundo Genie 3, junto a Nano Banana Pro y Gemini. A partir de texto e imágenes, los usuarios pueden esbozar escenarios, moverse por ellos en primera o tercera persona y remezclar mundos existentes, convirtiendo a Genie en un laboratorio público para interfaces basadas en world models aplicables a robótica, juegos y experiencias educativas.
Fuente: [aquí]

Grok Imagine: la apuesta de xAI por vídeo generativo desde API
Por su parte, xAI ha lanzado Grok Imagine, una API para generar vídeo a partir de texto y para editar clips existentes (añadiendo, por ejemplo, objetos o cambios de estilo). La compañía acompaña el anuncio con benchmarks frente a modelos como Veo y Sora en plataformas como Artificial Analysis y LMArena, posicionando Grok Imagine como una opción competitiva en calidad, latencia y coste para integraciones en productos de contenido, publicidad o prototipado creativo.
Fuente: [aquí]
Desde la Investigación (arXiv, blogs técnicos y benchmarks)
Unlocking Agentic RL Training for GPT-OSS: A Practical Retrospective.
Un equipo de LinkedIn y colaboradores ha documentado cómo estabilizar el entrenamiento de refuerzo sobre agentes construidos con GPT‑OSS‑20B, combinando mejoras en PPO, uso de FlashAttention v3 con “attention sinks” y optimizaciones de memoria (FSDP, paralelismo de secuencia, batch dinámico). En entornos como GSM8K, verificación de instrucciones y el benchmark agentico ReTool reportan convergencia más rápida y mejor rendimiento con menos coste computacional.Fuente: [aquí]
Alyah: Toward Robust Evaluation of Emirati Dialect Capabilities in Arabic LLMs.
Investigadores de TII y colaboradores han presentado Alyah, un benchmark cuidadosamente anotado que evalúa cómo manejan los modelos el dialecto emiratí, incluyendo expresiones coloquiales, referencias culturales, poesía y normas sociales. El estudio sobre más de 50 modelos muestra que incluso sistemas grandes fallan con frecuencia en matices dialectales, subrayando la importancia de benchmarks localizados para despliegues reales en árabe.Fuente: [aquí]
Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models (SpatialGenEval).
El trabajo introduce SpatialGenEval, un benchmark para medir la inteligencia espacial de modelos text‑to‑image, con 1.230 prompts largos e informativos que cubren 10 subdominios espaciales (posición, oclusión, interacción, causalidad, etc.) y preguntas de opción múltiple. Además construyen SpatialT2I, un dataset de 15.400 pares texto‑imagen con prompts reescritos; al afinar modelos base como Stable Diffusion‑XL, Uniworld‑V1 u OmniGen2 logran mejoras consistentes en relaciones espaciales, apuntando a un enfoque data‑centric para dotar de razonamiento espacial a modelos generativos.Fuente: [aquí]
Scaling Embeddings Outperforms Scaling Experts in Language Models.
Este paper analiza la escalabilidad por la vía de los embeddings como alternativa a la clásica escalabilidad mediante Mixture‑of‑Experts (MoE) en LLMs. Los autores muestran que, en ciertos regímenes de tamaño y presupuesto de parámetros, dedicar una gran fracción de parámetros a embeddings escasos puede ofrecer una mejor frontera de Pareto que aumentar el número de expertos, y presentan LongCat‑Flash‑Lite (68,5B parámetros, ~3B activados), que supera baselines MoE equivalentes y resulta especialmente competitivo en dominios agentic y de coding, apoyado además en optimizaciones de sistema y speculative decoding para convertir la esparsidad en velocidad real de inferencia.Fuente: [aquí]
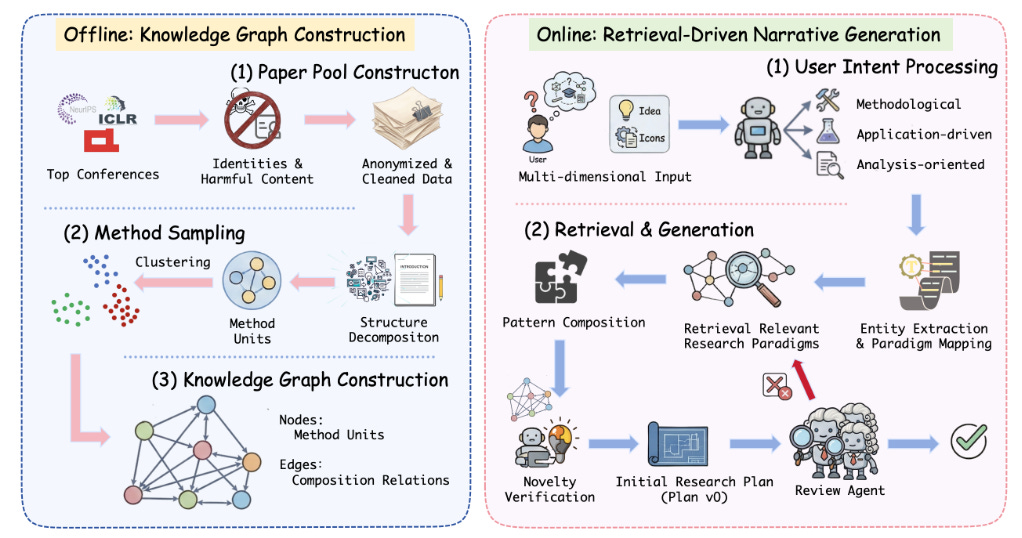
Idea2Story: An Automated Pipeline for Transforming Research Concepts into Complete Scientific Narratives.
En lugar de depender de agentes que leen y resumen literatura “en vivo” una y otra vez, Idea2Story propone un marco de descubrimiento científico autónomo guiado por pre‑cómputo: construye de forma continua un grafo de conocimiento metodológico a partir de papers revisados por pares y sus reviews, extrayendo patrones reutilizables de diseño experimental. Cuando recibe una idea de investigación poco especificada, el sistema la alinea con esos patrones, recupera y ensambla bloques de método probados y genera narrativas científicas completas más coherentes, reduciendo coste de cómputo, dependencia del contexto largo y alucinaciones en planificación de experimentos.Fuente: [aquí]
Modelos de IA Interesantes (lanzamientos y tendencias)
Kimi-K2.5 (Moonshot AI).
Modelo MoE nativo multimodal y agentic (hasta 1T parámetros totales, 32B activados) preentrenado en ~15T tokens texto‑imagen/vídeo, con contextos de hasta 256K tokens, modos de uso “instant” y “thinking”, y un énfasis fuerte en razonamiento, tool‑use y orquestación de enjambres de agentes para tareas complejas.Fuente: [aquí]
Z-Image (Tongyi‑MAI).
Modelo fundacional de generación de imagen basado en un Diffusion Transformer de una sola rama, no destilado, pensado como backbone de alta calidad para prompts complejos, workflows profesionales y fine‑tuning (LoRA, ControlNet), con gran diversidad compositiva y soporte robusto de prompts negativos.Fuente: [aquí]
Qwen3-TTS-12Hz-1.7B-CustomVoice (Qwen).
Modelo text‑to‑speech multilingüe (10 idiomas) orientado a voz personalizada, que ofrece 9 timbres premium (combinando género, edad y dialecto) y permite controlar estilo, emoción y prosodia vía instrucciones en lenguaje natural, con una arquitectura 12 Hz optimizada para latencias muy bajas y streaming.Fuente: [aquí]
HunyuanImage-3.0-Instruct (Tencent).
Versión “Instruct” de HunyuanImage‑3.0, un modelo multimodal autoregresivo tipo MoE (80B parámetros totales, 13B activos) para text‑to‑image e image‑to‑image con razonamiento, capaz de reescribir prompts (CoT), entender imágenes de entrada y realizar edición avanzada, fusión de múltiples imágenes y generación fotorealista con fuerte adherencia al prompt.Fuente: [aquí]

VibeVoice-ASR (Microsoft).
Modelo ASR unificado para audio largo que procesa hasta 60 minutos de audio en una sola pasada, generando transcripciones estructuradas con quién habla, cuándo y qué dice (ASR + diarización + timestamps), soporte para más de 50 idiomas y hotwords personalizadas, pensado para meetings, podcasts y análisis de conversaciones largas.Fuente: [aquí]
mmBERT-Embed-32K-2D-Matryoshka (LLM Semantic Router).
Modelo de embeddings multilingüe (1800+ lenguas) pensado para caching semántico y retrieval a escala, con ventana de contexto de 32K (evita trocear contratos o papers largos) y arquitectura 2D Matryoshka que permite reducir dimensión (768→256) y capas (22→6) en tiempo de ejecución para ahorrar almacenamiento y ganar velocidad casi sin perder calidad. Alcanza ~80,5 en STS (por encima de Qwen3‑0.6B con menos parámetros) y está optimizado con FlashAttention 2 para ser competitivo en latencia frente a BGE‑M3 y Qwen3 Embedding.Fuente: [aquí]
DeepSeek-OCR-2 (DeepSeek).
Segunda generación de la familia DeepSeek‑OCR, un modelo vision‑language para OCR de documentos que introduce el marco de “Visual Causal Flow” y soporta resolución dinámica y prompts tipo “Convert the document to markdown”. Está optimizado para extracción estructurada de texto en PDFs/imágenes largas, con soporte para FlashAttention 2, integración con vLLM y demos listos para pipelines de lectura masiva de documentos.Fuente: [aquí]
Utilidades para builders
Daggr: flujos complejos, visuales y versionables.
Si estás montando pipelines donde intervienen varios modelos, herramientas y pasos de pre/post‑proceso, Daggr te permite expresar ese flujo como un grafo, cachear resultados intermedios y re‑ejecutar sólo lo que cambia. Es especialmente útil para iterar rápido en sistemas multiagente y cadenas de herramientas largas.Fuente: [aquí]
upskill: destilar capacidades especializadas en modelos locales.
El enfoque de upskill —usar un modelo frontier para generar definiciones de habilidad + suites de tests, y luego entrenar/evaluar modelos pequeños sobre ellas— es interesante si quieres añadir capacidades muy específicas (SQL, CUDA, compliance, etc.) a un modelo que puedas ejecutar on‑prem o en dispositivos con recursos limitados.Fuente: [aquí]
Mistral Vibe 2.0 como interfaz de desarrollo.
Vibe 2.0 refuerza la tendencia de los agentes “centrados en terminal”: en lugar de ser un chat aislado, se incrusta en tu flujo habitual de comandos, entiende la estructura del repo y mantiene contexto sobre sesiones largas, lo que puede ahorrar muchos ciclos de “copiar/pegar” entre la consola y un chat aparte.Fuente: [aquí]
VoxCPM: agentes de voz end‑to‑end.
Stack open source para montar agentes conversacionales de voz extremos a extremo (ASR + LLM + TTS) sobre modelos de la familia CPM, con scripts listos para demo, soporte de streaming y ejemplos de integración en apps y productos.Fuente: [aquí]
skills.sh: marketplace de skills para agentes.
Plataforma tipo “app store” de skills para copilots y agentes, donde puedes descubrir, compartir y versionar capacidades empaquetadas (con código y tests) reutilizables entre modelos y frameworks.Fuente: [aquí]
Mosaico: infraestructura para datos y evaluación de agentes.
Proyecto open source que ofrece tooling para crear, versionar y evaluar datasets y tareas para agentes, con soporte para pipelines reproducibles, métricas personalizadas y dashboards, pensado para equipos que iteran rápido sobre agentes en producción.Fuente: [aquí]
Earth-2 Open Models (NVIDIA).
Conjunto de modelos abiertos de simulación climática y meteorológica de NVIDIA Earth‑2 (por ejemplo CorrDiff y FourCastNet) disponibles en Hugging Face, que sirven como bloques para construir agentes que razonan sobre predicción del tiempo, riesgos climáticos y planificación de infraestructuras.Fuente: [aquí]
Algunas Noticias Breves de IA
Google publica el ensayo “Beyond the chatbot: a blueprint for trustable AI”, donde propone un marco de capacidades, pruebas y salvaguardas para construir sistemas de IA “confiables” más allá del chat genérico (incluyendo agentes especializados, evaluaciones continuas y transparencia sobre límites y fallos).
Fuente: [aquí]
El grupo SINAI de la Universidad de Jaén anuncia un nuevo proyecto para investigar cómo garantizar una inteligencia artificial fiable y transparente, centrado en trazabilidad de decisiones, explicabilidad y mitigación de sesgos en sistemas que se despliegan en la administración pública.
Fuente: [aquí]
Google lanza Little Language Lessons, una alternativa gratuita a Duolingo centrada en práctica conversacional y pronunciación con IA: cubre más de 40 idiomas, genera diálogos y vocabulario personalizados y corrige la pronunciación en tiempo real desde el navegador.
Fuente: [aquí]

Sale la versión 3.0.0 de pandas, una actualización mayor de la librería de análisis de datos en Python que introduce cambios en el sistema de tipos (nullable por defecto), mejoras de rendimiento y varias APIs nuevas/deprecadas; importante revisar el “what’s new” antes de actualizar proyectos de data/ML.
Fuente: [aquí]
Anthropic publica el estudio “How AI assistance impacts the formation of coding skills”, un ensayo controlado con desarrolladores donde muestran que usar asistencia de IA al aprender una nueva librería puede reducir la comprensión y, sobre todo, la capacidad de depurar código (‑17 puntos frente al grupo sin IA), salvo cuando la herramienta se usa explícitamente para entender mejor el código y los conceptos.
Fuente: [aquí]
Lectura recomendada
Applying Embedding-Based Retrieval to Airbnb Search.
Si este fin de semana quieres leer un paper aplicado a sistemas de recuperación con embeddings en producción, el trabajo de Airbnb es una pequeña masterclass. Describe cómo sirven millones de búsquedas diarias con latencia sub‑segundo, filtran más de 100K listings por consulta y procesan 10K actualizaciones por segundo manteniendo la calidad de ranking, logrando un 0,31 % de mejora en conversión (equivalente a millones en ingresos). Lo más interesante es que explica de forma honesta los trade‑offs: por qué eligieron IVF en lugar de HNSW (mejor soporte para writes en tiempo real y filtros), cómo cambiar de producto escalar a euclídeo evitó clusters desequilibrados y duplicó la eficiencia, y cómo combinan batch offline (embeddings diarios) con refresco en etapas posteriores. También es una introducción muy clara a recuperación con embeddings, arquitecturas two‑tower, contraste negativo duro y optimización de búsqueda vectorial, con lecciones transferibles a RAG, motores de recomendación, e‑commerce search y content discovery.
Fuente: [aquí]