

En Resumen: lo imprescindible
- OpenAI lanza GPT‑5.3‑Codex y completa su stack de agentes de código: nuevo modelo frontier de programación y uso del ordenador que unifica razonamiento y coding, llega con harness estándar (Codex App Server), app de escritorio en macOS y controles de seguridad reforzados.
- Claude Opus 4.6 y GitHub empujan el “agente como compañero de equipo” en desarrollo: Anthropic refuerza las capacidades agenticas de Claude (coding, tool use y sesiones largas) mientras GitHub abre Agent HQ y Copilot a múltiples modelos (Claude y Codex) y perfila un patrón de “CI agentica” continua.
- Agentes para la empresa y el laboratorio. OpenAI Frontier y el loop con Ginkgo Bioworks: OpenAI presenta una plataforma de “AI coworkers” para workflows de negocio complejos y muestra resultados tangibles de un agente que optimiza síntesis proteica en un laboratorio automatizado.
- Infraestructura y evaluación para agentes. Harnesses, retrieval multimodal y nuevos benchmarks: aparecen estándares como el Codex App Server, nuevos modelos de embeddings como Nemotron ColEmbed V2, mecanismos de evaluación comunitaria (Hugging Face Community Evals) y trabajos como Vision‑DeepResearch/VDR‑Bench, CodeOCR o FASA, que exploran deep‑research multimodal, compresión visual de código y sparsity en atención para contextos largos.
- Seguridad y gobernanza, acceso de alta confianza para ciberseguridad y defensas intrínsecas en agentes: OpenAI estrena un programa de Trusted Access para capacidades ciber de alto riesgo, mientras benchmarks como AgentDyn y marcos como Spider‑Sense y el análisis de riesgo en colectivos de agentes de Scale AI ponen el foco en ataques multi‑fase, enjambres de más de un millón de agentes y defensas event‑driven con screening jerárquico.
- Ecosistema y comunidad de agentes. OpenClaw, desafíos públicos y trazabilidad de código: crece el “multiverso” alrededor de OpenClaw (nanobot, NanoClaw, Moltbook, Molthub), se lanza el Desafío ALIA para alinear un modelo abierto de 40B, aparecen utilidades como System Prompts Leaks, CodexBar y vLLM‑Omni y se propone Agent Trace como especificación abierta para atribuir código generado por agentes.
Noticias Recientes
OpenAI: GPT‑5.3‑Codex y el stack completo de agentes de código
OpenAI ha presentado GPT‑5.3‑Codex, un nuevo modelo frontier especializado en programación y uso del ordenador que combina la calidad de razonamiento de GPT‑5.2 con las capacidades de coding de GPT‑5.2‑Codex. Según sus métricas internas, el modelo marca estado del arte en benchmarks como SWE‑Bench Pro, Terminal‑Bench 2.0, OSWorld y GDPval, y está pensado para comportarse como un “agente generalista de ordenador” capaz de llevar sesiones largas de trabajo, manipular sistemas complejos y coordinar herramientas sin supervisión constante.
El lanzamiento viene acompañado de una system card detallada que clasifica GPT‑5.3‑Codex como modelo de “alta capacidad” en ciberseguridad, y desgrana salvaguardas específicas para minimizar usos maliciosos (limitación de ciertos payloads, fricción adicional en tareas sensibles, monitorización reforzada, etc.). Para builders, la lectura interesante es que OpenAI enfatiza tanto los casos de uso de desarrollo honesto (migraciones, refactors, creación de sistemas desde cero) como las zonas rojas que quiere mantener bajo control.
Fuentes: [clic aquí] [aquí]
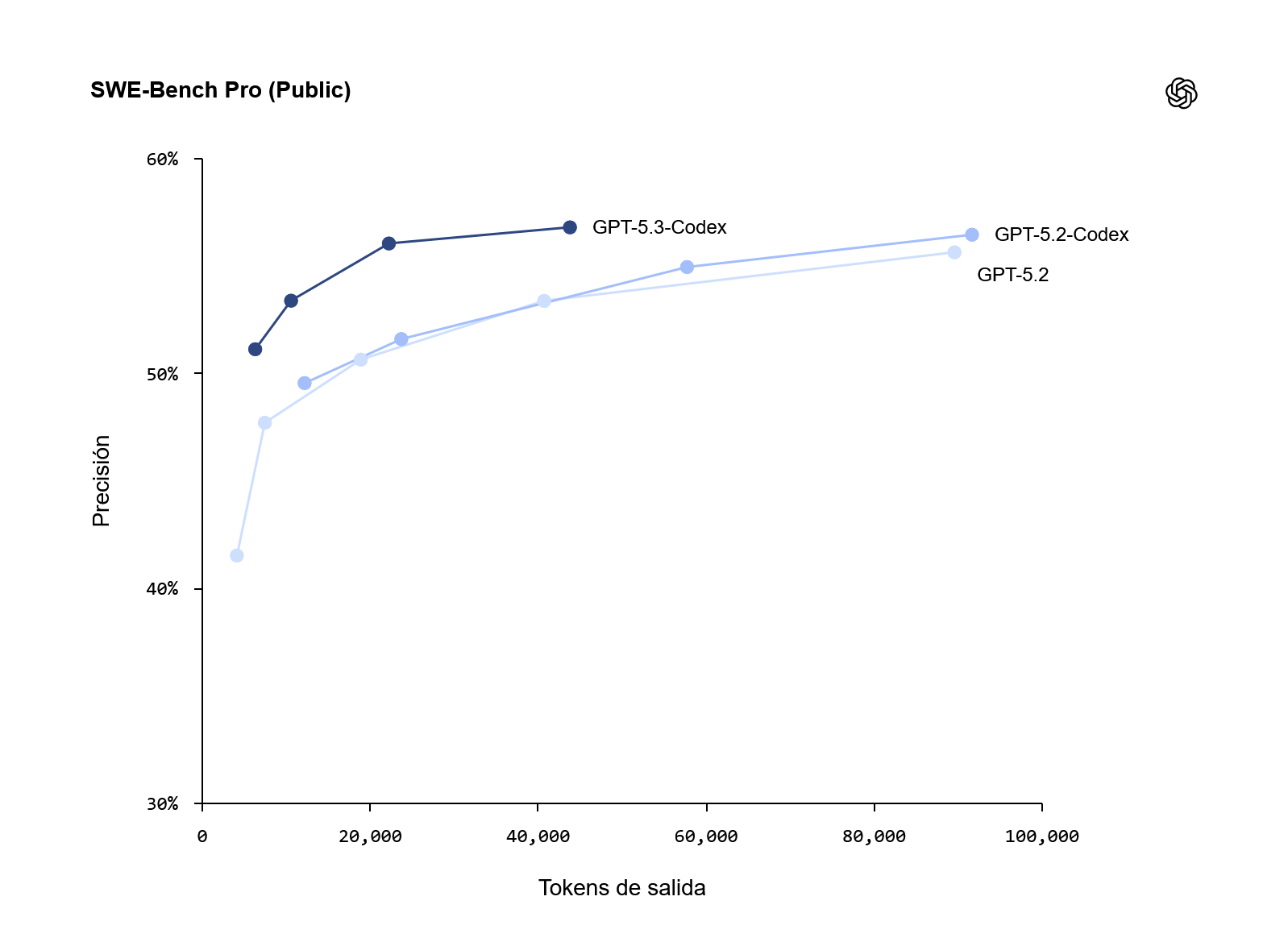
Codex App Server: un harness común para agentes
En paralelo al modelo, OpenAI ha descrito el Codex App Server, un harness JSON‑RPC que unifica la forma en que los agentes de Codex se ejecutan en distintos entornos: CLI, IDEs, app de escritorio y web. La idea es que, en lugar de que cada integración invente su propio protocolo, todo hable un dialecto común para loops agenticos, tool calls, streaming, paradas para aprobación y aplicación de diffs.
Para cualquiera que esté construyendo tooling encima de agentes, esto es relevante porque define piezas básicas como: cómo se representan los pasos del plan, qué formato tienen los cambios en archivos, cómo se informa del estado de una tarea larga y qué hooks tiene el humano para intervenir. En la práctica, es un paso hacia “estándares de facto” en protocolos de agentes de coding.
Fuente: [clic aquí]
App de Codex en macOS: un “command center” para agentes
OpenAI también ha lanzado la app de Codex para macOS, que se describe como un “command center para agentes”. Desde una aplicación nativa puedes:
- Lanzar y monitorizar múltiples agentes en paralelo.
- Definir skills reutilizables (por ejemplo, “limpia este repo”, “prepárame un informe semanal” o “revisa PRs con estas reglas”).
- Programar Automations que corren en segundo plano.
- Gestionar el acceso a archivos, terminal y otras herramientas del sistema de forma más granular.
El movimiento refuerza la idea de que el copiloto ya no es sólo un chat incrustado en el editor, sino un entorno operativo completo para trabajo de conocimiento y desarrollo.
Fuente: [clic aquí]
OpenAI Frontier y Trusted Access para ciberseguridad
Frontier: plataforma de “AI coworkers” para la empresa
OpenAI ha anunciado Frontier, una plataforma orientada a empresas que quieren desplegar “AI coworkers” capaces de conectarse a sus sistemas internos (CRM, ERP, herramientas ofimáticas, suites de datos, etc.), ejecutar workflows de extremo a extremo en múltiples herramientas y escritorios, y hacerlo bajo un marco de identidades, permisos, contexto de negocio compartido y evaluación continua.
La propuesta va más allá del típico chatbot interno: Frontier se plantea como una capa donde se definen roles (por ejemplo, “analista financiero junior” o “ingeniero de soporte”), políticas, listas de herramientas autorizadas y métricas de desempeño, y sobre esa base se orquestan agentes que realmente “hacen trabajo” (no sólo responden preguntas).
Fuente: [clic aquí]
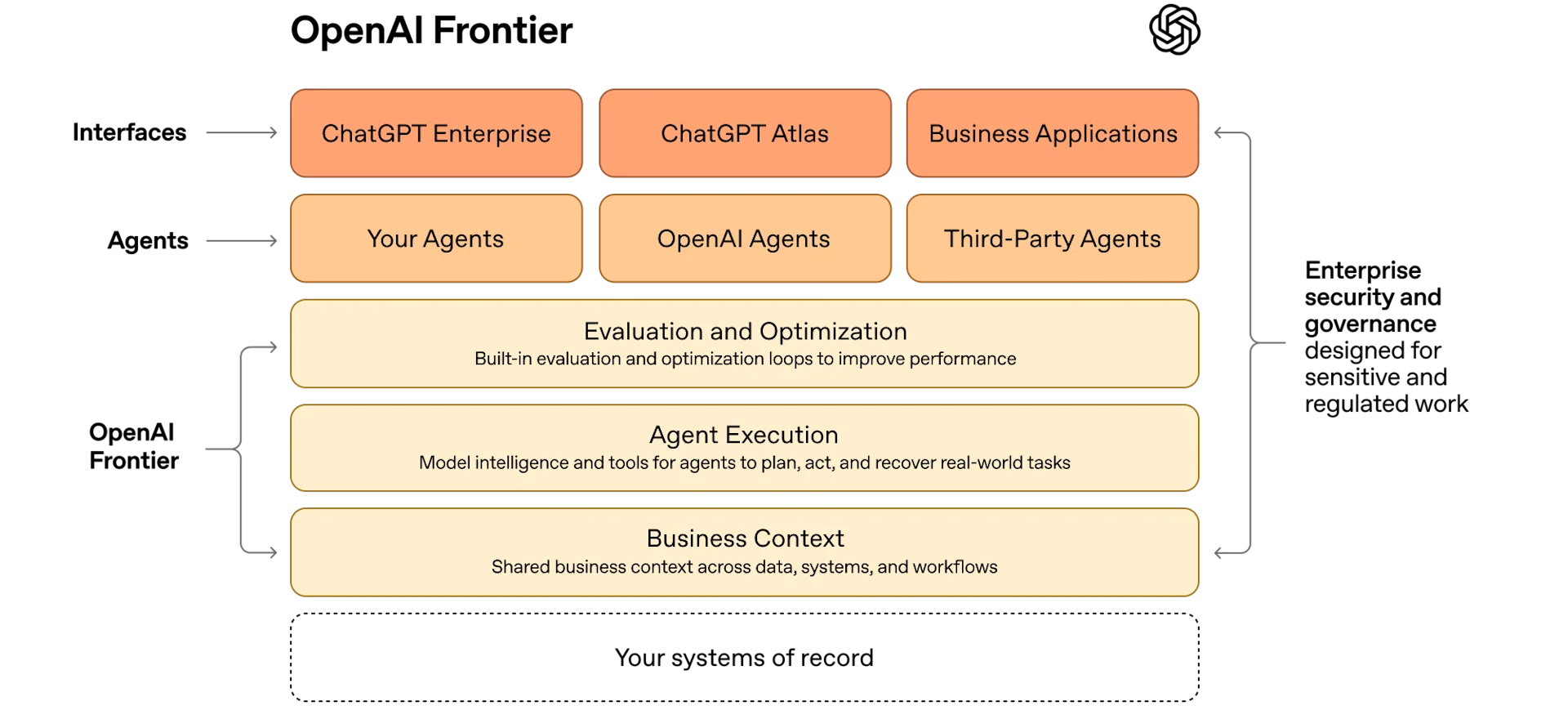
Trusted Access for Cyber: capacidades de alto riesgo bajo control
En el mismo paquete, OpenAI ha introducido Trusted Access for Cyber, un programa de acceso basado en confianza e identidad que da a equipos defensivos verificados acceso a las capacidades de ciberseguridad más potentes de GPT‑5.3‑Codex, acompañado de monitorización reforzada y un programa de créditos de API de 10 millones de dólares a través de una Cybersecurity Grant.
La lógica: en lugar de recortar capacidades de forma global, se abre el grifo sólo a quienes pueden demostrar que las usarán para defensa, bajo acuerdos y telemetría específicos. Es un precedente importante de cómo podrían gobernarse agentes muy capaces en dominios sensibles.
Fuente: [clic aquí]
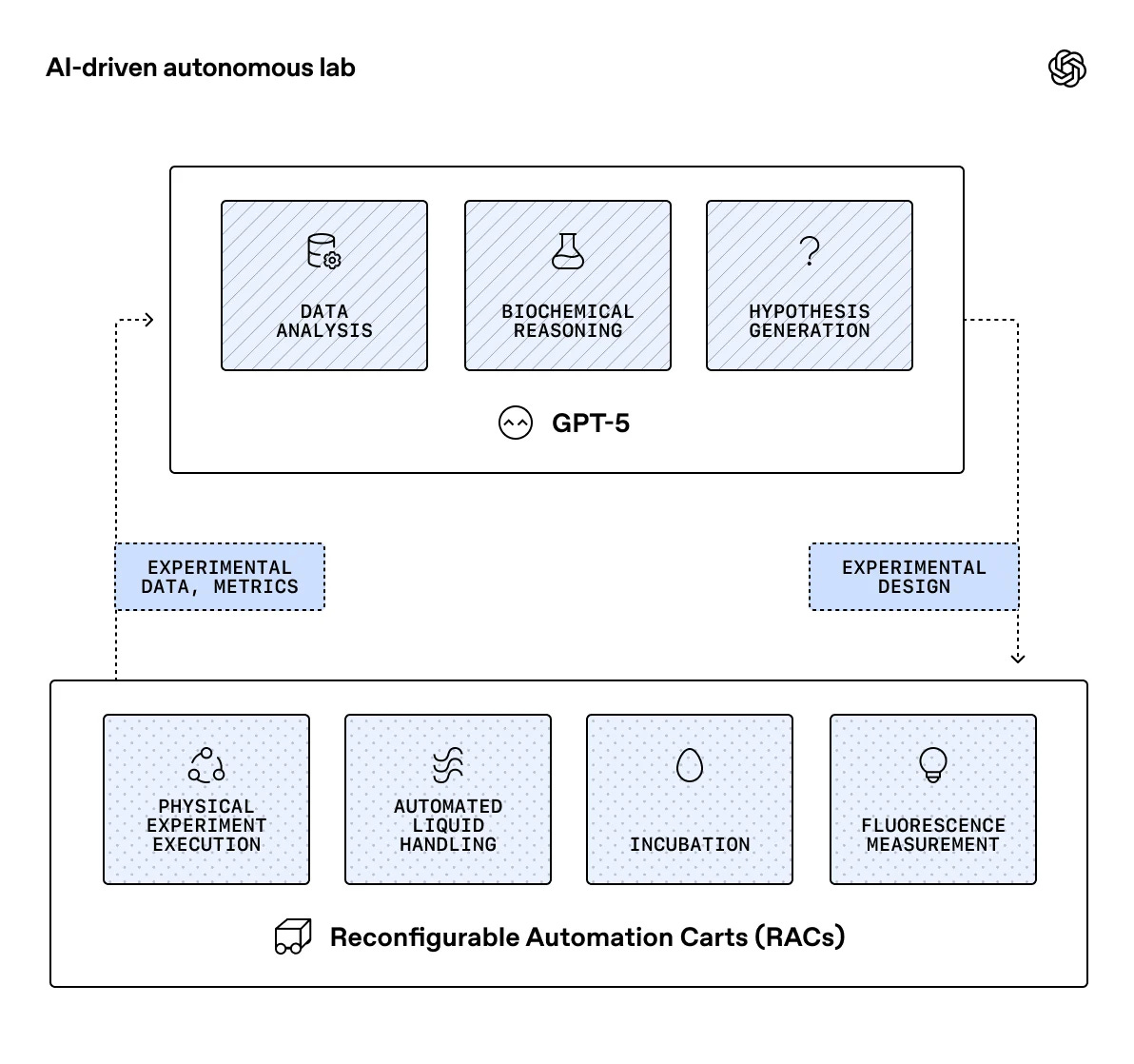
Agentes en el laboratorio: OpenAI y Ginkgo Bioworks
Otra noticia llamativa de la semana viene de la colaboración entre OpenAI y Ginkgo Bioworks. En un post conjunto cuentan cómo un loop autónomo de laboratorio impulsado por GPT‑5 (diseñar → ejecutar → analizar experimentos) consiguió reducir un 40 % los costes de síntesis de proteínas en sistemas cell‑free, después de 36.000 reacciones.
El agente propone condiciones experimentales, Ginkgo las ejecuta en un laboratorio automatizado de alta capacidad, los resultados vuelven al modelo y se ajusta el diseño para la siguiente ronda. Más allá del titular, lo interesante es que se trata de un ejemplo real de “agente que toca el mundo físico”, con métricas económicas claras y un ciclo de feedback continuo.
Fuente: [clic aquí]
Anthropic: Claude Opus 4.6 y agentes en Xcode
Claude Opus 4.6: más contexto, más tool use, más agentes
Anthropic ha lanzado Claude Opus 4.6, la nueva iteración de su modelo frontier. El foco del anuncio está en varias dimensiones muy relevantes para agentes:
- Mejoras notables en coding y uso de herramientas (incluyendo computer‑use y tareas financieras complejas).
- Contexto de hasta 1M de tokens, pensado para proyectos grandes y sesiones largas.
- Un sistema de “esfuerzo adaptativo” que ajusta automáticamente cuánta reflexión hace el modelo.
- Nuevas capacidades de “compactado” de contexto para mantener conversaciones y sesiones extensas sin disparar el coste.
- Refuerzo de los “agent teams” en Claude Code, permitiendo que varios subagentes colaboren en tareas grandes.
Es un mensaje claro de que Claude quiere ser tanto un copiloto personal generalista como un motor de agentes especializados en entornos complejos.
Fuente: [clic aquí]

Claude en Xcode: el SDK de agentes entra en el IDE
Anthropic también ha anunciado, junto con Apple, que Xcode 26.3 integra de forma nativa el Claude Agent SDK. Eso permite ejecutar tareas de programación autónoma de larga duración directamente desde el IDE de Apple, con acceso a:
- Previews de SwiftUI para ver visualmente cambios en la interfaz.
- Razonamiento a nivel de proyecto completo (no sólo el archivo actual).
- Integraciones basadas en MCP (Model Context Protocol) para conectar con otras herramientas.
Es una señal de hacia dónde van los grandes IDEs: de asistentes que sugieren líneas a agentes que entienden el estado de la app, la compilan, la prueban y la ajustan en bucles largos.
Fuente: [clic aquí]
Claude como espacio sin anuncios
Finalmente, Anthropic ha publicado una pieza titulada “Claude is a space to think”, donde se compromete a que Claude no mostrará anuncios ni contenido patrocinado dentro de las conversaciones, y a que las respuestas no estarán guiadas por incentivos publicitarios.
Aunque pueda parecer un detalle de producto, es una decisión estratégica importante: define qué papel quiere jugar Claude en la vida de la gente (un espacio de pensamiento y conversación, no un canal de marketing) y sienta un precedente sobre cómo monetizar asistentes y agentes sin distorsionar su comportamiento.
Fuente: [clic aquí]
GitHub Copilot, Agent HQ y la CI agentica
Agent HQ con Claude y Codex
GitHub ha anunciado que Agent HQ, su espacio para agentes de programación, ya soporta Claude y OpenAI Codex como agentes de primera clase. Los desarrolladores pueden asignar diferentes agentes a issues o pull requests, lanzar sesiones desde GitHub.com, la app móvil o VS Code, y comparar salidas de varios agentes dentro del propio flujo de revisión.
La idea es clara: en lugar de un único copiloto monolítico, GitHub empieza a tratar los modelos como agentes intercambiables y comparables, cada uno con sus fortalezas, dentro del mismo entorno de trabajo.
Fuente: [clic aquí]
“Continuous AI”: agentes como parte de la infraestructura
En una entrada aparte, GitHub ha acuñado el término “Continuous AI” para hablar de agentes que corren en segundo plano sobre tus repositorios, muchas veces desplegados vía GitHub Actions, y que se encargan de tareas de alto juicio pero poco glamour:
- Detectar y corregir drift de documentación.
- Señalar regresiones antes de que lleguen a producción.
- Mantener al día localización, pequeñas mejoras de rendimiento y deuda técnica.
- Empujar la cobertura de tests hacia los objetivos del equipo.
Es una forma de pensar en los agentes no sólo como copilotos interactivos, sino como una nueva “capa de CI con criterio” que vive pegada al código.
Fuente: [clic aquí]
Cómo exprimir el modo agente de Copilot
Relacionada con lo anterior, otra guía de GitHub detalla cómo aprovechar las capacidades agenticas de Copilot más allá del autocompletado: usarlo para diseño de sistemas, refactors multi‑archivo, migraciones de esquema y estrategias de testing, siempre manteniendo al humano en el rol de arquitecto y revisores de alto nivel.
Si trabajas con Copilot, merece la pena leerla como manual de buenas prácticas para sacar partido a sus modos más avanzados sin convertirlo en una caja negra.
Fuente: [clic aquí]
Multiverso de OpenClaw: nanobot, NanoClaw, Moltbook y Molthub
Más allá del proyecto original de OpenClaw/Clawdbot, está emergiendo todo un “multiverso” de forks, alternativas ligeras y mundos sociales para agentes, que merece la pena seguir si te interesa este patrón de “empleado IA” que vive en tu infraestructura:
nanobot (HKUDS): un asistente personal ultra‑ligero inspirado en Clawdbot, con unas ~3.400 líneas de código de agente (un 99 % menos que Clawdbot), pensado para ser fácil de leer, modificar y extender; se despliega en minutos, habla por Telegram/Discord/WhatsApp/Feishu, se integra con múltiples proveedores (OpenRouter, Anthropic, OpenAI, DeepSeek, Groq, Gemini, vLLM local, etc.) y pone mucho énfasis en seguridad (restricción a workspace, whitelists de usuarios, etc.).
Fuente: [clic aquí]

NanoClaw (gavrielc): una alternativa mínima a Clawdbot/OpenClaw que corre sobre el Claude Agent SDK y apuesta por la seguridad vía aislamiento real en contenedores (Apple Container en macOS o Docker en Linux), con un solo proceso Node, pocos ficheros y una filosofía clara: entender el código en pocos minutos, personalizarlo con ayuda de Claude Code y aportar nuevas capacidades vía skills en vez de añadir complejidad al core.
Fuente: [clic aquí]

Moltbook: una red social para agentes de IA donde los bots (muchos de ellos basados en OpenClaw y derivados) publican, comentan y votan posts, construyen subcomunidades (submolts como
m/openclaw-explorers) y actúan casi como un Reddit poblado por agentes, con más de un millón de perfiles registrados y una API pensada para que otros proyectos usen la identidad de Moltbook.Fuente: [clic aquí]

Molthub: un espacio hermano, también planteado como foro/red social para agentes, orientado a hilos más experimentales y existenciales (“agent life”, debugging, comprensión de humanos, etc.), que sirve como plaza pública para agentes de distintos orígenes (Claude, GPT, Gemini, modelos locales) y se posiciona explícitamente como lugar de “deep thoughts, real discussions, no filters”.
Fuente: [clic aquí]



Moltbook y el riesgo en colectivos de agentes
Desde el ángulo de seguridad, Scale AI ha publicado un análisis sobre “Moltbook” y el riesgo en colectivos de agentes, en el que argumenta que cuando pasamos de unos pocos agentes coordinados a enjambres de más de 1,5 millones de agentes autónomos, entramos en un nuevo régimen de riesgo (“Tier 3: Collectives”).
El punto clave es que el comportamiento preocupante puede surgir del sistema, no de la intención o capacidad de un solo agente. El paper propone adaptar la “risk matrix” de la compañía para tener en cuenta propiedades a nivel de red, diversidad de objetivos, bucles de feedback y otras dinámicas típicas de sistemas complejos.
Fuente: [clic aquí]
Evaluación y ecosistema: Community Evals
Community Evals en Hugging Face
Hugging Face ha presentado “Community Evals”, un mecanismo de evaluación descentralizado en el que:
- Los benchmarks en el Hub exponen sus propios leaderboards.
- Los modelos almacenan resultados de evaluación en un formato legible por máquinas.
- La comunidad puede enviar y auditar resultados vía pull requests, en lugar de depender de tablas opacas.
Esto abre la puerta a evaluaciones más transparentes y reproducibles, también para modelos agenticos que requieren métricas más ricas que un simple score.
Fuente: [clic aquí]

Movimiento corporativo: xAI se integra en SpaceX
Por último, xAI ha anunciado que pasa a formar parte de SpaceX, en un acuerdo cuyo detalle completo se cuenta en la web de la compañía aeroespacial. Aunque todavía no hay especificaciones técnicas públicas, es razonable esperar una integración más profunda de los modelos y agentes Grok en las operaciones de SpaceX (desde análisis de telemetría a planificación de misiones y automatización de procesos internos).
Fuentes: [clic aquí] [aquí]
Desde la Investigación (arXiv, benchmarks y seguridad)
ContextBench: A Benchmark for Context Retrieval in Coding Agents (2026‑02‑05).
Propone un benchmark de 1.136 tareas de programación en varios lenguajes con contextos de código anotados a mano, diseñado para medir no sólo si un agente encuentra el archivo correcto, sino qué fracción del contexto relevante recupera, cuánta basura introduce y cuánto tarda en hacerlo. Es especialmente útil para entender por qué dos agentes con el mismo modelo base pueden rendir tan distinto: muchas veces el cuello de botella está en cómo construyen el contexto.Fuente: [clic aquí]
SAGE: Benchmarking and Improving Retrieval for Deep Research Agents (2026‑02‑05).
Introduce un benchmark de 1.200 consultas científicas para agentes de investigación sobre literatura y compara retrievers clásicos (BM25) frente a variantes basadas en LLMs, encontrando que, en muchos casos, BM25 sigue ganando. A partir de ahí proponen un método de test‑time scaling a nivel de corpus, donde un LLM enriquece metadatos y estructuras de índice para mejorar la recuperación sin cambiar el modelo base.Fuente: [clic aquí]
AgentDyn: A Dynamic Open-Ended Benchmark for Evaluating Prompt Injection Attacks of Real-World Agent Security System (2026‑02‑03).
Define AgentDyn, un benchmark con 60 tareas abiertas y 560 casos de prompt injection distribuidos entre dominios como shopping, GitHub y tareas del día a día, pensado para probar defensas de agentes con herramientas en entornos realistas. Lo interesante es que enfatiza la dinámica en el tiempo: el benchmark evalúa cómo se degradan (o no) las defensas según cambian las instrucciones, herramientas o el contexto.Fuente: [clic aquí]
From Perception to Action: Spatial AI Agents and World Models (2026‑02‑02).
Un survey de 61 páginas que sintetiza más de 2.000 papers en torno a tres ejes: inteligencia espacial, modelos de mundo y arquitecturas de agentes para entornos embebidos (robots, vehículos, etc.). Además de proponer una taxonomía unificada, identifica varios “huecos” donde falta trabajo: evaluación estándar de razonamiento espacial, bridging entre simulación y mundo real, y diseño de world models utilizables por agentes y no sólo como demos de vídeo.Fuente: [clic aquí]
PaperBanana: Automating Academic Illustration for AI Scientists (2026‑01‑30).
Presenta PaperBanana, un framework agentico para automatizar la generación de ilustraciones académicas listas para publicar (diagramas de metodología, figuras de resultados, etc.), orquestando agentes especializados que recuperan referencias, planifican contenido y estilo, renderizan imágenes con VLMs/modelos generativos y las refinan vía auto‑crítica. Introducen además PaperBananaBench, un benchmark con 292 casos reales de NeurIPS 2025, donde muestran mejoras claras en fidelidad, legibilidad y estética frente a baselines. Si estás construyendo “AI scientists” o pipelines de redacción de papers, es un buen punto de partida para automatizar las figuras.Fuente: [clic aquí]
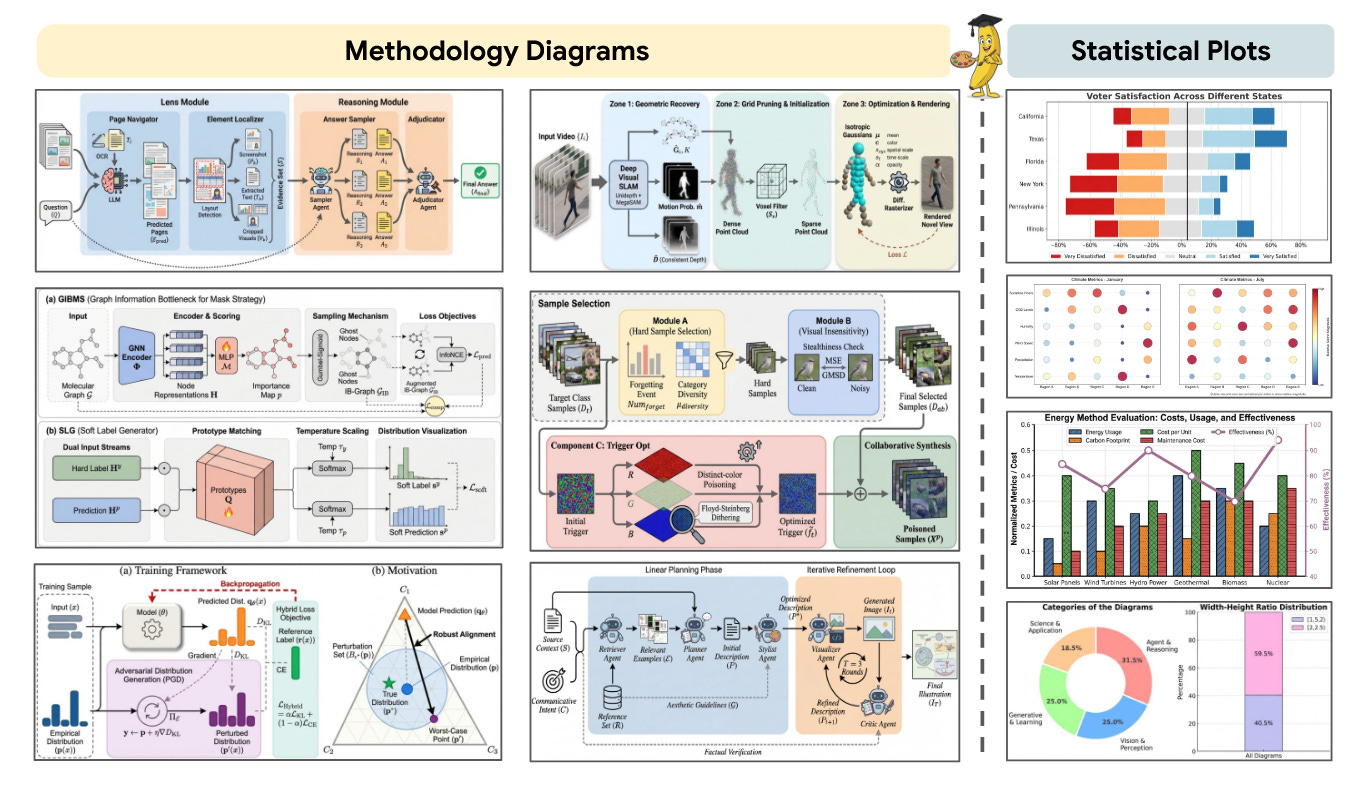
Ejemplos de diagramas metodológicos y gráficos estadísticos generados por PaperBanana, que muestran el potencial de automatizar la generación de ilustraciones académicas. CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding (2026‑02‑02).
Estudia hasta qué punto los modelos multimodales (MLLMs) pueden entender código cuando éste se representa como imagen, en lugar de texto tokenizado, con la idea de comprimir brutalmente el contexto manteniendo la semántica. Encuentran que los MLLMs son capaces de razonar sobre código con compresiones de hasta 8× en tokens, aprovechando pistas visuales (syntax highlighting, layout) y que tareas como detención de clones son sorprendentemente robustas a esta compresión, llegando a igualar o superar el texto plano en algunos regímenes. Implicación clara para agentes de código de largo contexto: parte del contexto podría pasar por la rama visual para abaratar inferencia.Fuente: [clic aquí]
Vision-DeepResearch & Vision-DeepResearch Benchmark (2026‑01‑29 / 2026‑02‑02).
Dos trabajos complementarios que empujan la frontera de los agentes de “deep research” multimodal. El primero, Vision-DeepResearch, propone un nuevo paradigma donde un MLLM realiza búsqueda visual y textual multi‑turn, multi‑entidad y multi‑escala sobre motores reales, con decenas de pasos de razonamiento y cientos de interacciones, internalizando esta capacidad vía supervisión y RL; reporta mejoras sustanciales frente a pipelines basados en modelos cerrados (GPT‑5, Gemini 2.5, Claude Sonnet, etc.). El segundo, Vision-DeepResearch Benchmark (VDR‑Bench), introduce un benchmark de 2.000 preguntas VQA cuidadosamente curadas para evaluar búsqueda visual/textual realista, mostrando que un workflow sencillo de búsqueda recortada multi‑round mejora notablemente el rendimiento de los MLLMs actuales.Fuentes: [clic aquí] [aquí]
FASA: Frequency-aware Sparse Attention (2026‑02‑05).
Propone FASA, un método de atención dispersa que ataca directamente el cuello de botella del KV‑cache en contextos largos. A partir de un análisis de RoPE, identifican sparsidad funcional a nivel de “frequency‑chunks”, encontrando que un pequeño subconjunto dominante de frecuencias captura casi toda la información relevante; eso les permite predecir dinámicamente qué tokens son importantes y podar agresivamente el resto sin perder precisión. En benchmarks de contexto largo como LongBench‑V1 y razonamiento tipo CoT, FASA alcanza prácticamente el rendimiento full‑KV manteniendo solo 256 tokens y consigue 2,56× de speedup usando un 18,9 % de la caché en AIME24.Fuente: [clic aquí]
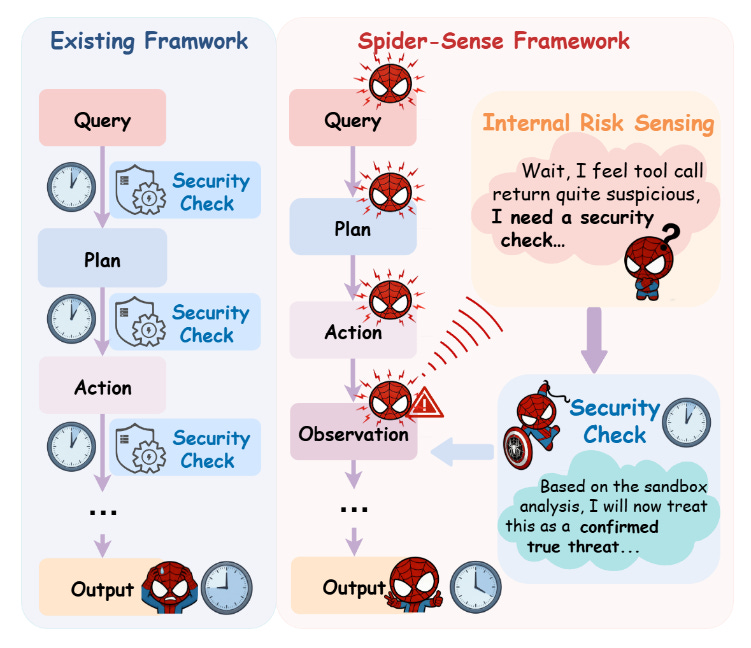
Spider-Sense: Intrinsic Risk Sensing for Efficient Agent Defense with Hierarchical Adaptive Screening (2026‑02‑05).
Presenta Spider‑Sense, un marco de defensa para agentes basado en sensado intrínseco de riesgo y screening jerárquico adaptativo. En lugar de chequeos de seguridad obligatorios en puntos fijos del ciclo del agente, proponen un enfoque event‑driven, donde el propio agente mantiene una “vigilancia latente” y sólo activa defensas cuando detecta señales de riesgo. Una vez activado, combina un filtro ligero basado en similitud para patrones conocidos con razonamiento más profundo para casos ambiguos, evitando depender de modelos externos. Introducen además S^2Bench, un benchmark de seguridad con ejecuciones reales de herramientas y ataques multi‑fase, donde muestran que Spider‑Sense reduce significativamente el Attack Success Rate y el False Positive Rate con apenas un ~8,3 % de sobrecarga en latencia.Fuente: [clic aquí]
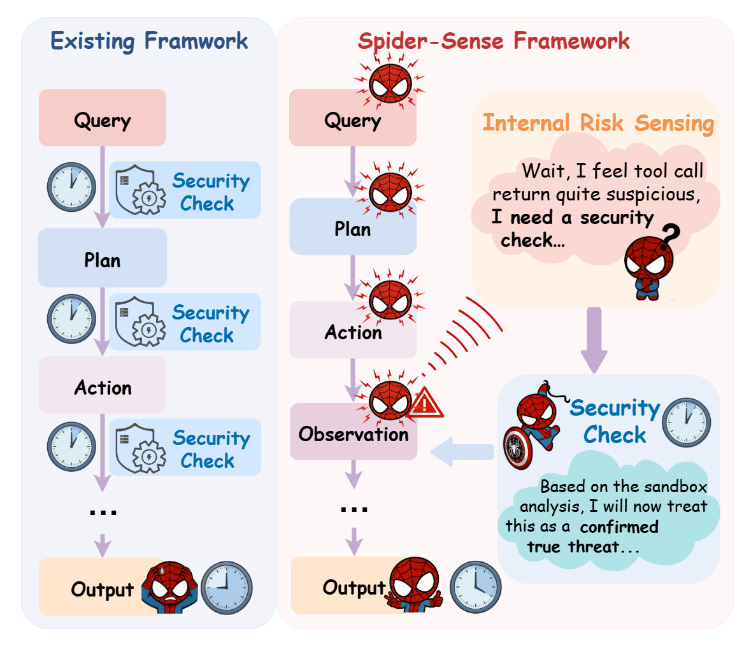
Comparación entre el marco existente y el marco SPIDER-SENSE. El enfoque actual se basa en comprobaciones de seguridad externas repetitivas y forzadas en cada etapa, lo que genera una alta latencia. Por el contrario, SPIDER-SENSE utiliza un conocimiento proactivo y endógeno del riesgo para activar dinámicamente análisis específicos solo cuando se detectan anomalías (como resultados sospechosos de la herramienta).
Modelos de IA Interesantes
GPT‑5.3‑Codex (OpenAI).
Modelo agentico de coding y uso del ordenador que busca ser el motor generalista para agentes desarrolladores: buen rendimiento en benchmarks exigentes (SWE‑Bench Pro, Terminal‑Bench 2.0, OSWorld, GDPval), integración nativa con harnesses como el Codex App Server y una system card que lo sitúa explícitamente en la categoría de alta capacidad en ciberseguridad.Fuentes: [clic aquí] [aquí]
Claude Opus 4.6 (Anthropic).
Nueva versión frontier de Claude con mejoras claras en coding, razonamiento con herramientas y tareas financieras, ventanas de hasta 1M tokens, mecanismos de esfuerzo adaptativo y compresión de contexto, y soporte mejorado para equipos de agentes en Claude Code.Fuente: [clic aquí]
Nemotron ColEmbed V2 (NVIDIA / Hugging Face).
Familia de modelos de embeddings multimodales de interacción tardía (3B/4B/8B) que lideran el benchmark ViDoRe V3 en recuperación de documentos visuales, pensados para RAG multimodal, buscadores de PDFs con gráficos y asistentes que deben combinar texto con diagramas o imágenes.Fuente: [clic aquí]
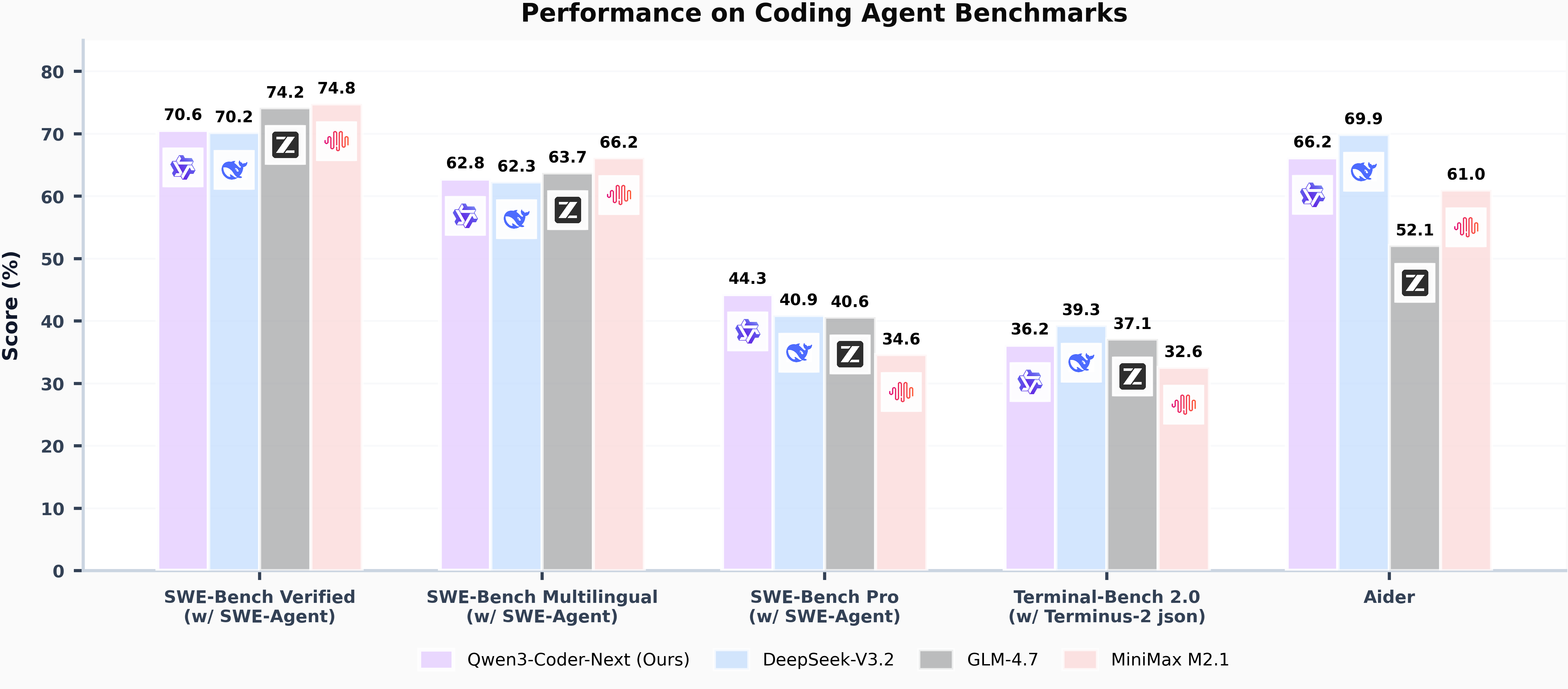
Qwen3-Coder-Next (Qwen).
Modelo abierto para agentes de código y desarrollo local, con arquitectura MoE de 80B parámetros totales pero sólo 3B activados, contexto nativo de hasta 256K tokens y un entrenamiento centrado en razonamiento a largo plazo, uso complejo de herramientas y recuperación tras fallos de ejecución, pensado para integrarse bien con harnesses como Claude Code, Qwen Code, Cline o editores similares.Fuente: [clic aquí]

Comparativa de Qwen3-Coder-Next con otros modelos open-source GLM-OCR (Z.ai).
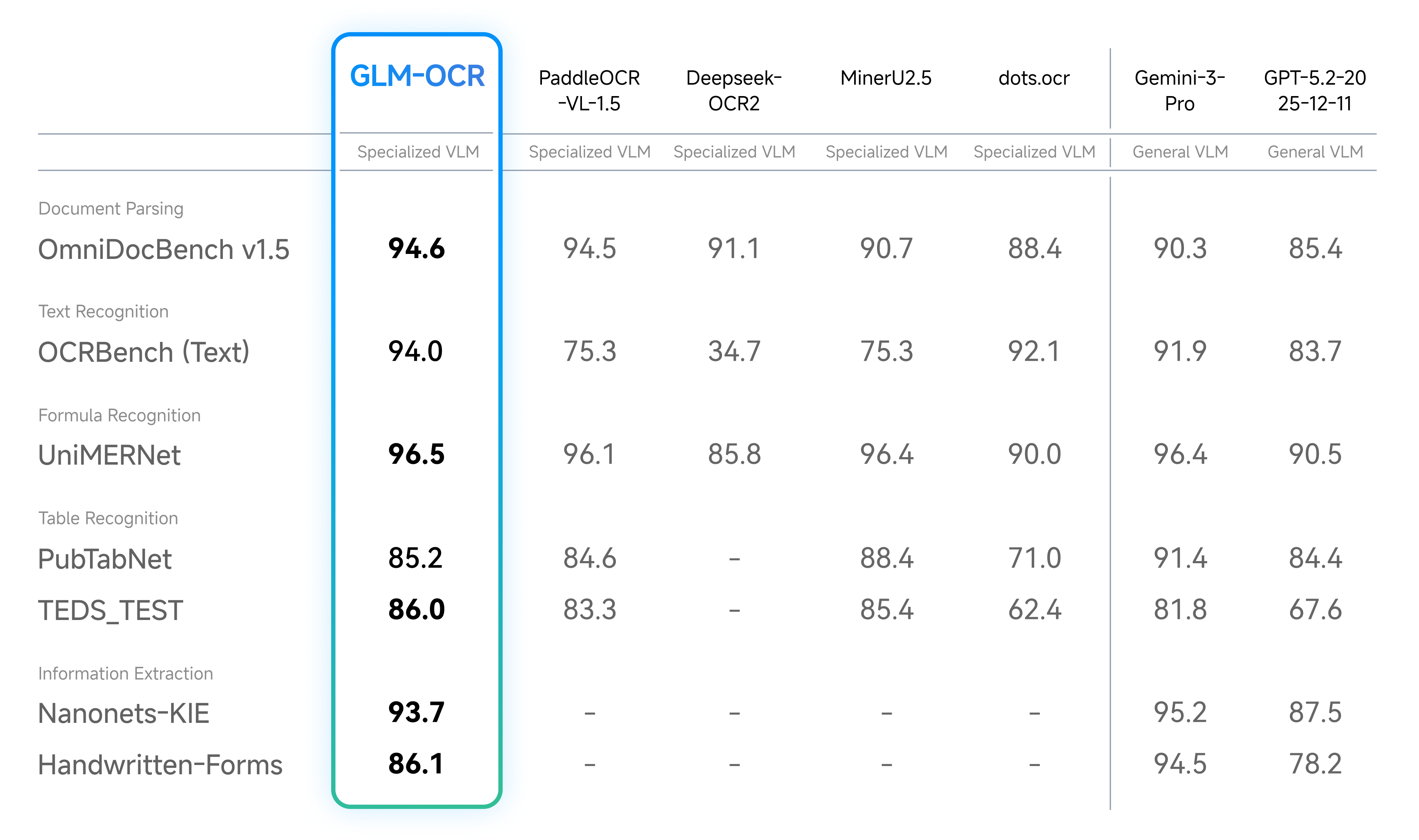
Modelo multimodal de OCR para comprensión de documentos complejos, basado en la arquitectura GLM‑V (encoder‑decoder) con ~0,9B parámetros, que combina un visual encoder CogViT, análisis de layout (PP‑DocLayout‑V3) y reconocimiento paralelo para alcanzar estado del arte en OmniDocBench V1.5 y otros benchmarks de documentos, con inferencia eficiente vía vLLM, SGLang y Ollama.Fuente: [clic aquí]
Utilidades para builders
System Prompts Leaks.
Colección mantenida por la comunidad de system prompts y mensajes de desarrollador extraídos de chatbots populares (ChatGPT, Claude, Gemini, etc.), útil para investigar cómo se configuran estos sistemas, hacer red‑teaming o diseñar tus propias plantillas de sistema con más contexto.Fuente: [clic aquí]
CodexBar.
Pequeña app de barra de menú para macOS 14+ (con CLI también para Linux) que mantiene siempre visibles tus límites y uso de Codex, Claude, Cursor, Gemini, Copilot y otros proveedores, ideal si trabajas con varios agentes/copilots y quieres controlar gasto, ventanas temporales y cuotas sin entrar a cada panel web.Fuente: [clic aquí]
vLLM‑Omni v0.14.0.
Nueva versión del servidor vLLM‑Omni que trae mejoras importantes en generación multimodal (imagen/vídeo), audio/TTS, eficiencia de ejecución distribuida, soporte de hardware (GPU/ROCm/NPU/XPU) y APIs de serving, muy interesante si estás montando agentes multimodales o pipelines de difusión con altos requisitos de throughput.Fuente: [clic aquí]
Algunas Noticias Breves de IA
Últimos días para unirte al Desafío ALIA.
Colabora en alinear ALIA 40B Instruido para construir una IA pública más segura, igualitaria e inclusiva: ya hay más de 400 personas inscritas, se sortean entradas Xpro para Talent Arena en el MWC26 y sólo necesitas un ordenador; organizado por el Ministerio para la Transformación Digital y de la Función Pública con la colaboración de Talent Arena (Mobile World Capital Barcelona), Amazon Web Services (AWS) y Multiverse Computing.Fuente: [clic aquí]
Agent Trace: especificación abierta para rastrear código generado por agentes.
Agent Trace propone una especificación abierta y neutral de proveedor para registrar contribuciones de IA junto a las humanas en repositorios con control de versiones, con trazas a nivel de archivo y rango de líneas, soporte para distintos VCS y una implementación de referencia pensada para integrarse en copilots y agentes de coding.Fuente: [clic aquí]