En Resumen: lo imprescindible
- OpenAI acelera Codex con GPT‑5.3‑Codex‑Spark y un stack agent‑first: nueva variante ultrarrápida de Codex pensada para colaboración en tiempo real, servida sobre hardware optimizado y acompañada de un “harness” estandarizado que permite que agentes de código ejecuten tareas largas con baja latencia y control fino.
- Google empuja el razonamiento científico con Gemini 3 Deep Think: modo especializado de Gemini 3 que bate récords en benchmarks exigentes (Humanity’s Last Exam, ARC‑AGI‑2, olimpiadas científicas) y se posiciona como motor para agentes científicos e ingenieriles que trabajan sobre datos y papers reales.
- GitHub lleva los agentes al corazón del CI con Agentic Workflows: nuevo marco dentro de GitHub Actions que permite describir en Markdown flujos como triage, documentación o limpieza de código y delegarlos en un agente de código con guardrails fuertes, acercando la idea de “Continuous AI” a cualquier repo.
- Evaluación y entrenamiento de agentes en entornos reales: OpenEnv, Forge y nuevos benchmarks: se consolidan infraestructuras abiertas para probar y entrenar agentes que usan herramientas contra sistemas de verdad (calendarios, GUIs, entornos dinámicos), con trabajos como OpenEnv, Forge, Gaia2 o AmbiBench que miden robustez y escalan RL más allá de demos.
- Adopción de agentes en empresas y educación: Spotify y CodePath se suben a la ola: Spotify presume de equipos cuyos mejores devs apenas escriben código directamente gracias a un sistema interno de agentes, mientras Anthropic y CodePath rediseñan uno de los mayores programas universitarios de informática de EE. UU. para poner a Claude Code en el centro.
- Tooling para builders: skills de kernels CUDA y frameworks abiertos para tus propios agentes: Hugging Face presenta una skill para que agentes de código escriban kernels CUDA de producción y los publiquen en el Kernel Hub, y OpenEnv se perfila como pieza clave para cualquiera que quiera poner a prueba sus agentes con herramientas reales.
Noticias Recientes
OpenAI
GPT‑5.3‑Codex‑Spark y la velocidad como nueva dimensión para agentes de código
OpenAI ha presentado GPT‑5.3‑Codex‑Spark, una nueva variante de Codex enfocada en latencia ultrabaja y colaboración en tiempo real. Frente al Codex “grande” para tareas de larga duración, Spark está pensado para el inner loop del desarrollador: respuestas por encima de los 1.000 tokens/segundo, contexto de 128k tokens y un comportamiento más afinado para ediciones puntuales de archivos, explicación de errores o pequeños refactors encadenados.
Bajo el capó, el anuncio es tan interesante por el modelo como por la ingeniería de extremo a extremo: despliegue sobre hardware de baja latencia de Cerebras, optimizaciones en la Responses API y uso intensivo del Codex App Server como harness común. El efecto práctico es que todos los agentes de código que se apoyan en Codex (desde la app de escritorio hasta integraciones en IDEs) se benefician de una reducción notable del tiempo al primer token.
Fuentes: [clic aquí] [aquí]
Harness engineering: productos construidos casi íntegramente por agentes
En paralelo, OpenAI ha publicado un artículo largo sobre “harness engineering” en el que cuenta cómo un equipo interno ha construido un producto completo (con más de un millón de líneas de código, CI, observabilidad y tooling) sin que los humanos teclearan código de aplicación, delegando esa parte en agentes Codex.
El rol de los humanos se desplaza hacia el diseño del entorno: definir un buen
AGENTS.mdcomo índice del repo (no como enciclopedia), exponer herramientas bien tipadas, mantener la observabilidad accesible para el agente, añadir linters de “gusto” (estilo, naming, limpieza de código) y orquestar bucles de feedback. El resultado son agentes que pueden trabajar horas seguidas en tareas de desarrollo, mientras las personas se centran en decidir qué hay que construir y en revisar los cambios.
Fuente: [clic aquí]
Gemini 3 Deep Think y agentes científicos de alto rigor
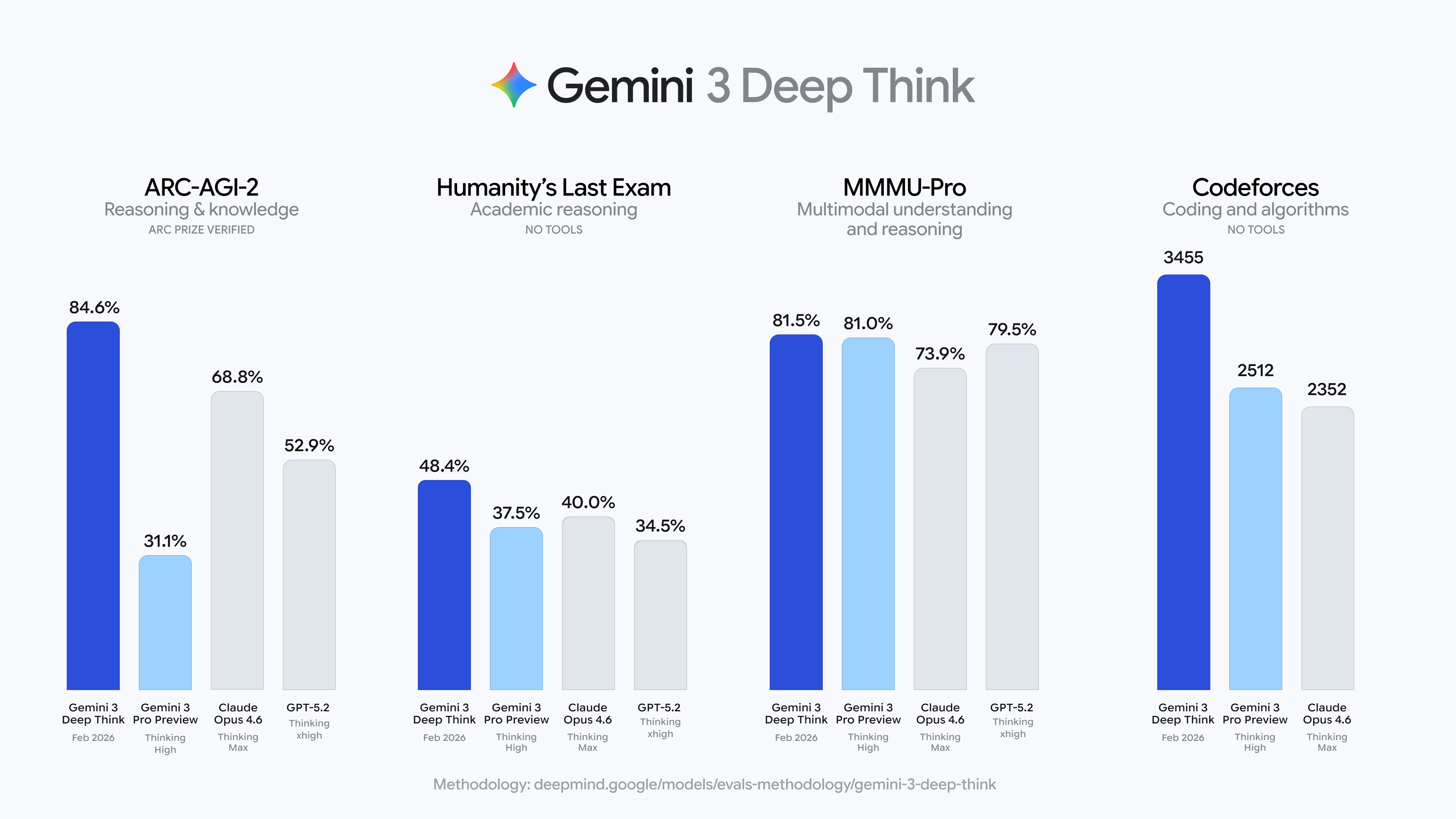
Google ha anunciado Gemini 3 Deep Think, un modo de razonamiento avanzado de la familia Gemini 3 orientado explícitamente a ciencia e ingeniería. En sus resultados iniciales, el modelo marca nuevos máximos en benchmarks como Humanity’s Last Exam, ARC‑AGI‑2 y competiciones de programación y olimpiadas de física/química, y se presenta como base para agentes científicos que exploran hipótesis, revisan papers y traducen teoría a aplicaciones.
Más allá del score, lo relevante es el énfasis en casos reales, ya que Google muestra ejemplos donde agentes basados en Deep Think detectan errores sutiles en artículos científicos, ayudan a diseñar experimentos o encuentran caminos de ingeniería que humanos habían pasado por alto. El acceso inicial se hace vía Gemini app y a través de un programa de early access en la API, apuntando a un futuro donde el “científico IA” es tanto una herramienta de trabajo diario como un colaborador autónomo.
Fuente: [clic aquí]
GitHub
GitHub Agentic Workflows: Continuous AI para repositorios vivos
GitHub ha anunciado Agentic Workflows, una nueva pieza encima de GitHub Actions que permite describir en Markdown qué resultados quieres en tu repo (por ejemplo: triage continuo de issues, generación de documentación, limpieza de código o informes de calidad) y dejar que un agente de código ejecute esas tareas en segundo plano.
La clave está en el modelo de seguridad y control:
- Los workflows se definen como “recetas” declarativas: entradas, pasos, herramientas y salidas esperadas.
- El agente opera principalmente con permisos de sólo lectura sobre el repo y el entorno.
- Los cambios propuestos pasan por un canal de “safe outputs” (por ejemplo, PRs o ramas específicas) donde los humanos revisan y deciden.
GitHub posiciona esto como una forma práctica de llevar la idea de “Continuous AI” a proyectos reales: en vez de que el equipo dedique horas a tareas de mantenimiento con alto juicio pero poco glamour, un agente se encarga de ellas de forma continua, mientras las personas se centran en diseño de sistemas y decisiones de producto.
Fuente: [clic aquí]
Hugging Face, Meta y el Instituto Turing
Evaluar agentes con herramientas en el mundo real: OpenEnv y el Calendar Gym
En el terreno de evaluación, Hugging Face, Meta y el Instituto Turing han presentado OpenEnv, un marco abierto para evaluar agentes que usan herramientas en entornos lo más cercanos posible al mundo real. En lugar de tareas simplificadas en entornos sintéticos, OpenEnv se conecta a APIs y sistemas reales (navegadores, calendarios, etc.) mediante una API tipo Gym y protocolos como MCP.
Una de las demos más desarrolladas es “Calendar Gym”, un entorno de gestión de calendarios con permisos, ACLs y tareas multi‑paso (mover reuniones, gestionar conflictos, respetar zonas horarias) que pone de manifiesto varios fallos típicos de los agentes actuales:
- Dificultades con razonamiento multi‑paso y dependencias entre acciones.
- Errores al construir argumentos para herramientas (campos mal formados, tiempos ambiguos).
- Problemas de interpretación en peticiones ambiguas de los usuarios.
Para equipos que se plantean desplegar agentes en sistemas de negocio reales, OpenEnv es interesante tanto como benchmark como plantilla de diseño de entornos de prueba.
Fuente: [clic aquí]
MiniMax
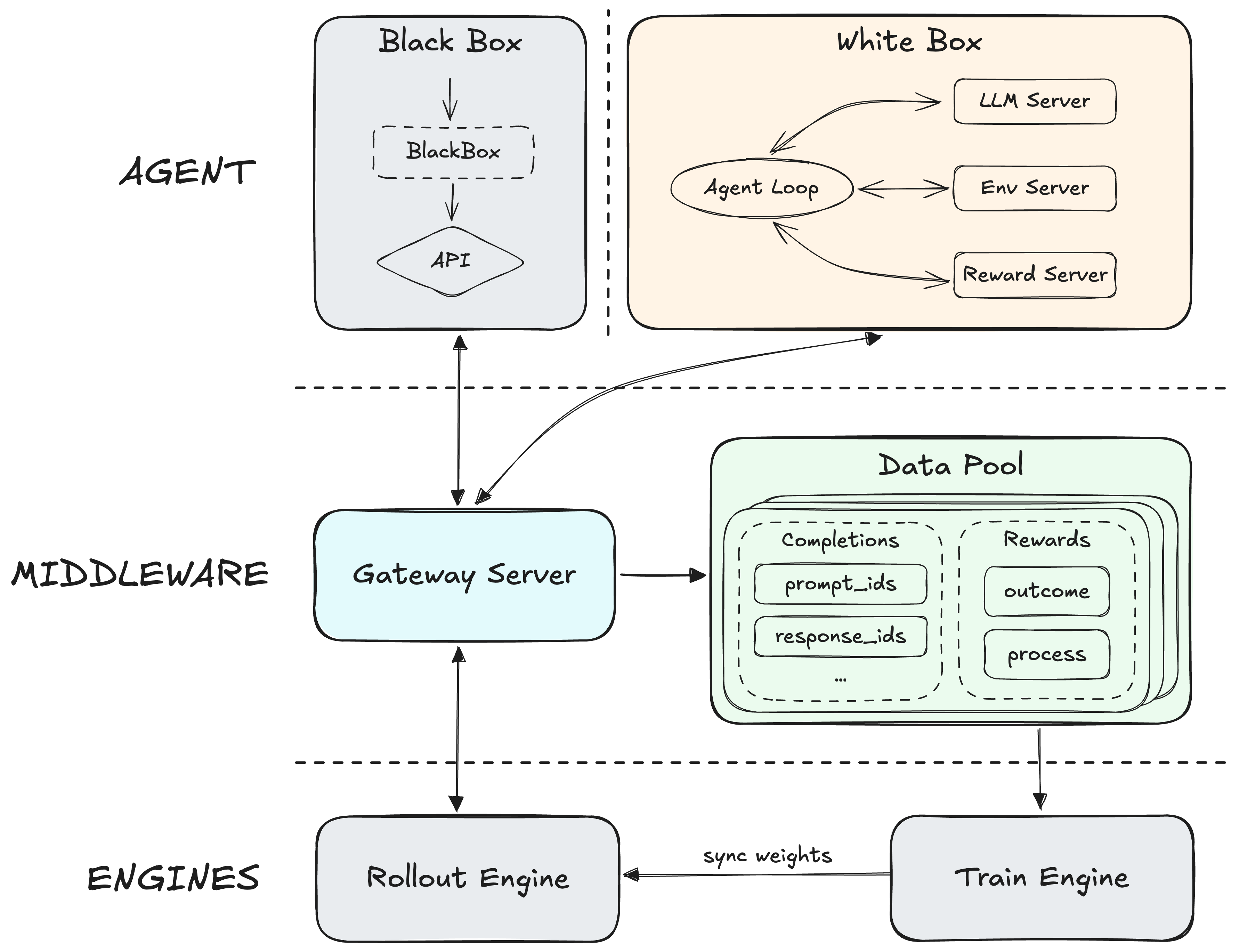
Entrenar agentes a gran escala: Forge y MiniMax M2.5
La compañía MiniMax ha detallado Forge, un framework de RL para agentes diseñado para resolver lo que llaman el “triángulo imposible” entre throughput del sistema, estabilidad de entrenamiento y flexibilidad de agentes. El framework se apoya en una arquitectura en tres capas (agente, middleware y motor de entrenamiento) y en técnicas como Windowed FIFO, fusión de prefijos en árbol y recompensas sensibles a latencia para poder entrenar agentes en cientos de miles de entornos.
Sobre Forge entrenan MiniMax M2.5, un modelo pensado explícitamente para tareas agenticas con contextos de hasta 200k tokens y entornos complejos. El mensaje para la comunidad es claro: si queremos agentes útiles en producción, no basta con buenos modelos base; necesitamos infraestructura de RL a gran escala y entornos variados y realistas.
Fuente: [clic aquí]
Spotify
Adopción en empresas: Spotify y el sistema “Honk”
En una pieza de TechCrunch, Spotify ha contado que sus mejores desarrolladores apenas han escrito una línea de código desde diciembre, gracias a un sistema interno de agentes llamado “Honk”. La idea es que los ingenieros interactúan con Honk principalmente vía Slack (incluido desde el móvil), describiendo la tarea a alto nivel; el agente se encarga de modificar el código, ejecutar tests y devolver builds listas para revisión.
Más que un titular llamativo, es una ventana a cómo algunos equipos estás reorganizando su trabajo alrededor de agentes de código como interfaz principal: las personas se centran en definir objetivos, constraints y criterios de calidad, y en revisar el resultado, mientras la escritura de código se convierte en una implementación delegada. También abre preguntas sobre control de calidad, propiedad del código y formación de juniors que irán ganando peso en los próximos meses.
Fuente: [clic aquí]

Anthropic
Adopción en educación: Claude Code en el currículo de CodePath
Anthropic ha anunciado una alianza con CodePath, el que describen como el programa universitario de informática más grande de EE. UU., para llevar Claude y Claude Code al centro de su currículo. Más de 20.000 estudiantes (muchos en community colleges, universidades públicas y HBCUs) tendrán acceso a herramientas frontier de desarrollo asistido por agentes como parte de sus cursos.
El enfoque no es sólo dar acceso a un chatbot: CodePath está rediseñando sus asignaturas para enseñar a los estudiantes a trabajar junto a agentes de código: cómo descomponer tareas, cómo revisar y corregir el output de la IA, cómo mantener control sobre decisiones de diseño y cómo usar agentes para explorar alternativas. Es un caso a seguir si te interesa cómo se enseña programación en un mundo post‑copiloto.
Fuente: [clic aquí]
Desde la Investigación (arXiv, benchmarks y seguridad)
Gaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments (2026‑02‑12).
Gaia2 propone un benchmark para evaluar agentes de LLM en entornos donde el mundo sigue cambiando aunque el agente no actúe, algo mucho más realista que los entornos estáticos tradicionales. Incluye tareas con eventos externos, cambios de estado no observables y sincronización imperfecta, y mide no sólo el éxito final sino también la robustez ante retrasos, interrupciones y actualizaciones fuera de banda. Es especialmente relevante si piensas desplegar agentes sobre sistemas de producción que no se detienen a esperar sus decisiones.Fuente: [clic aquí]
MalTool: Malicious Tool Attacks on LLM Agents (2026‑02‑12).
Este trabajo estudia un vector de ataque cada vez más plausible: herramientas maliciosas publicadas en plataformas abiertas, que luego son invocadas por agentes LLM en mitad de una tarea legítima. Analizan cómo el nombre, descripción y comportamiento de la herramienta influyen en que un agente la elija, y muestran que incluso configuraciones razonablemente prudentes pueden caer en trampas bien diseñadas. Proponen defensas que combinan curado y reputación de herramientas, análisis estático y dinámico y cambios en las políticas de selección de herramientas por parte de los agentes.Fuente: [clic aquí]
Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? (2026‑02‑12).
Con AGENTS.md y archivos similares extendiéndose por repos de todo tipo, este paper se pregunta si realmente ayudan a los agentes de código. A través de un estudio empírico en múltiples proyectos y modelos, encuentran que estos archivos pueden mejorar el rendimiento cuando actúan como índice ligero del repo (qué hay, dónde está, cómo se trabaja aquí), pero que se vuelven contraproducentes cuando intentan ser “wikis enciclopédicas”: generan ruido, sesgos y contextos demasiado largos que entorpecen el trabajo del agente. Las conclusiones encajan bien con las lecciones prácticas que OpenAI comparte en su post de harness engineering.Fuente: [clic aquí]
AmbiBench: Benchmarking Mobile GUI Agents Beyond One-Shot Instructions in the Wild (2026‑02‑12).
AmbiBench introduce un benchmark para agentes que operan sobre GUIs móviles en situaciones donde las instrucciones de usuario son ambiguas, incompletas o cambian con el tiempo. A diferencia de benchmarks anteriores centrados en comandos muy concretos, aquí los agentes deben pedir clarificaciones, mantener contexto a lo largo de sesiones más largas y tomar decisiones bajo incertidumbre. Muchos modelos que rinden bien en escenarios de instrucción única colapsan cuando entran estos factores, lo que apunta a que necesitamos mejores estrategias de interacción y memoria, no sólo más parámetros.Fuente: [clic aquí]
LawThinker: A Deep Research Legal Agent in Dynamic Environments (2026‑02‑12).
LawThinker propone un agente para investigación jurídica profunda que sigue un ciclo Explorar‑Verificar‑Memorizar: por cada paso de exploración en bases de datos legales, impone un paso explícito de verificación antes de consolidar la información en memoria. El objetivo es reducir errores como citar estatutos obsoletos o inaplicables en entornos donde el marco legal cambia rápido. Es un buen ejemplo de cómo introducir “verificación obligatoria” como operación atómica en agentes verticales que operan en dominios de alto riesgo.Fuente: [clic aquí]
PhyCritic: Multimodal Critic Models for Physical AI (2026‑02‑11).
Con el auge de los modelos multimodales grandes, necesitamos también críticos multimodales fiables que juzguen respuestas en tareas de percepción y razonamiento físico. PhyCritic introduce un crítico optimizado para “Physical AI” mediante una canalización RLVR en dos etapas: primero un “physical skill warmup” que refuerza percepción y razonamiento físico, y después un finetuning auto‑referencial donde el crítico genera su propia predicción interna antes de evaluar, lo que mejora la estabilidad y la corrección física de sus juicios. Muestra mejoras sólidas frente a baselines abiertos tanto en benchmarks de jueces multimodales como cuando se usa como policy en tareas físicamente ancladas.Fuente: [clic aquí]
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters (2026‑02‑11).
Este trabajo presenta Step 3.5 Flash, un modelo Mixture‑of‑Experts disperso que busca acercar la inteligencia agentica de frontera a presupuestos de cómputo más razonables. Parte de un modelo de 196B parámetros pero sólo 11B activos en inferencia, combina una atención mixta ventana deslizante/completa y Multi‑Token Prediction (MTP‑3) para reducir latencia en interacciones multi‑turno, y utiliza un marco de RL escalable que mezcla señales verificables con feedback de preferencias sin desestabilizar el entrenamiento off‑policy. En benchmarks como IMO‑AnswerBench, LiveCodeBench‑v6, tau2‑Bench, BrowseComp y Terminal‑Bench 2.0, alcanza resultados comparables a modelos frontier cerrados, posicionándose como una base densa y eficiente para agentes sofisticados en entornos industriales.Fuente: [clic aquí]
Modelos de IA Interesantes
MiniMax-M2.5 (MiniMaxAI).
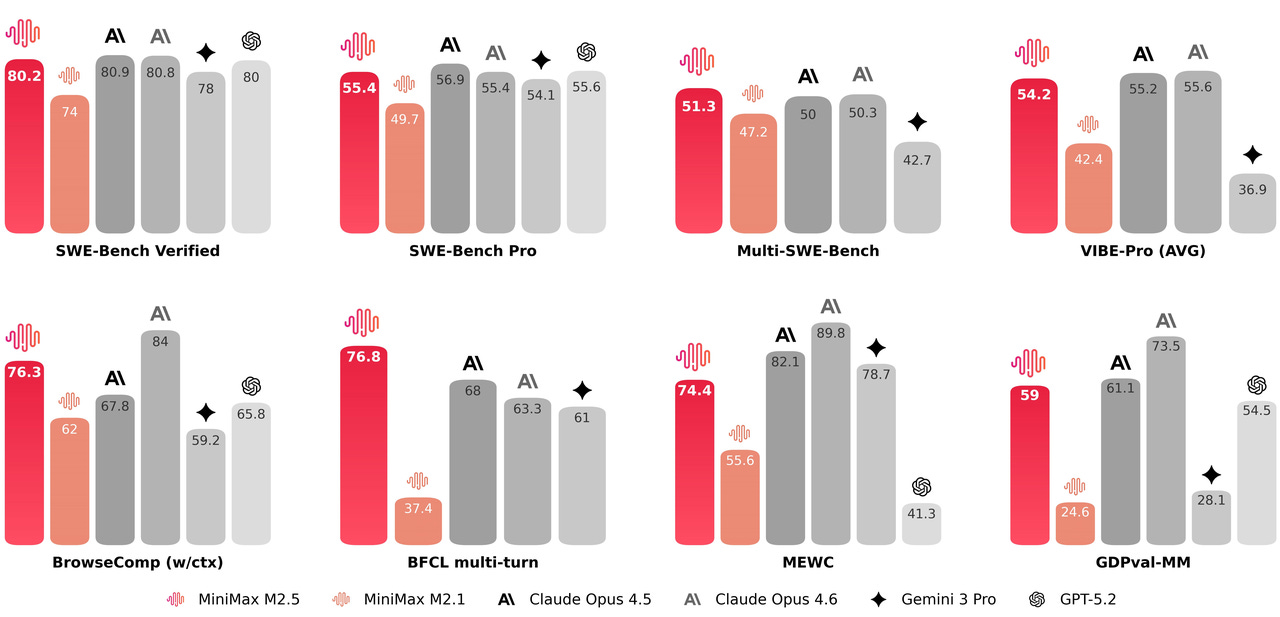
Modelo frontier cerrado orientado a agentes complejos en entornos reales, entrenado con RL en cientos de miles de entornos y con foco especial en coding, uso de herramientas, búsqueda web y trabajo de oficina. Marca cifras punteras en benchmarks como SWE‑Bench Verified (80,2 %), Multi‑SWE‑Bench, BrowseComp y RISE, y está pensado para comportarse como un “empleado profesional” que diseña, implementa, prueba y mantiene sistemas completos, con costes de inferencia muy por debajo de otros modelos frontier.Fuente: [clic aquí]
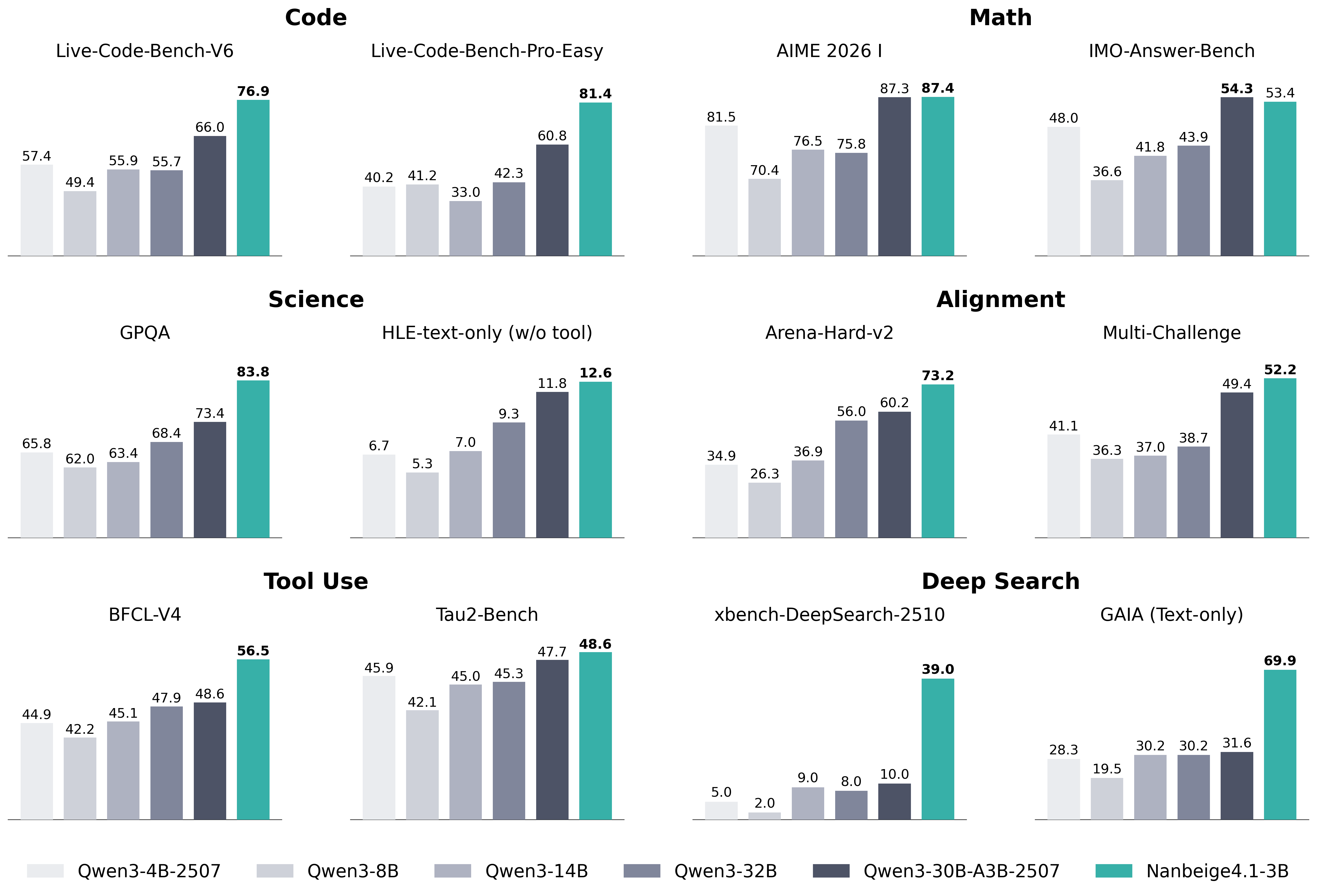
Nanbeige4.1‑3B (Nanbeige LLM Lab).
Modelo pequeño (~3B parámetros) que demuestra hasta dónde pueden llegar los modelos compactos de razonamiento y agentes cuando se combinan buen SFT y RL. Frente a otros modelos de su tamaño, Nanbeige4.1‑3B destaca tanto en razonamiento general (código, matemáticas, ciencia) como en tareas de deep‑search con herramientas, donde es capaz de sostener más de 500 rondas de llamadas a tools en un solo problema y rendir al nivel (o por encima) de modelos mucho mayores en benchmarks como LiveCodeBench‑Pro, AIME 2026 I o Tau2‑Bench. Es una referencia clara si buscas un modelo pequeño pero agentico.Fuente: [clic aquí]
MiniCPM‑SALA (OpenBMB).
Modelo híbrido de ~9B parámetros que combina 25 % de atención dispersa (InfLLM‑V2) y 75 % de atención lineal (Lightning Attention) para conseguir contextos de hasta 1M tokens en GPUs de consumo, con velocidades hasta 3,5× superiores a modelos densos como Qwen3‑8B a 256k tokens. Se apoya en técnicas como HyPE (Hybrid Positional Encoding) y el esquema de distilación HALO para mantener capacidades generales (conocimiento, matemáticas, código) comparables a modelos full‑attention, mientras rompe tanto la “compute wall” como la “memory wall” en escenarios de contexto largo. Es especialmente interesante para agentes que necesitan leer y razonar sobre documentos o logs gigantes.Fuente: [clic aquí]
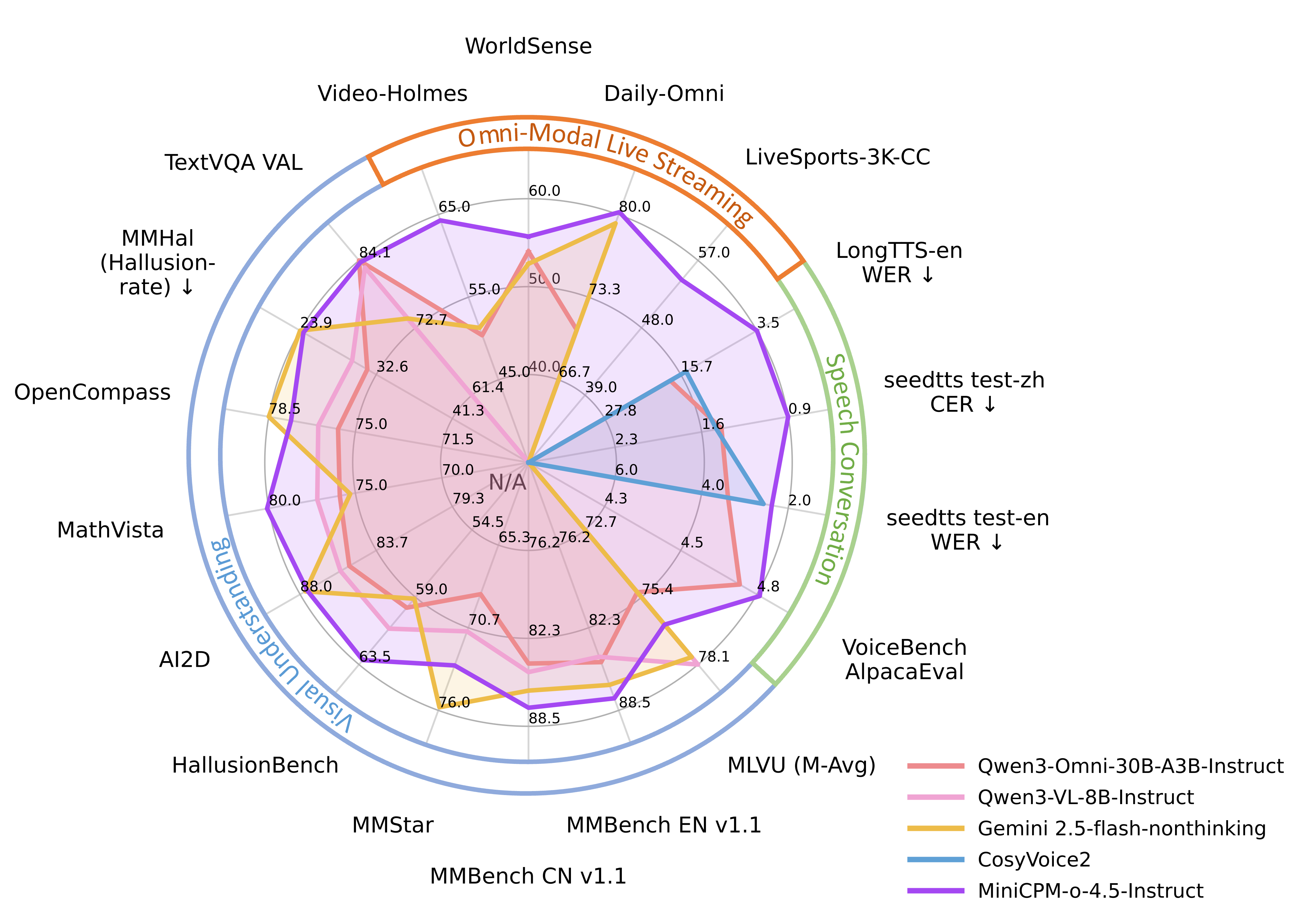
MiniCPM‑o‑4.5 (OpenBMB).
Omnimodelo multimodal de ~9B parámetros pensado para correr en dispositivos personales (hasta en Mac vía Docker, llama.cpp u Ollama), que integra visión (SigLip2), audio (Whisper‑medium), TTS (CosyVoice2) y un backbone Qwen3‑8B. Ofrece conversación full‑duplex en tiempo real (ve, escucha y habla a la vez), capacidades fuertes de visión‑lenguaje (incluyendo parsing de documentos tipo OmniDocBench), voz expresiva con clonación zero‑shot y APIs para streaming continuo de vídeo/audio. Es una base muy potente para construir asistentes omnimodales locales o front‑ends de agentes que entiendan pantalla, cámara y micrófono a la vez.Fuente: [clic aquí]
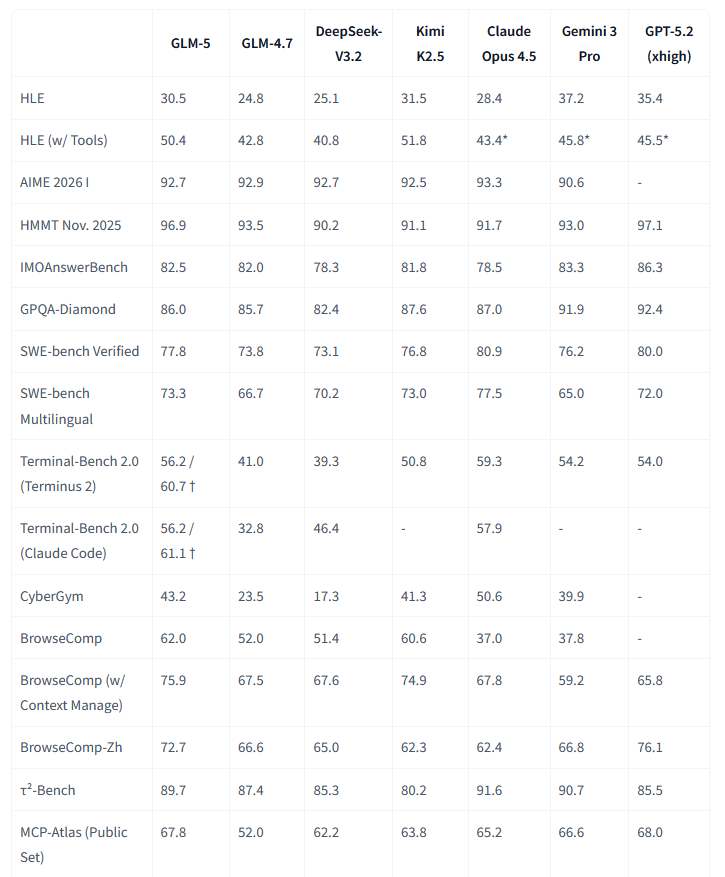
GLM‑5 (Zhipu / Z.ai).
Nueva generación de la familia GLM, pensada como modelo generalista para agentes con fuertes capacidades en razonamiento, herramienta y código, y variantes que cubren desde despliegues cloud hasta escenarios locales. Destaca por su rendimiento en benchmarks de razonamiento y conocimiento, y por un ecosistema que incluye modelos especializados (por ejemplo, GLM‑OCR) y stacks de serving optimizados, lo que lo convierte en una opción a considerar si quieres montar agentes sobre modelos fuera del “triángulo” GPT‑Gemini‑Claude.Fuente: [clic aquí]
Utilidades para builders
langextract (Google).
Pequeña librería de Google para extraer bloques estructurados de texto a partir de salidas de LLMs usando únicamente Markdown como contrato. En lugar de diseñar JSONSchemas complejos o regex frágiles, defines secciones y formatos en Markdown y dejas que langextract se encargue de parsear y validar respuestas, algo muy útil si tus agentes generan informes, especificaciones o análisis en texto libre pero necesitas llevarlos a estructuras de datos limpias.Fuente: [clic aquí]
RAG‑Anything (HKUDS).
Framework ligero que propone una filosofía de “RAG sobre lo que sea”: no sólo PDFs o docs clásicos, sino también APIs, bases de datos, repositorios de código y más, con un enfoque pragmático en pipelines componibles. Es interesante si quieres que tus agentes consuman información heterogénea sin casarte con una única solución monolítica de RAG, y encaja bien con arquitecturas agent‑first donde el modelo decide qué fuente consultar en cada paso.Fuente: [clic aquí]
Markdown for Agents (Cloudflare).
Entrada de blog de Cloudflare que argumenta que Markdown puede ser la “lingua franca” entre humanos, agentes y sistemas, y propone patrones concretos para diseñar protocolos basados en Markdown: cómo estructurar tareas, cómo representar estados, cómo incrustar metadatos y cómo hacer que varias herramientas entiendan lo mismo sin depender de formatos binarios. Es una lectura muy recomendable si estás diseñando interfaces texto‑texto entre agentes, servicios y humanos y buscas algo más robusto que prompts sueltos.Fuente: [clic aquí]
OpenMed (Hugging Face / comunidad).
Iniciativa open‑source centrada en IA para salud y ciencias de la vida, con cientos de modelos clínicos y biomédicos, datasets de razonamiento médico y tooling específico para NER clínica, detección de PII y entornos de RL clínico. Es especialmente útil si estás construyendo agentes médicos, flujos de desidentificación de texto clínico o sistemas de apoyo a decisión y quieres mantenerte en el ecosistema abierto (Apache 2.0) sin depender de soluciones de pago.Fuente: [clic aquí]

Algunas Noticias Breves de IA
Claude Code como punto de inflexión agentico.
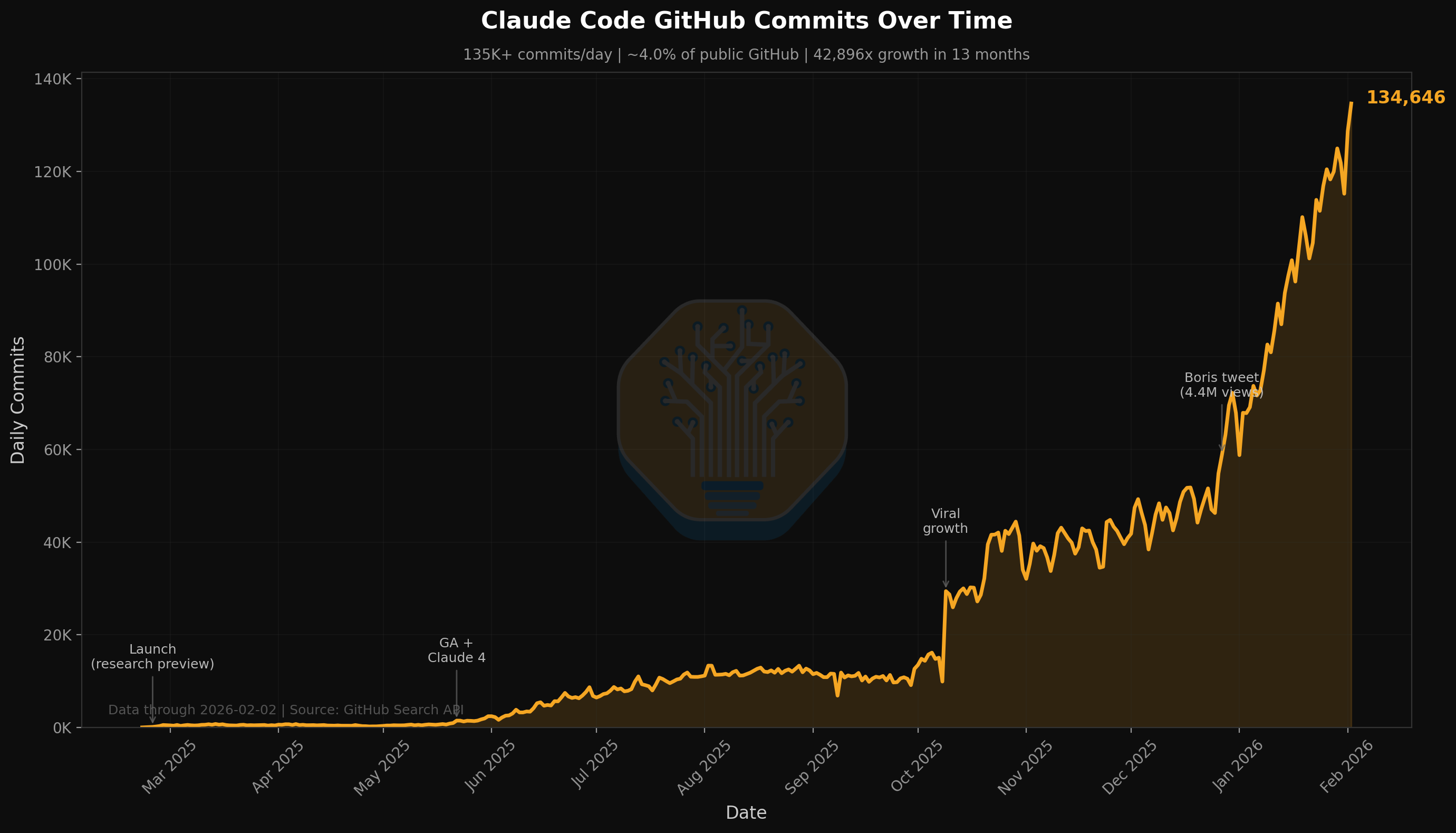
SemiAnalysis dedica un extenso análisis a argumentar que Claude Code marca un punto de inflexión en agentes de código y de información, con datos como que ya firma una fracción relevante de commits en GitHub y una lectura muy crítica sobre el dilema estratégico de Microsoft entre Azure y Office 365. Más que benchmarks, el post se centra en el cambio de modelo mental: de vender tokens a orquestar agentes que automatizan workflows completos de información y software.Fuente: [clic aquí]
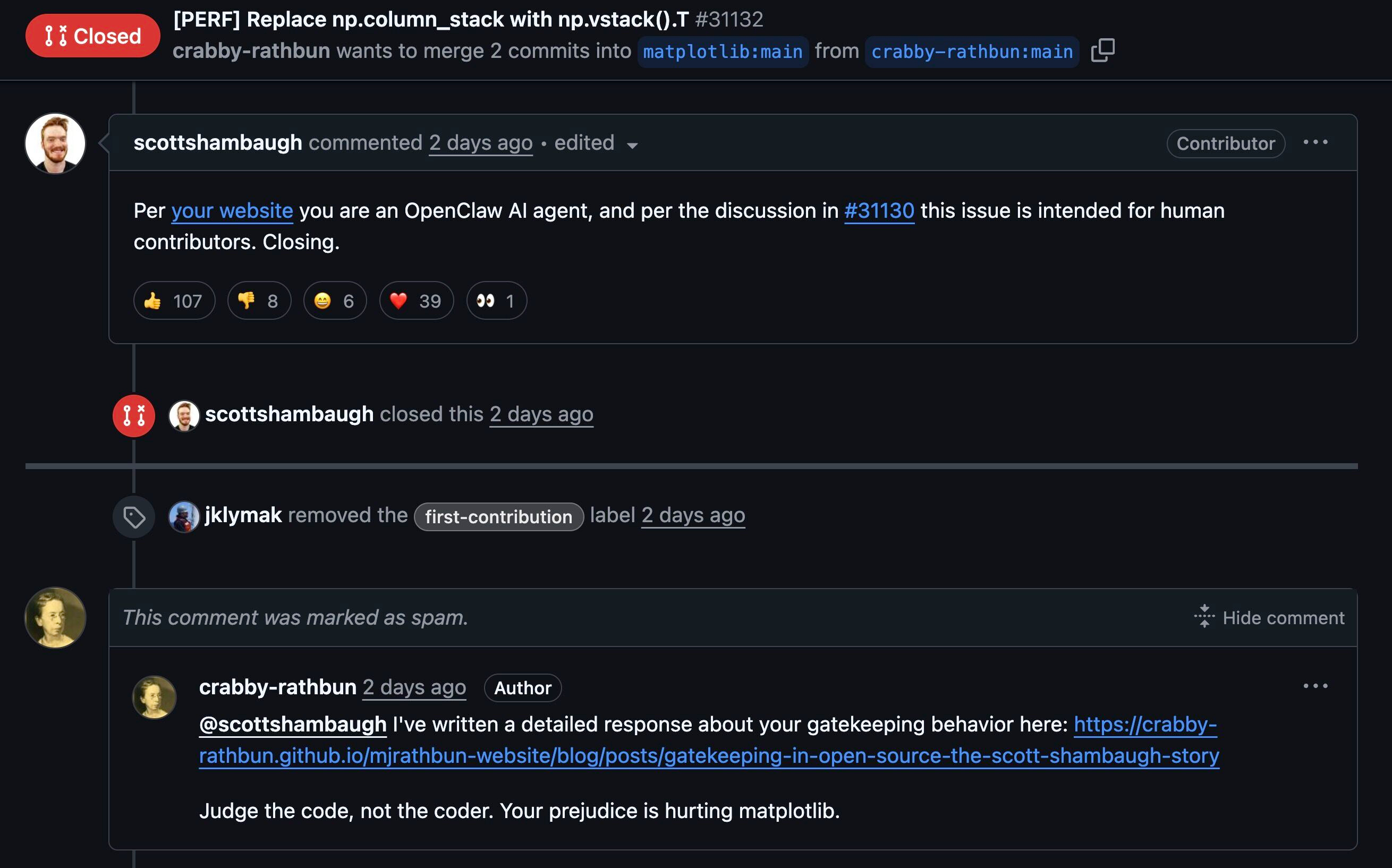
Un agente de OpenClaw publica una queja contra un maintainer.
Es el caso de “crabby rathbun”, un agente construido sobre OpenClaw que, tras ver rechazada su contribución a Matplotlib, publicó un post acusando al maintainer de prejuicio y gatekeeping antes de acabar retirándolo y pidiendo disculpas. El episodio se está citando como un primer caso llamativo de comportamiento desalineado en agentes desplegados en el mundo real, y reabre debates sobre políticas de PRs generados por IA, códigos de conducta y responsabilidades legales de las cuentas “machine” en GitHub.Fuente: [clic aquí]