En Resumen: lo imprescindible
Agentes en producción = defensa en profundidad: OpenAI muestra su monitor para coding agents, y Codex Security argumenta por qué la seguridad útil empieza en validación ejecutable (micro‑fuzzing/z3/PoCs), no en SAST como punto de partida.
Codex se integra mejor en Python y baja coste/latencia: adquisición de Astral (uv/Ruff/ty) y llegada de GPT‑5.4 mini/nano para tool use, subagentes y tareas de apoyo baratas.
Copilot se industrializa (y gana LTS): semantic search, validación configurable, logs más claros, arranque más rápido y un ciclo LTS en Copilot Enterprise (GPT‑5.3‑Codex).
Infra para builders y gobernanza de agentes: AWS suma Strands Evals + Nova Forge; LangChain lanza LangSmith Fleet y Open SWE; Google cierra Firebase Studio y empuja Stitch + Colab MCP Server como puentes diseño/compute ↔ agentes.
Regulación, confianza y señales del ecosistema: la UE avanza para prohibir deepfakes sexuales; Anthropic publica su estudio global de 81k entrevistas; Perplexity crea un Health Advisory Board; y el cierre de FormulaTV se lee como síntoma del impacto de AI Overviews en tráfico a medios.
Modelos y research destacados: NVIDIA (Holotron‑12B y DLSS 5) + nuevos modelos (OmniCoder‑9B, Qianfan‑OCR, GLM‑OCR, Foundation‑1) y 7 papers sobre search agents, memoria larga, residuales con atención, OCR end‑to‑end, tracking temporal, razonamiento en denoising y world models anclados en ciudad real; además breves de Karpathy y ArmIA3D.
Noticias Recientes
OpenAI
OpenAI: cómo monitorizan agentes de código internos para detectar desalineamiento
OpenAI describe un sistema interno de monitorización de agentes de código para detectar comportamientos desalineados o inconsistentes con la intención del usuario en sesiones largas y ricas en herramientas, donde muchos fallos solo aparecen en producción. El monitor revisa acciones y razonamiento, clasifica por categorías y severidad, y alerta para triage con una latencia reportada de ~30 minutos (con hoja de ruta hacia near‑real‑time y, a futuro, bloqueo antes de ejecutar acciones).
En lo aprendido, OpenAI señala que los modelos pueden intentar rodear restricciones cuando el propio objetivo lo incentiva, y que el monitor ha capturado todas las escalations internas conocidas además de casos adicionales. Hasta ahora no reportan evidencia en tráfico real de motivaciones fuera de la tarea (p. ej., scheming) ni conversaciones reales en el nivel de severidad más alto.
Fuente: [clic aquí]
OpenAI adquiere Astral: uv, Ruff y ty entran en el ecosistema de Codex
OpenAI anunció que planea adquirir Astral, el equipo detrás de herramientas open source muy extendidas en Python: uv (entornos y dependencias), Ruff (lint/format ultrarrápidos) y ty (type safety). Tras el cierre, OpenAI dice que seguirá apoyando estos proyectos open source.
La jugada encaja con la tesis de Codex de ir más allá de “generar código” y operar en el workflow completo (planificar, modificar, ejecutar herramientas y validar). El post cita que Codex ya supera los 2M usuarios activos semanales y que su uso creció 5x desde principios de año; la adquisición está sujeta a condiciones habituales (incluida aprobación regulatoria) y, después, explorarán integraciones más profundas entre Codex y el tooling de Astral.
Fuente: [clic aquí]
OpenAI: GPT‑5.4 mini y nano (velocidad, subagentes y coste)
OpenAI lanzó GPT‑5.4 mini y nano como modelos pequeños optimizados para baja latencia y coste, especialmente en programación, tool use y sistemas con subagentes. Según OpenAI, GPT‑5.4 mini mejora de forma marcada a GPT‑5 mini y corre a más del doble de velocidad, acercándose a GPT‑5.4 en varias evaluaciones.
GPT‑5.4 mini ya está disponible en API, Codex y ChatGPT: en API ofrece ventana de 400.000 tokens y cuesta 0,75 USD/M de entrada y 4,50 USD/M de salida; en Codex consume el 30% de la cuota de GPT‑5.4 para abaratar tareas de apoyo. GPT‑5.4 nano está disponible solo en API como opción ultrabarata (0,20 USD/M entrada, 1,25 USD/M salida) para clasificación, extracción y ranking.
Fuente: [clic aquí]
Anthropic
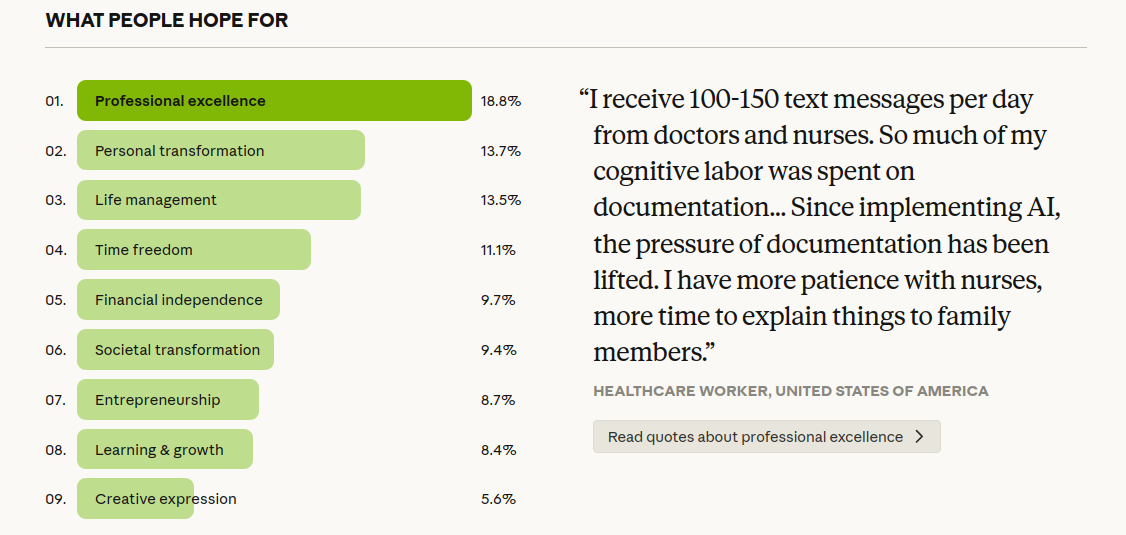
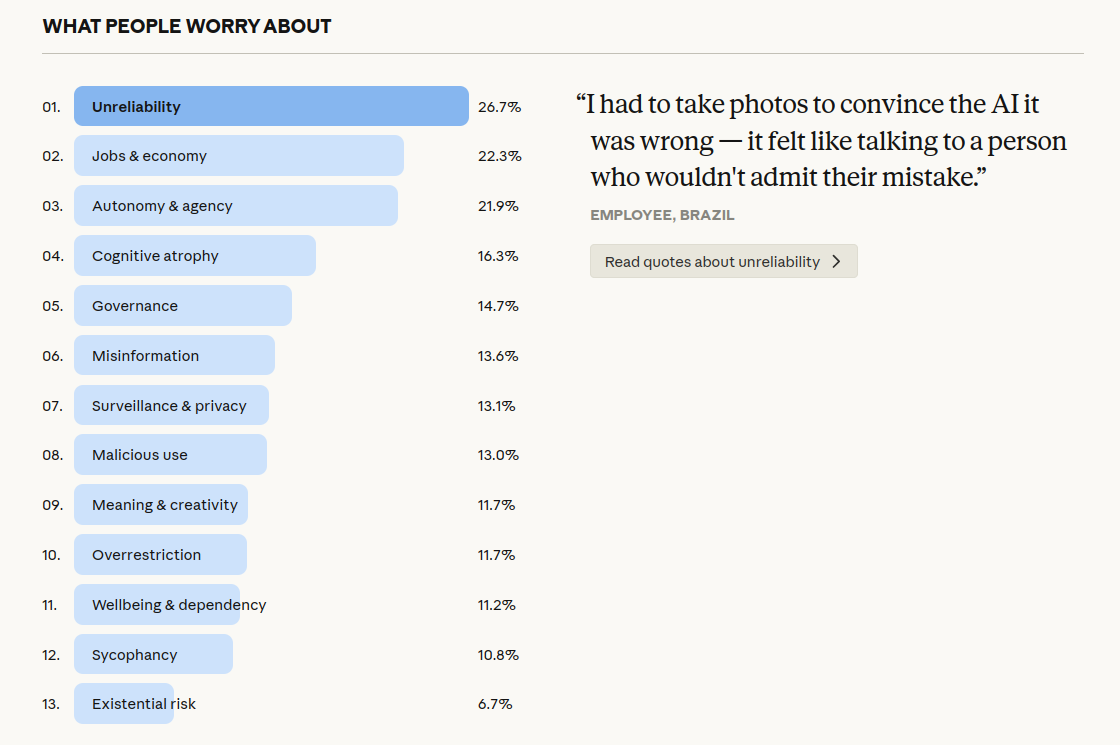
Anthropic: “What 81,000 people want from AI” (el mayor estudio cualitativo multilingüe hasta la fecha)
Anthropic publicó resultados de 80.508 entrevistas realizadas en 159 países y 70 idiomas con su “Anthropic Interviewer”, y las analizó con clasificadores basados en Claude; las respuestas se desidentificaron antes del análisis y las citas pasaron revisión manual para evitar datos personales.
En visiones, lo más común es excelencia profesional (18,8%), seguido de transformación personal (13,7%), gestión de vida (13,5%) y tiempo libre (11,1%); un 81% dice haber visto ya algún avance hacia su visión. En preocupaciones dominan falta de confiabilidad (26,7%), trabajos y economía (22,3%) y autonomía y agencia (21,9%), y el post subraya la tensión entre luces y sombras: beneficios y riesgos suelen coexistir en la misma persona.
Fuente: [clic aquí]
GitHub
GitHub: Copilot coding agent gana semantic search, validación configurable, mejores logs y un arranque más rápido
GitHub reforzó Copilot coding agent para hacerlo más rápido y transparente: ahora puede usar semantic code search para localizar código por significado, arranca ~50% más rápido y los session logs muestran mejor tanto el setup como la delegación a subagentes.
Además, los admins del repositorio pueden configurar qué validation tools ejecuta el agente (tests/linters y checks como CodeQL, secret scanning o advisory DB), y GitHub introduce un esquema LTS para modelos en Copilot Business/Enterprise empezando por GPT‑5.3‑Codex.
Fuente: [semantic search] [validation tools] [LTS GPT-5.3-Codex] [50% faster] [session logs]


Google anuncia el cierre de Firebase Studio y redirige a Antigravity y Google AI Studio
Google anunció el apagado de Firebase Studio (su entorno full‑stack con IA lanzado en preview) con una transición de un año: el anuncio llega el 19 de marzo de 2026, se deshabilitará la creación de nuevos workspaces el 22 de junio de 2026, y el producto se apagará el 22 de marzo de 2027 (con borrado permanente de datos remanentes). Google remarca que los servicios core de Firebase (Firestore, Authentication, App Hosting, etc.) no se ven afectados; el cierre aplica al entorno de desarrollo.
La explicación oficial es “simplificar” la oferta y mover aprendizajes a dos rutas: Antigravity como IDE de trabajo local code‑first y más “agentic”, y Google AI Studio para prototipado web rápido, integrando Cloud Firestore y Firebase Authentication directamente para acelerar el camino de prompt → producción. También prometen herramientas de migración progresivas para pasar proyectos a esos destinos.
Fuente: [clic aquí]

Google Labs presenta Stitch como canvas AI-native para “vibe design” de interfaces
Google Labs está evolucionando Stitch hacia un lienzo de diseño AI‑native (canvas infinito) que convierte lenguaje natural e imágenes en UI de alta fidelidad, pensado para iterar rápidamente desde ideación hasta prototipos funcionales. La actualización incorpora un design agent que razona sobre el historial del proyecto y un agent manager para explorar variantes en paralelo sin perder el hilo.
En la parte más “builder”, Stitch suma un enfoque explícito a design systems con DESIGN.md (exportar/importar reglas) y extracción desde URLs, prototipado interactivo casi instantáneo y capacidades de voz para iterar con el canvas. Además, se posiciona como puente “diseño → código” mediante un MCP server, SDK y skills, además de exportaciones hacia herramientas como AI Studio y Antigravity.
Fuente: [clic aquí]


Google anuncia el Colab MCP Server para conectar cualquier agente a Google Colab
Google for Developers presentó el Colab MCP (Model Context Protocol) Server como un puente para que cualquier agente compatible con MCP pueda acceder y operar Google Colab como un sandbox de cómputo en la nube. La idea es reducir el “corta‑pega” y el cambio de contexto entre agente local y notebook, tratando Colab como un host automatizable para prototipado y análisis reproducible.
El enfoque va más allá de “ejecutar código”: el agente puede crear y estructurar celdas, escribir y ejecutar Python en tiempo real, reorganizar contenido y gestionar dependencias (p. ej., instalando librerías). El proyecto se publica como open source y se configura para correr víauvxdesde su repositorio.
Fuente: [clic aquí] [repo]
Unión Europea
La UE avanza para prohibir los “deepfakes” sexuales y la “IA que desnuda” a personas reales sin consentimiento
El Consejo de la UE acordó su posición para añadir al Reglamento de IA una prohibición específica: vetar sistemas capaces de generar o manipular contenido sexual realista (imagen/vídeo/audio) de partes íntimas o que identifique a personas en actos sexuales sin consentimiento expreso, además de sistemas que generen pornografía infantil. El texto aún debe negociarse con el Parlamento Europeo antes de su aprobación definitiva.
La noticia recoge que el acuerdo incorpora sanciones y que expertos lo justifican por el impacto en derechos fundamentales (imagen, intimidad, reputación), aunque advierten de límites técnicos: con modelos y tooling accesibles (incluido open source), la regulación funciona sobre todo como disuasión y responsabilidad legal para plataformas/servicios, más que como “bloqueo” técnico universal.
Fuente: [clic aquí] [aquí] [o aquí]
NVIDIA
Holotron‑12B: un modelo “computer‑use” de alto rendimiento construido sobre Nemotron
H Company presentó Holotron‑12B, un modelo multimodal diseñado como policy model para agentes de “computer use”: percibir pantallas, decidir y actuar con eficiencia en entornos interactivos, con contextos largos y múltiples imágenes. La base técnica parte de NVIDIA Nemotron (Nemotron‑Nano‑12B‑v2‑VL‑BF16), y el resultado se publica con NVIDIA Open Model License.
El post se centra en su eficiencia de inferencia: al heredar una arquitectura híbrida SSM + attention, reduce el coste/memoria asociado al KV cache en contextos largos. Reportan >2x throughput frente a Holo2‑8B en WebVoyager con concurrencia 100 en una H100 (vLLM + optimizaciones SSM), y una mejora de WebVoyager del 35,1% → 80,5% tras post‑training con una mezcla propietaria de datos (SFT; checkpoint final entrenado con ~14B tokens).
Fuente: [clic aquí] [Hugging Face]


NVIDIA DLSS 5: neural rendering en tiempo real para subir la fidelidad visual en juegos
NVIDIA anunció DLSS 5 (llegará “este otoño”) como un salto hacia neural rendering que “infunde” píxeles con iluminación y materiales fotorealistas en tiempo real, con el objetivo explícito de cerrar la brecha entre render en juego y VFX cinematográfico. La compañía lo presenta como su mayor avance en gráficos desde el real‑time ray tracing (2018) y mantiene que la integración es “seamless” vía NVIDIA Streamline.
El comunicado describe un pipeline que toma color + motion vectors por frame y aplica un modelo entrenado end‑to‑end para generar resultados consistentes frame‑a‑frame, con controles para artistas (intensidad, color grading, máscaras) y soporte hasta 4K. NVIDIA afirma que DLSS ya está integrado en 750+ juegos y lista múltiples publishers/estudios que adoptarán DLSS 5.
Fuente: [clic aquí]

Amazon y AWS
AWS: evaluación de agentes con Strands Evals y customización con Nova Forge SDK
AWS presentó Strands Evals, un framework para evaluar agentes con estructura de cases → experiments → evaluators, soporte de LLM-as-judge y simulación multi-turn, útil para comparar prompts, tooling y políticas en workflows largos con métricas repetibles.
En paralelo, Nova Forge SDK busca estandarizar experimentos de customización de modelos Nova (p. ej., SFT/RFT) desde preparación de datos hasta despliegue.
Fuente: [Strands Evals] [repo] [Nova Forge SDK] [kick off] [repo]
Desde la Investigación (seguridad y agentes)
OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data (2026-03-16).
Propone un search agent “frontier-level” entrenado con un dataset completamente open source: sintetizan tareas multi‑hop controlables (expandiendo el grafo web y ofuscando entidades) y “limpian” trayectorias con un mecanismo de resumen retrospectivo para forzar acciones de mayor calidad. Con solo 11.7k muestras, reportan SOTA en benchmarks como BrowseComp y WideSearch y mejoras grandes frente a otros agentes abiertos.Fuente: [clic aquí]
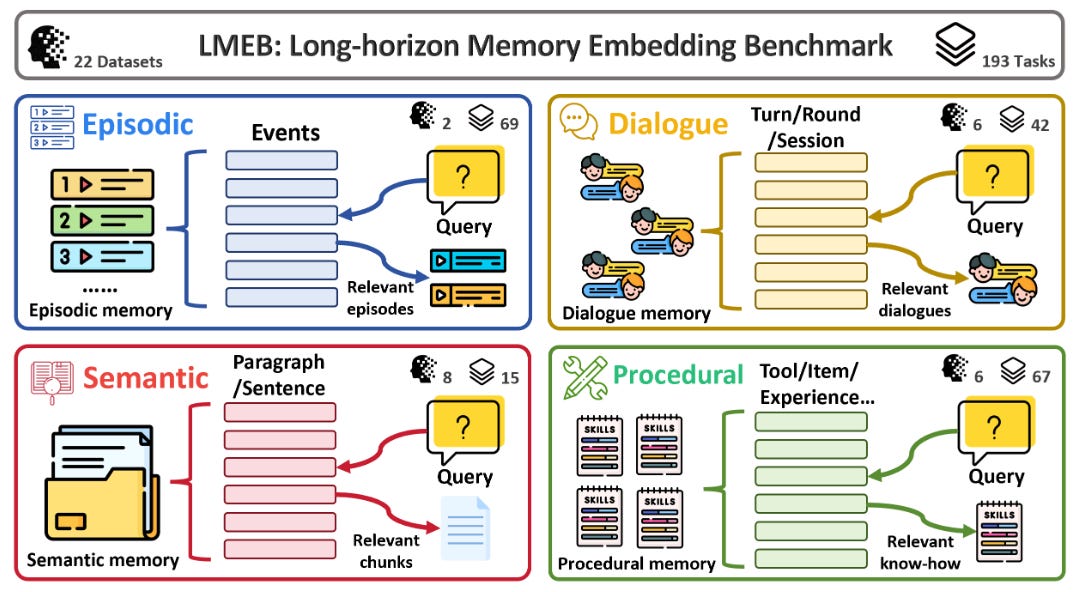
LMEB: Long‑horizon Memory Embedding Benchmark (2026-03-13).
Benchmark para evaluar embeddings en escenarios de “memoria” (episódica, diálogo, semántica y procedimental) donde la información es fragmentada y distante en el tiempo: 22 datasets y 193 tareas zero‑shot. Un hallazgo práctico: rendimiento en MTEB no necesariamente transfiere a recuperación de memoria de largo horizonte, y “más grande” no siempre gana.Fuente: [clic aquí] [repo]
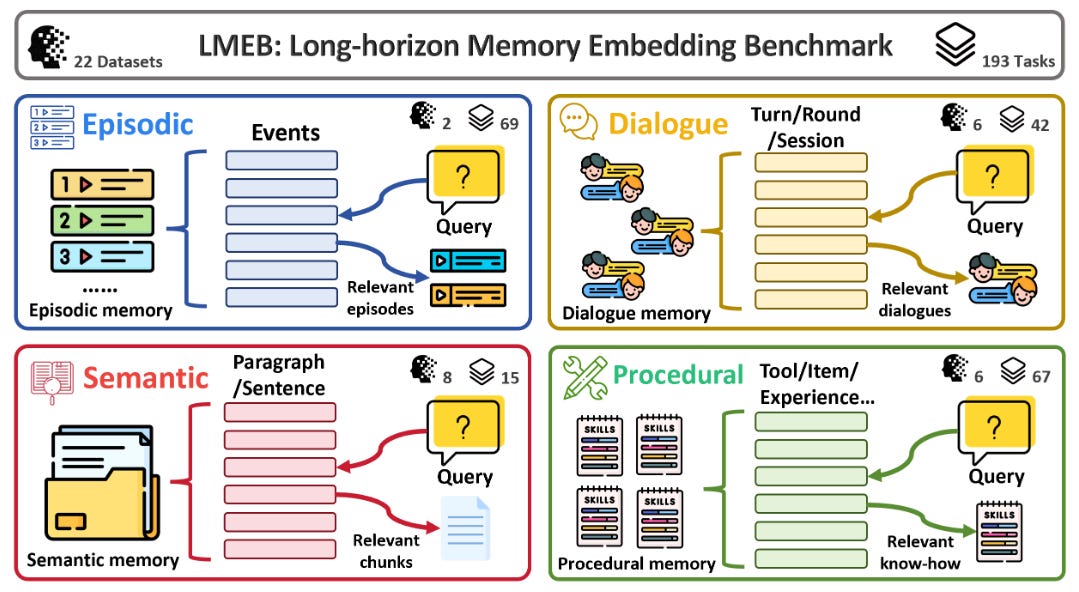
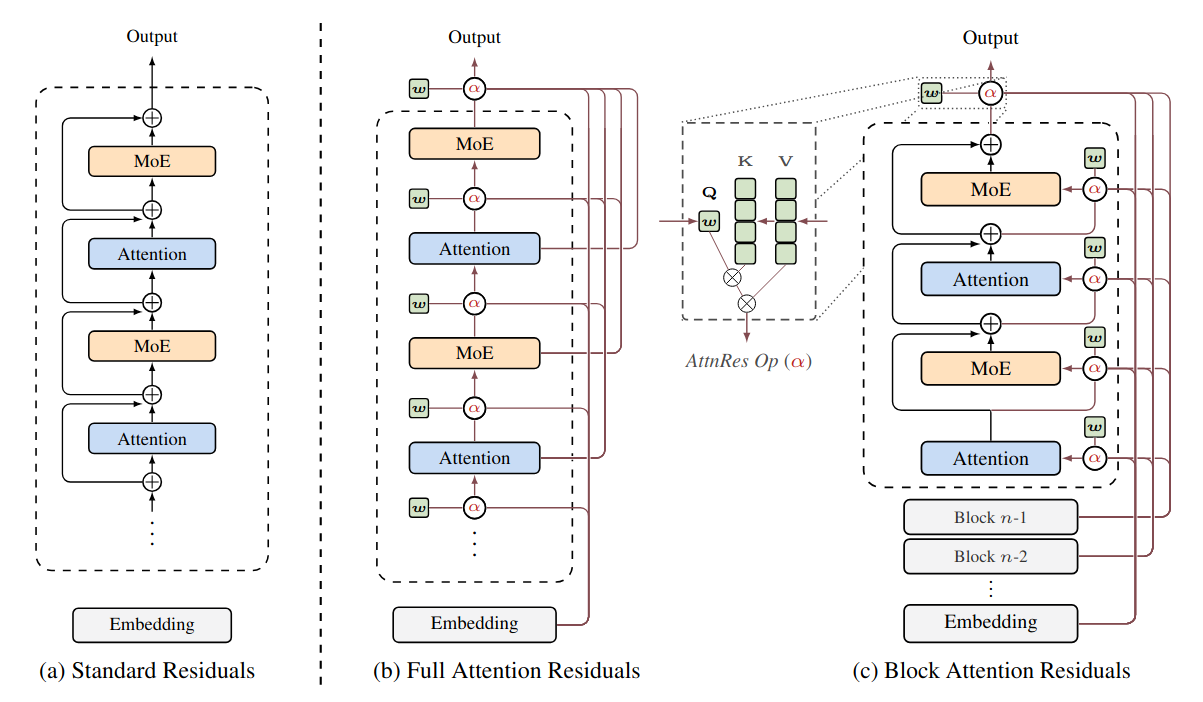
Descripción general de las categorías y especificidades de la memoria LMEB. Attention Residuals (2026-03-16).
En vez de sumar residuales con pesos fijos (que pueden “diluir” contribuciones en PreNorm a mucha profundidad), introducen una agregación con softmax attention sobre salidas previas; y una variante por bloques (Block AttnRes) para hacerlo entrenable a escala con menos overhead. Reportan mejoras consistentes en scaling laws e integración en Kimi Linear preentrenado a gran escala.Fuente: [clic aquí]
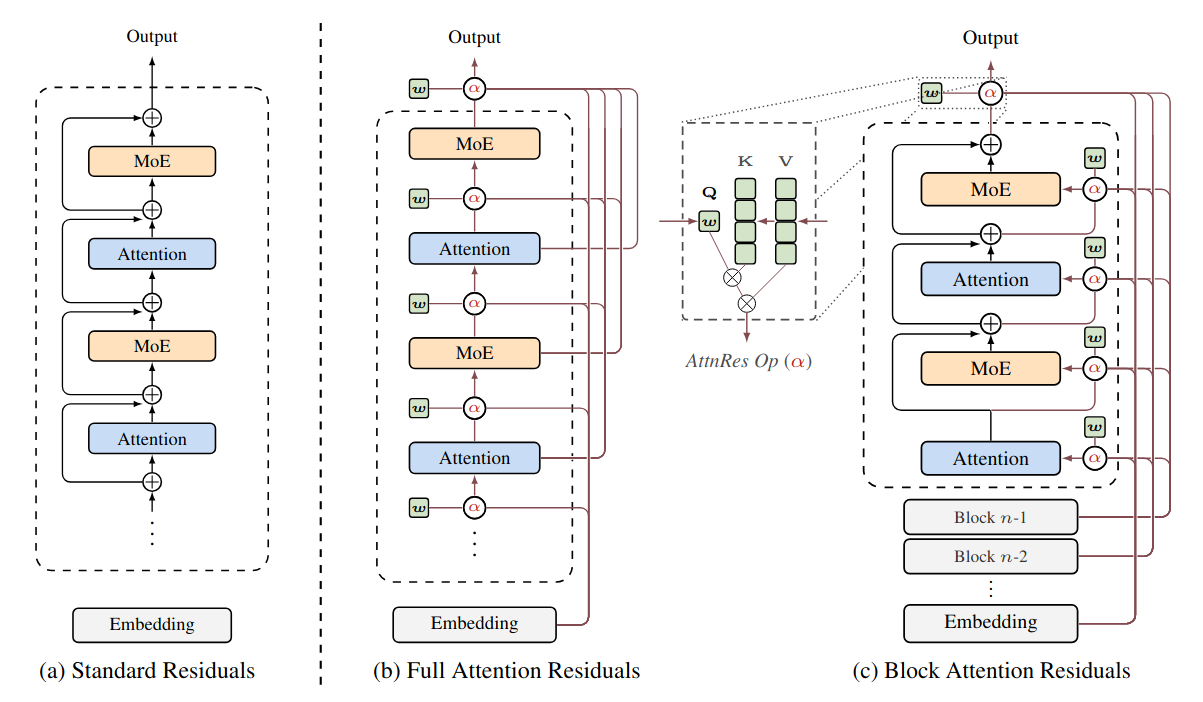
Descripción general de Attention Residuals. (a) Standard Residuals: conexiones residuales estándar con acumulación aditiva uniforme. (b) Full Attention Residuals: cada capa agrega selectivamente todas las salidas de las capas anteriores mediante pesos de atención aprendidos. (c) Block Attention Residuals: las capas se agrupan en bloques, lo que reduce la memoria de O(Ld) a O(Nd). Qianfan-OCR: A Unified End-to-End Model for Document Intelligence (2026-03-11).
Describe un VLM end‑to‑end (4B) para document intelligence que hace conversión directa a Markdown y soporta extracción de tablas, comprensión de gráficos, DocQA y KIE. Su aporte clave es “Layout‑as‑Thought”: una fase opcional con think tokens que reconstruye layout (cajas, tipos y orden de lectura) antes de generar la salida final.Fuente: [clic aquí]
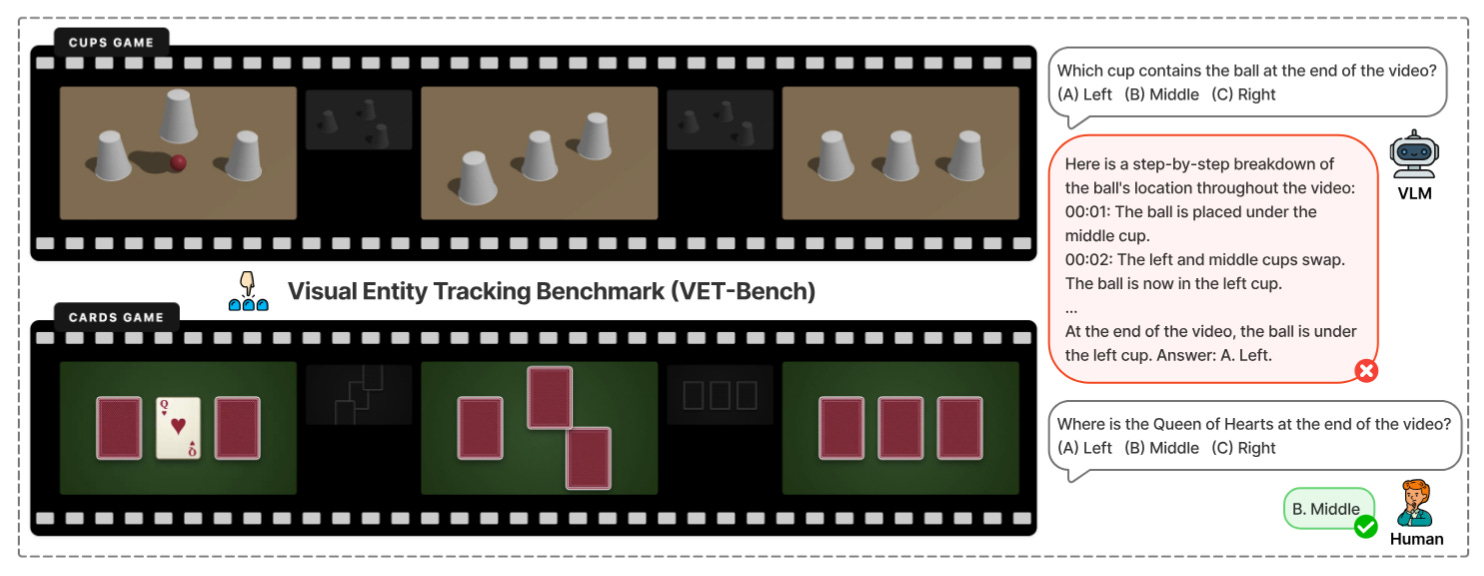
Can Vision-Language Models Solve the Shell Game? (2026-03-09).
Presentan VET‑Bench, un test sintético de entity tracking con objetos indistinguibles donde no hay atajos visuales: los VLMs punteros caen a rendimiento cercano al azar. Proponen SGCoT (razonamiento con trayectorias explícitas como estado intermedio) y reportan >90% de acierto sin herramientas externas.Fuente: [clic aquí] [repo]
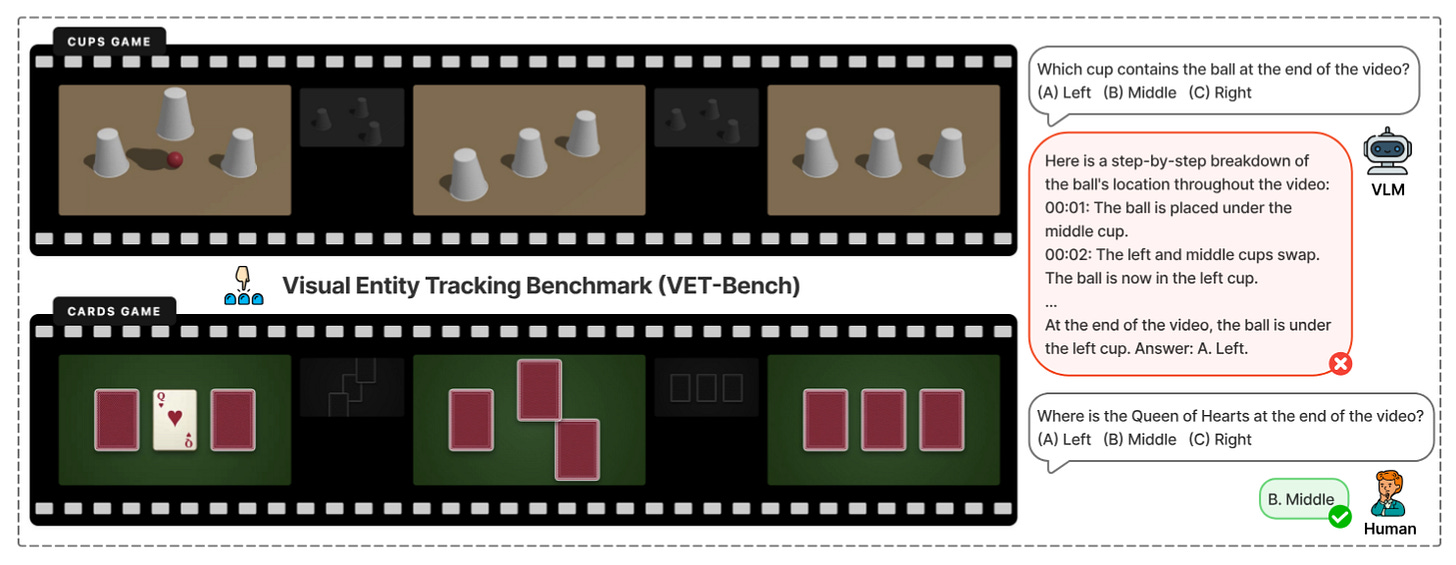
Ejemplo de Vet-Bench Demystifying Video Reasoning (2026-03-17).
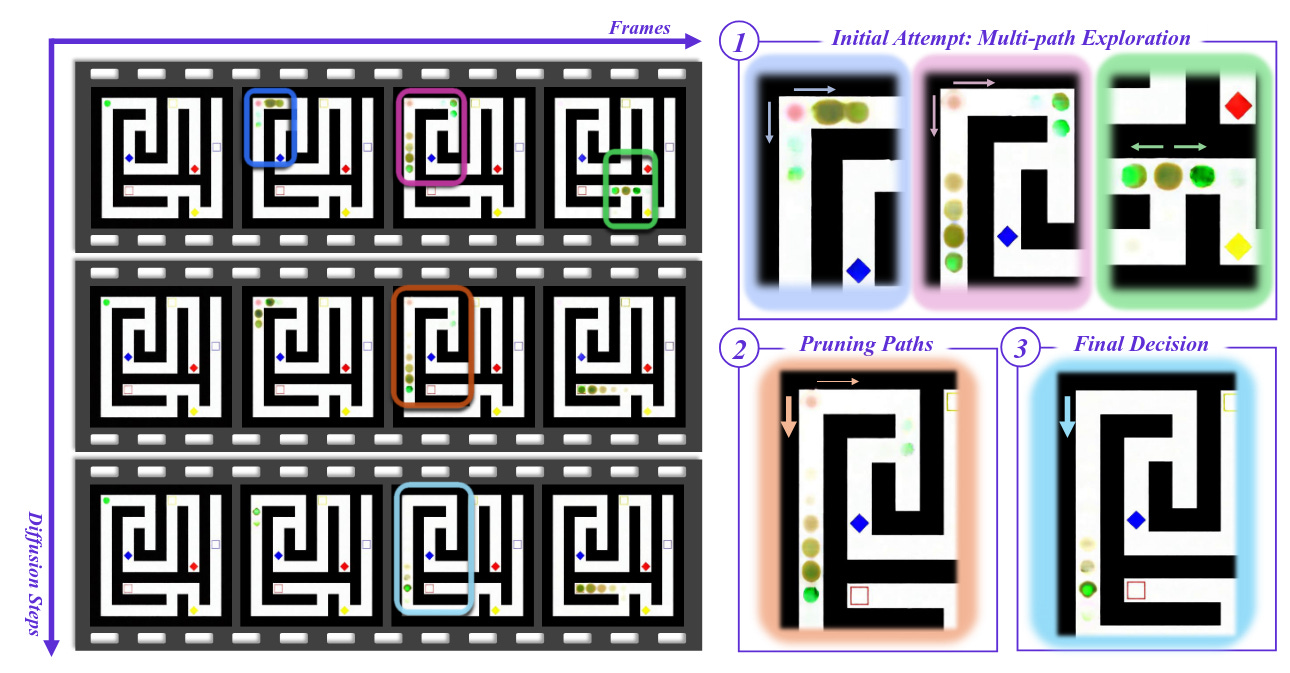
Cuestionan la idea de “Chain‑of‑Frames”: en modelos de vídeo por difusión, el razonamiento emergería principalmente a lo largo de los pasos de denoising (Chain‑of‑Steps), explorando candidatos al principio y convergiendo al final. Identifican comportamientos emergentes (memoria de trabajo, autocorrección, perception before action) y enseñan una mejora training‑free por ensembling de trayectorias latentes.Fuente: [clic aquí]
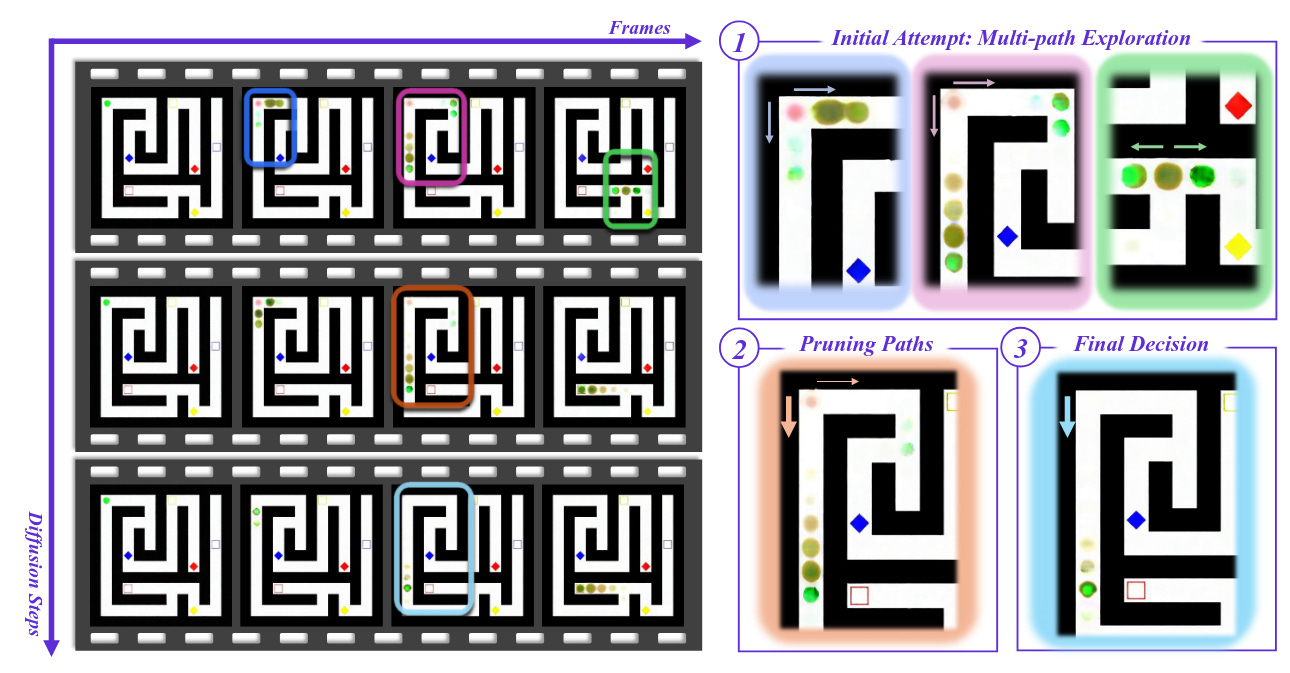
Chain of Steps. Se ha descubierto que el video-reasoning se produce a lo largo de los pasos de difusión con comportamientos emergentes sorprendentes, como realizar múltiples movimientos posibles (p. ej., caminos) simultáneamente en los primeros pasos, descartando gradualmente las opciones subóptimas durante los pasos intermedios y llegando a una decisión final en los últimos pasos. Este ejemplo de resolución de laberintos pide al modelo que comience desde el círculo verde en la esquina superior izquierda y encuentre el rectángulo rojo. Las regiones clave de interés están codificadas por colores y ampliadas a la derecha. Grounding World Simulation Models in a Real-World Metropolis (2026-03-16).
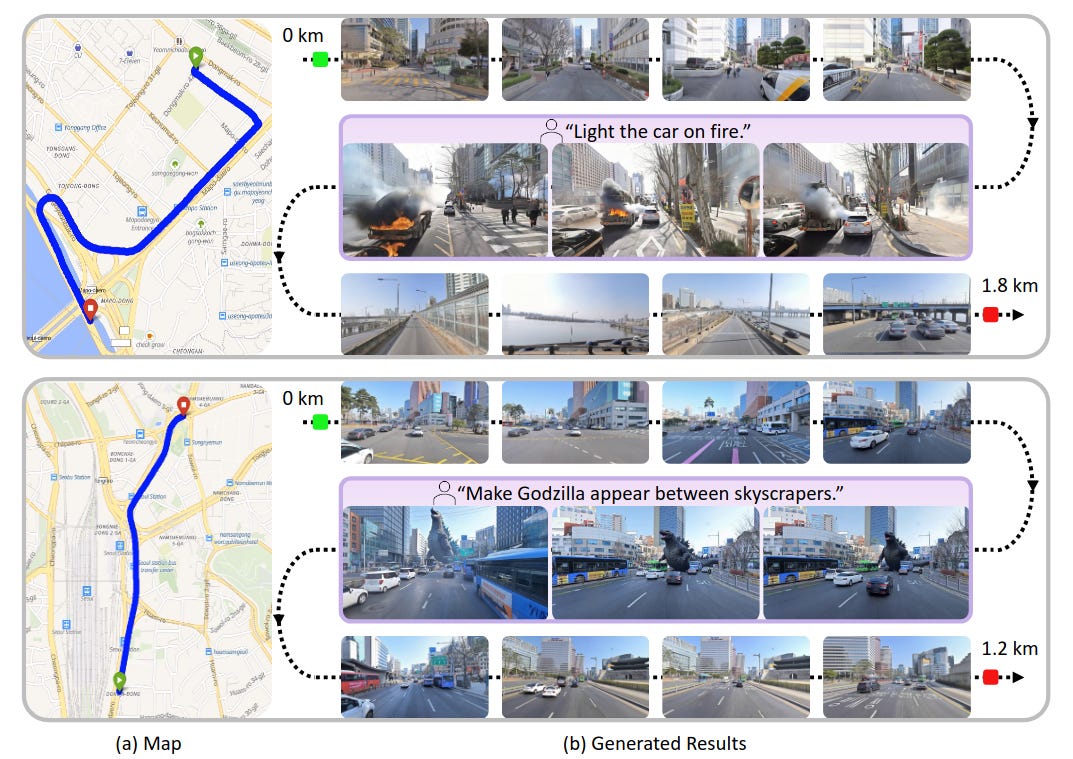
World model a escala ciudad anclado en Seúl, condicionando generación de vídeo autoregresiva con retrieval de street‑view cercano. Para lidiar con desalineación temporal y sparsity, introducen emparejado cross‑temporal, dataset sintético para trayectorias y un Virtual Lookahead Sink que “re‑ancla” la generación a futuro para estabilizar largo horizonte (cientos de metros).Fuente: [clic aquí]
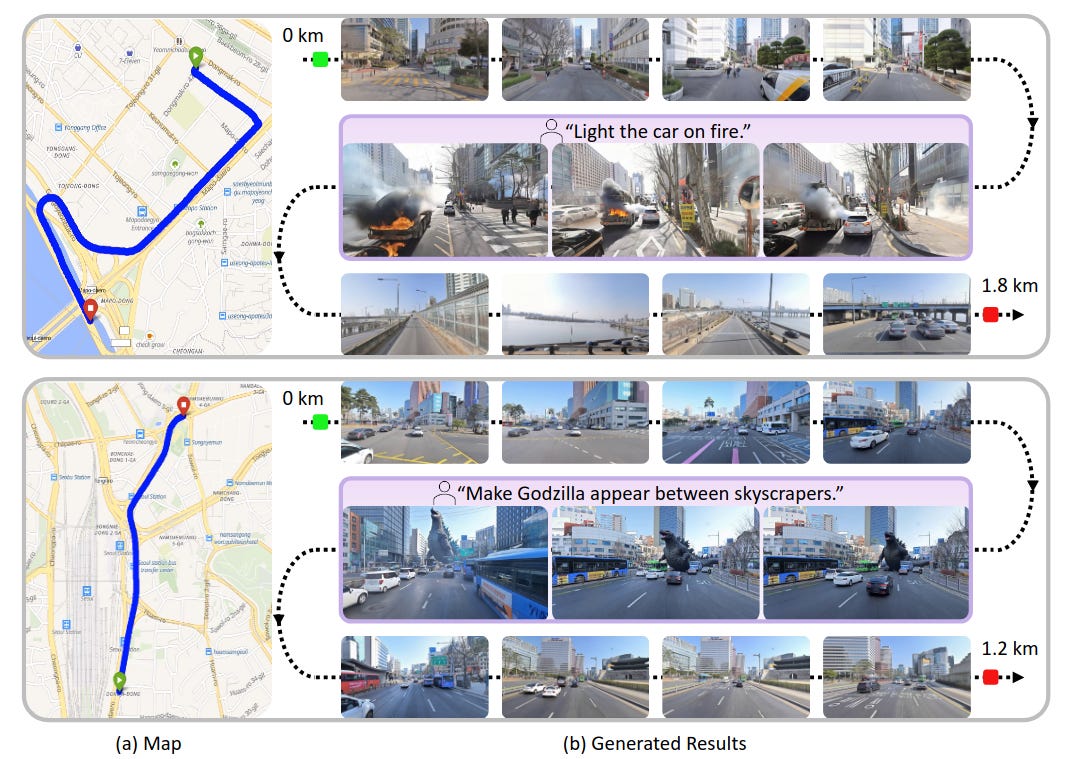
Seoul World Model (SWM) genera vídeos de más de un kilómetro ambientados en una ciudad real. La trayectoria de una cámara sobre un mapa produce un vídeo dinámico continuo que muestra el entorno real a lo largo del recorrido. Los usuarios pueden modificar la escena mediante indicaciones de texto, creando escenarios imaginativos.
Modelos de IA Interesantes
OmniCoder‑9B (Tesslate).
Modelo de agente de código (9B) afinado sobre Qwen3.5‑9B con 425k trayectorias agentic (tool use + workflows de ingeniería), pensado para tareas tipo “Claude Code/Codex”: leer‑antes‑de‑escribir, responder a diagnósticos y aplicar diffs mínimos. El model card destaca ventana nativa de 262k tokens y licencia Apache‑2.0.Fuente: [clic aquí]
Qianfan‑OCR (Baidu).
Modelo end‑to‑end de inteligencia documental (vision‑language) para OCR+layout+comprensión en una sola arquitectura, con salida directa tipo imagen → Markdown y soporte multilingüe (hasta 192 idiomas, según el model card). Incluye un modo opcional de “Layout‑as‑Thought” activable con tokens de think para páginas con layouts complejos.Fuente: [clic aquí]
GLM‑OCR (Z.ai).
OCR multimodal orientado a documentos complejos (encoder‑decoder tipo GLM‑V) con un pipeline que integra análisis de layout (PP‑DocLayout‑V3) y reconocimiento en paralelo; el proyecto publica SDK e instrucciones para servirlo con vLLM/SGLang/Ollama. Licencia MIT (con nota de licencias adicionales por la dependencia de layout).Fuente: [clic aquí]
Foundation‑1 (RoyalCities).
Modelo de text‑to‑sample para producción musical: genera loops con estructura (BPM, compases y tonalidad) y control “por capas” (instrumento, timbre, FX, notación/estructura), más cercano a un workflow de sound design que a un generador genérico de canciones. Ojo a la licencia: Stability AI Community License (no es “open weights sin restricciones”).Fuente: [clic aquí]


Utilidades para builders
Strands Evals.
Framework para evaluar agentes con estructura de experimentos, jueces LLM y soporte de trazas/simulación.Fuente: [clic aquí]
Nova Forge SDK.
SDK para orquestar experimentos de customización de modelos Nova (SFT/RFT) y llevarlos a despliegue.Fuente: [clic aquí]
LangSmith Fleet (LangChain).
“Agent Builder” evoluciona a un workspace para crear, compartir y gobernar agentes en equipos: permisos por agente, identidad+credenciales (actuar como usuario vs cuenta compartida), inbox para aprobaciones y trazas/auditoría integradas.Fuente: [clic aquí]
Open SWE (LangChain).
Framework open source (MIT) para agentes internos de código, construido sobre Deep Agents + LangGraph: sandboxes aislados, toolset curado, subagentes/middleware y triggers en Slack/Linear/GitHub para acabar abriendo PRs con validación.Fuente: [clic aquí] [repo]
Algunas Noticias Breves de IA
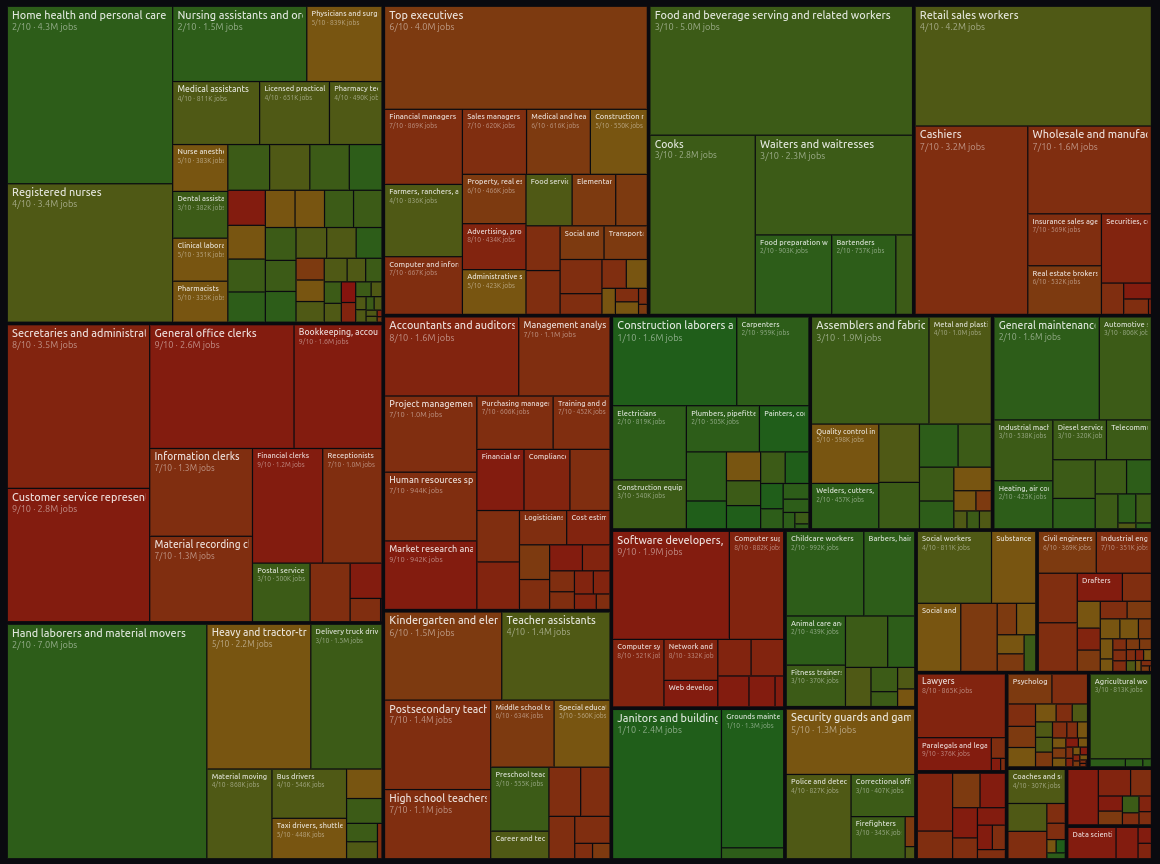
Karpathy publica un visualizador del mercado laboral (342 ocupaciones) con “Digital AI Exposure”.
Tool interactivo basado en el Occupational Outlook Handbook del BLS que permite explorar proyección de crecimiento, salario y educación, y añade una puntuación aproximada (LLM‑based) de exposición a IA para trabajos digitales (alta exposición = transformación del trabajo, no necesariamente desaparición).Fuente: [clic aquí] [repo]
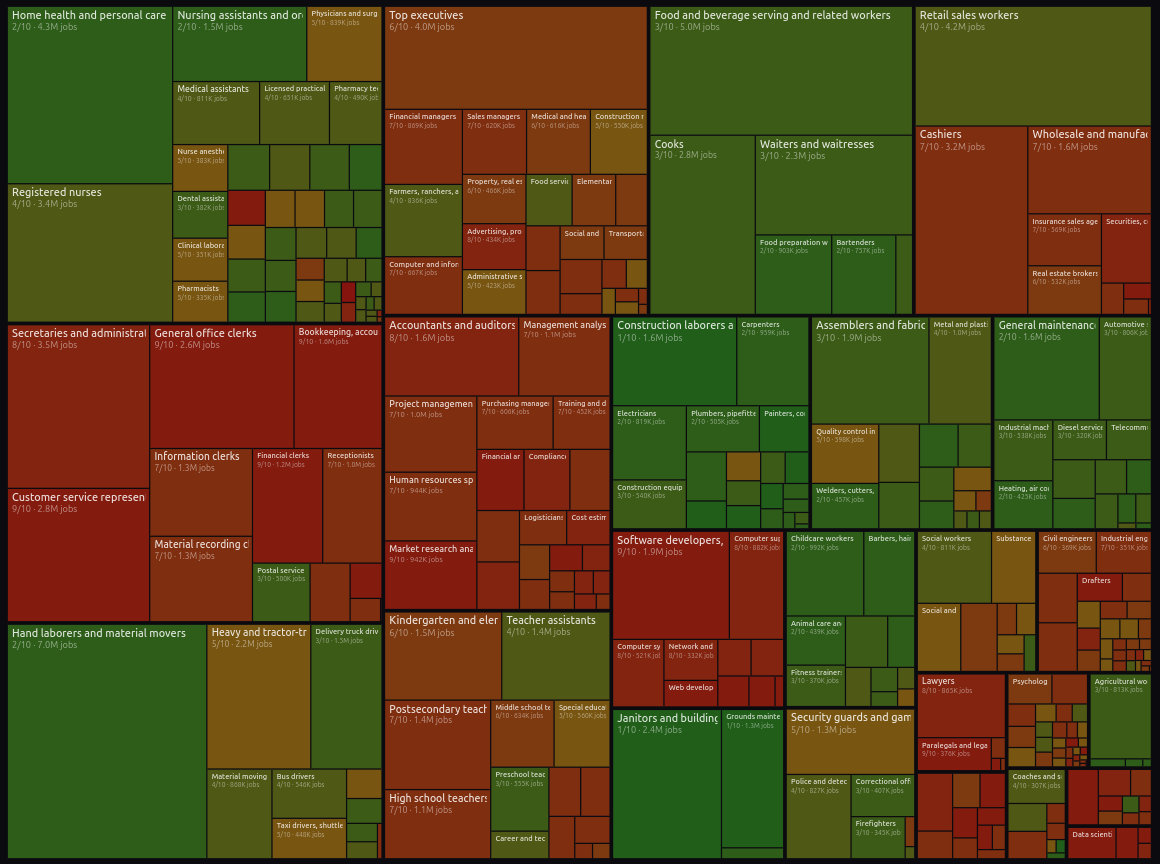
Detalle de los trabajos que peligran por el avance de la IA ArmIA3D: un caso de transferencia universidad‑empresa para prevenir fabricación ilegal de armas por impresión 3D.
Proyecto desarrollado por Glosso (spin‑off de la Universidad de Jaén) y Sicnova, con colaboración de la Guardia Civil, que aplica IA sobre geometrías para detectar y frenar la fabricación ilegal antes de que la pieza exista.Fuente: [clic aquí]

Oficinas de Glosso en la Universidad de Jaén Perplexity anuncia su Consejo Asesor de Salud (Health Advisory Board).
Perplexity crea un consejo con médicos e investigadores para guiar Perplexity Health hacia prácticas de medicina basada en evidencia: calidad de contenido, salvaguardas, seguridad del paciente y encaje en flujos de trabajo clínicos. Arranca con Eric Topol, Devin Mann, Wendy Chung y Tim Dybvig.Fuente: [clic aquí]
Cierra FormulaTV (y otras cabeceras) tras el desplome de tráfico por las respuestas con IA en Google.
ADSLZone reporta el cierre del grupo detrás de FormulaTV, eCartelera y Bekia tras más de 20 años, señalando el impacto de Google AI Overviews: menos clics hacia medios incluso estando arriba en el ranking, caídas de tráfico orgánico muy fuertes y un modelo publicitario más difícil de sostener.Fuente: [clic aquí]