En Resumen: lo imprescindible
La eficiencia y el despliegue en hardware ajustado se convierten en prioridad: desde TurboQuant para compresión extrema de modelos hasta Gemini 3.1 Flash Live/Flash-Lite y el MoE Nemotron-Cascade-2-30B-A3B, pasando por librerías Granite y modelos como Chandra OCR 2, la semana refuerza la idea de que muchos agentes vivirán en dispositivos y entornos con recursos limitados.
La voz y el audio se consolidan como interfaz nativa de agentes: Gemini 3.1 Flash Live, Covo-Audio-Chat y el framework EVA apuntan a agentes de voz full-duplex mejor evaluados, mientras trabajos como Back to Basics revisan el ASR clásico bajo el prisma de conversaciones ruidosas y en tiempo real.
Los agentes se acercan al corazón de sistemas y datos críticos: AWS publica guías y patrones explícitos para agentes en servicios financieros, IBM y AWS llevan Db2 Genius Hub al núcleo de las bases de datos empresariales y propuestas como TRUST-SQL abordan el Text-to-SQL sobre esquemas desconocidos, todo ello en tensión con debates sobre políticas de datos como las de Copilot.
Surge una capa cada vez más densa de tooling y modelos especializados para builders: Cursor Composer 2, Granite Libraries y Mellea 0.4.0, Context-1, Chandra OCR 2, MinerU-Diffusion y servicios como Guinndex o el State of Open Source de Hugging Face apuntan a un ecosistema donde elegir, combinar y operar modelos se vuelve casi tan importante como entrenarlos.
Los agentes se expanden a mundos físicos, 3D y multimodales ricos: colaboraciones como Agile Robots + DeepMind, modelos de movimiento como Kimodo, mundos generativos tipo WorldCam y WildWorld, avatares como daVinci-MagiHuman y trabajos neurocientíficos como TRIBE v2 muestran que la narrativa agentica ya no se limita al navegador o la terminal.
La teoría, los benchmarks y la gobernanza intentan ponerse al día: papers sobre semántica formal de protocolos de tools, Agent Factories para HLS, Intern-S1-Pro u Online Experiential Learning se combinan con iniciativas de seguridad como el monitoreo de desalineación en coding agents, el Safety Bug Bounty de OpenAI y The Anthropic Institute para dotar de más rigor a cómo medimos y gobernamos agentes avanzados.
Noticias Recientes
Google Research: TurboQuant y la compresión extrema para modelos de IA
Desde el frente de investigación aplicada, Google Research ha presentado TurboQuant, una técnica de compresión extrema de modelos que combina pruning, cuantización agresiva y distillation para reducir drásticamente el tamaño y coste de inferencia sin perder demasiada calidad. El trabajo explora cómo acercar modelos potentes a hardware mucho más modesto, un requisito clave si queremos agentes realmente ubicuos.
La propuesta es relevante porque no se queda en la teoría: el equipo muestra cómo TurboQuant permite ejecutar modelos que antes necesitaban GPUs de alta gama en dispositivos más limitados, manteniendo un rendimiento práctico sólido en tareas de lenguaje y visión. Es otra pieza que empuja hacia un futuro donde la eficiencia es tan estratégica como la capacidad bruta.
Fuente: [clic aquí]

Google DeepMind: Gemini 3.1 Flash Live y el papel del audio en agentes
Google DeepMind ha detallado Gemini 3.1 Flash Live, una evolución centrada en interacción de audio en tiempo casi real. El foco está en reducir latencia, mejorar la naturalidad de la voz y hacer que los modelos sean más fiables en contextos ruidosos o con turnos de conversación complejos, justo el tipo de entorno donde viven muchos agentes de atención, soporte y asistencia embebida.
La pieza encaja con la visión más amplia de Google para Gemini 3.1: distintas variantes, desde las más pesadas hasta Flash-Lite, cubriendo un espectro que va de grandes cargas en la nube a experiencias reactivas y baratas en frontends y edge. Si el chat puro fue la primera ola, la voz como interfaz primaria parece cada vez más la segunda.
Fuente: [clic aquí]


Agile Robots y Google DeepMind: inteligencia para robots industriales
En robótica, Agile Robots y Google DeepMind han anunciado una colaboración para llevar capacidades de inteligencia avanzada a robots industriales y colaborativos. El acuerdo combina hardware de Agile Robots con modelos y algoritmos de DeepMind orientados a manipulación, percepción y planificación en entornos no estructurados.
La alianza es otro indicio de que la narrativa de agentes empieza a aterrizar en sistemas físicos que manipulan el mundo real, más allá del navegador o la terminal. Si funcionan los pilotos, podríamos ver una nueva generación de robots industriales que aprenden y se adaptan mucho más rápido que con pipelines clásicos basados en programación manual.
Fuente: [clic aquí]

OpenAI
OpenAI cierra Sora, su app de vídeo para consumidores
En el plano de producto, OpenAI ha anunciado el cierre de Sora, su aplicación para crear y compartir vídeos generados con IA. La compañía mantendrá la tecnología subyacente como pieza de su stack, pero retira la app de consumo tal y como existía hasta ahora, apuntando a un rediseño más alineado con casos de uso profesionales y enterprise.
La decisión es significativa porque muestra los límites de ciertos formatos puramente B2C para modelos de vídeo frontier: mantener una app masiva, abierta y moderada en tiempo real tiene un coste operativo y reputacional alto. El mensaje implícito es que la tecnología de vídeo sigue viva, pero el envoltorio de producto tiene que madurar.
Fuentes: [RTVE] [The Hollywood Reporter]

OpenAI: hacia especificaciones más explícitas de comportamiento de modelos
OpenAI ha publicado “Inside our approach to the Model Spec”, un documento donde explica cómo está formalizando la especificación de comportamiento deseado de sus modelos: desde el tono y la gestión de riesgos hasta la interacción con herramientas y el manejo de instrucciones conflictivas. Más que un whitepaper de marketing, el texto apunta a algo importante para el ecosistema agentico: si los modelos van a operar sistemas críticos, necesitan contratos de comportamiento mucho más claros y auditables.
El enfoque de Model Spec combina guías naturales con ejemplos negativos y positivos, y propone iterar estos contratos igual que se itera el código. Es una pista clara de hacia dónde puede ir la relación entre builders y modelos frontier: menos “caja negra” y más especificación de capacidades, límites y políticas.
Fuente: [clic aquí]
NVIDIA
NVIDIA Kimodo: difusión de movimiento humano controlable para robótica y animación
NVIDIA ha presentado Kimodo, un modelo de difusión de movimiento humano en 3D entrenado sobre unas 700 horas de captura de movimiento de alta calidad. El sistema puede generar secuencias de movimiento controladas tanto por texto como por restricciones cinemáticas: keyframes completos, posiciones y rotaciones de articulaciones, waypoints 2D e incluso trayectorias densas.
Además de aplicaciones obvias en animación y contenido, Kimodo se conecta con el stack de robótica humanoide de NVIDIA: sus salidas pueden exportarse a frameworks como ProtoMotions o usarse para sintetizar datos de demostración que alimenten políticas de control. Es un ejemplo claro de cómo los modelos generativos multimodales empiezan a proporcionar data engines para agentes físicos.
Fuentes: [clic aquí] [aquí]

AWS
AWS: arquitectura de referencia para agentes en servicios financieros
AWS ha publicado “Preparing for agentic AI: A financial services approach”, una guía explícita para bancos, aseguradoras y otros actores regulados que quieren desplegar agentes sin romper sus marcos de cumplimiento. El documento propone siete principios de diseño, con énfasis en segmentación de datos, control de herramientas, logging detallado y mecanismos de supervisión humana.
Lo interesante no es solo la lista de buenas prácticas, sino el mensaje de fondo: el sector financiero empieza a tratar a los agentes como infraestructura operativa sujeta a la misma disciplina que cualquier otro sistema crítico, no como un experimento aislado de innovación.
Fuente: [clic aquí]
AWS: patrones para desarrollar y versionar agentes en la práctica
En paralelo, AWS ha publicado “Architecting for agentic AI development on AWS”, un texto más técnico donde baja al nivel de patrones arquitectónicos y de codebase para iterar sobre agentes de forma segura. Habla de entornos de prueba controlados, separación entre políticas y lógica, y uso de servicios gestionados para orquestar tool calls, colas y memoria.
Es una señal clara de madurez: el discurso ya no se centra en lo que los agentes “podrían hacer”, sino en cómo estructurar equipos, repositorios y pipelines para que agentes en producción puedan evolucionar sin convertirse en una caja negra incontrolable.
Fuente: [clic aquí]
IBM y AWS: Db2 Genius Hub lleva la capa agentica al corazón de las bases de datos
En datos empresariales, IBM y AWS han anunciado Db2 Genius Hub en AWS Marketplace, una solución que introduce capacidades agenticas para la gestión autónoma y asistida de bases de datos Db2. El sistema promete ayudar con tuning, diagnósticos y recomendaciones operativas, apoyado en modelos de IA y en conocimiento de dominio sobre la plataforma.
Lo relevante es que este tipo de producto acerca la narrativa agentica a sistemas donde tradicionalmente ha primado la aversión al riesgo: bases de datos que soportan cargas de misión crítica. La clave estará en hasta qué punto estas automatizaciones se integran con flujos de aprobación humana y con los marcos de auditoría existentes.
Fuente: [clic aquí]
GitHub
GitHub: cambios en la política de datos de Copilot
GitHub también ha anunciado actualizaciones en la política de uso de datos de Copilot: a partir del 24 de abril, la compañía utilizará por defecto algunos inputs y outputs de Copilot para seguir entrenando y afinando sus modelos, salvo que los usuarios o las organizaciones opten explícitamente por no participar.
Más allá del detalle legal, la noticia subraya la tensión estructural de la era agentica: los modelos mejoran cuanto más ven, pero los usuarios quieren garantías claras sobre privacidad, confidencialidad y control. La forma en que GitHub y otros proveedores gestionen este equilibrio marcará buena parte de la confianza en agentes embebidos en tooling de desarrollo.
Fuente: [clic aquí]
GitHub: agentes coordinados dentro del repositorio con Squad
GitHub ha publicado un deep dive sobre Squad, su aproximación a agentes coordinados que trabajan directamente dentro del repositorio apoyados en Copilot. El artículo describe cómo modelan tareas complejas como grafos de subagentes, cómo controlan el contexto que ve cada uno y qué patrones utilizan para mantener las acciones del sistema inspeccionables, reversibles y colaborativas con humanos.
La idea es potente: en vez de un único agente monolítico “que lo hace todo”, GitHub propone pequeños agentes especializados que se coordinan dentro de un marco común. Es exactamente la clase de diseño que cabe esperar si los agentes van a vivir incrustados en el ciclo de vida completo del software, desde el issue hasta el despliegue.
Fuente: [clic aquí]
Meta
Meta AI: TRIBE v2 como gemelo digital de la actividad cerebral
Meta ha presentado TRIBE v2, un modelo fundacional que actúa como una especie de gemelo digital de la actividad neural humana. Entrenado sobre datos de más de 700 voluntarios expuestos a imágenes, audio, vídeo y texto, el sistema es capaz de predecir con mucha mayor resolución cómo responde el cerebro a estímulos complejos, y generalizar en modo zero-shot a nuevos sujetos, tareas e idiomas.
Aunque su foco inmediato es neurociencia y clínica, el trabajo es interesante también desde la óptica de agentes: abre la puerta a integrar modelos que capturan directamente patrones cerebrales en interfaces cerebro-ordenador, asistencia clínica avanzada y, a más largo plazo, en arquitecturas de IA inspiradas en principios neurobiológicos.
Fuente: [clic aquí]
Desde la Investigación (arXiv, benchmarks y seguridad)
Back to Basics: Revisiting ASR in the Age of Voice Agents (2026-03-26)
Un trabajo reciente en arXiv, “Back to Basics: Revisiting ASR in the Age of Voice Agents”, propone revisar los fundamentos del reconocimiento automático de voz a la luz de las exigencias de los agentes actuales. Los autores argumentan que muchos pipelines se han construido sobre supuestos de benchmark que no capturan bien latencia, interrupciones, barullo acústico y cross-talk, factores críticos cuando hay un agente en la otra punta.
El artículo sugiere que, paradójicamente, refinar componentes “clásicos” como el ASR puede tener tanto impacto en la experiencia de un voice agent como introducir un modelo frontier más grande.Fuente: [clic aquí]
Agent Factories for High Level Synthesis: How Far Can General-Purpose Coding Agents Go in Hardware Optimization? (2026-03-26)
Otro trabajo interesante, “Agent Factories for High Level Synthesis: How Far Can General-Purpose Coding Agents Go in Hardware Optimization?”, se pregunta hasta qué punto agentes de código generalistas pueden realmente manejar tareas tan especializadas como la síntesis de alto nivel y la optimización de hardware.
El estudio explora pipelines donde agentes apoyados en LLM generan, ajustan y evalúan diseños, comparando sus resultados con flujos tradicionales. Más allá de los números, el mensaje es claro: la frontera de los coding agents empieza a moverse desde repositorios de software clásico hacia dominios de ingeniería mucho más estructurados y sensibles.Fuente: [clic aquí]
Formal Semantics for Agentic Tool Protocols: A Process Calculus Approach (2026-03-25)
El paper “Formal Semantics for Agentic Tool Protocols: A Process Calculus Approach” intenta poner orden en un tema que hasta ahora se ha tratado de forma bastante ad hoc: cómo formalizar los protocolos de comunicación entre agentes y herramientas externas.
Usando ideas de cálculo de procesos, los autores proponen una semántica que permite razonar sobre bloqueos, carreras, fallos parciales y composición de múltiples tools. Si la industria quiere agentes que trabajen con decenas de APIs y sistemas críticos a la vez, este tipo de formalización podría acabar siendo tan importante como lo fue en su día el diseño de protocolos de red robustos.Fuente: [clic aquí]
WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation (2026-03-17)
WorldCam se sitúa en la intersección entre modelos de vídeo generativo y mundos interactivos: plantea gaming worlds autoregresivos donde el eje central es la pose de cámara en 6 DoF como representación geométrica unificadora. El modelo traduce acciones continuas del usuario en movimientos de cámara físicamente coherentes y usa esas poses globales como índice para recuperar observaciones pasadas y mantener consistencia 3D a largo plazo.
Además de introducir un modelo, el trabajo aporta un dataset de unas 3.000 minutos de gameplay real con trayectorias de cámara anotadas y descripciones textuales, mostrando mejoras claras en control de acción, calidad visual y coherencia espacial frente a otros world models. Es especialmente relevante para pensar en agentes que se mueven en mundos 3D generados, no solo en vídeo pasivo.Fuente: [clic aquí]

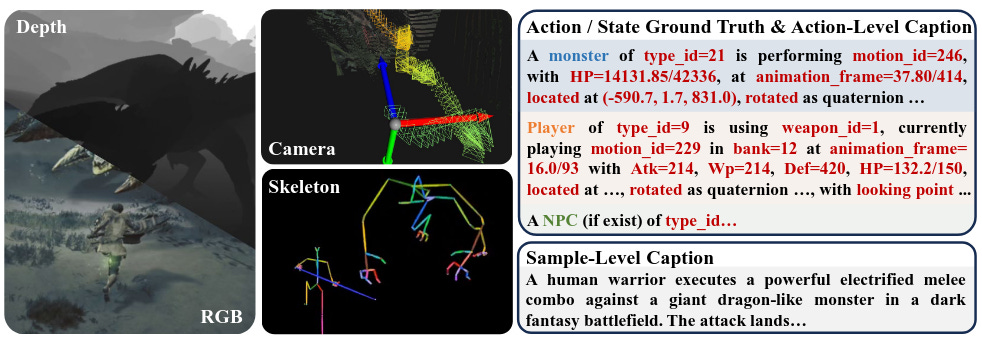
WorldCam es un modelo de juego 3D interactivo que permite un control preciso de las acciones incluso con entradas de teclado y ratón difíciles (arriba), admite interacciones de largo alcance (centro) y mantiene una geometría 3D consistente en todos los puntos de vista (abajo). El tiempo (segundos a 20 FPS) se visualiza en la esquina superior izquierda de cada fotograma, mientras que las entradas de teclado y ratón se muestran en las esquinas inferior izquierda e inferior derecha, respectivamente. El recuadro rojo resalta la geometría 3D consistente en las vistas revisadas. WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG (2026-03-24)
En paralelo, WildWorld propone un dataset a gran escala para world models accionados con estado explícito, construido a partir de partidas fotorealistas del ARPG Monster Hunter: Wilds. Incluye más de 108 millones de frames y más de 450 acciones (movimiento, ataques, skills), junto con anotaciones sincronizadas de esqueletos, estado del mundo, poses de cámara y mapas de profundidad.
El equipo introduce además WildBench para evaluar modelos en Action Following y State Alignment, y muestra que incluso los métodos avanzados actuales siguen luchando para mantener consistencia de estado a largo plazo cuando las acciones son semánticamente ricas. Es un recurso valioso para entrenar y medir agentes que aprenden modelos del mundo en entornos complejos estilo ARPG.Fuente: [clic aquí]
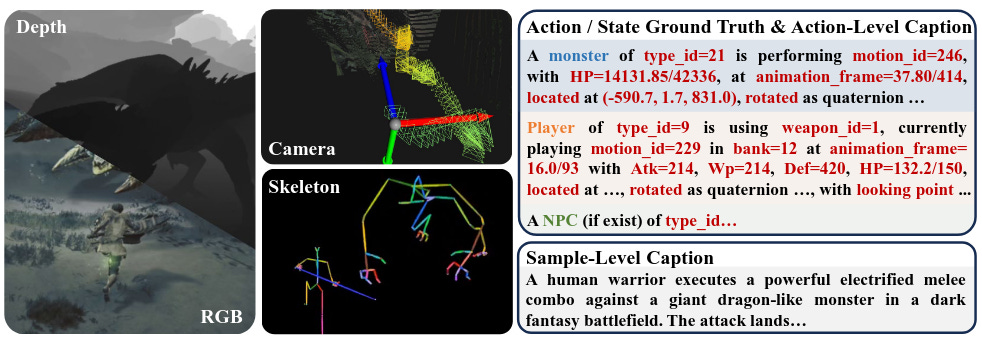
WildWorld es un conjunto de datos a gran escala recopilado de motores de juegos para el modelado dinámico de mundos. Contiene fotogramas RGB con mapas de profundidad, poses de cámara, esqueleto y datos reales de acción/estado. Ofrece descripciones detalladas tanto a nivel de acción como a nivel de muestra, lo que hace que el conjunto de datos sea aplicable a diversos entornos experimentales. Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale (2026-03-26)
Intern-S1-Pro es presentado como el primer modelo fundacional científico multimodal de un billón de parámetros, diseñado para combinar capacidades generales de lenguaje/visión con una profundidad técnica fuerte en dominios como química, materiales, ciencias de la vida y geociencias. Además de mejorar en razonamiento y comprensión imagen-texto, el modelo amplía su repertorio a más de 100 tareas científicas especializadas.
El trabajo destaca también por la infraestructura necesaria para entrenar a esta escala, apoyándose en XTuner y LMDeploy para RL eficiente y consistencia de precisión entre entrenamiento e inferencia. Para el ecosistema agentico, es un paso importante hacia agentes científicos generalistas pero fácilmente especializables en verticales profundos.Fuente: [clic aquí]
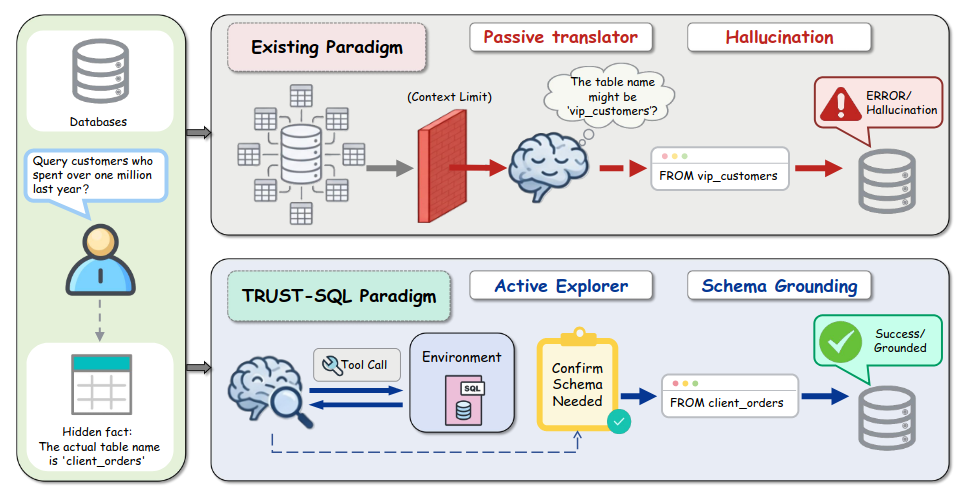
TRUST-SQL: Tool-Integrated Multi-Turn Reinforcement Learning for Text-to-SQL over Unknown Schemas (2026-03-18)
TRUST-SQL aborda un problema muy práctico para agentes en empresas: el Text-to-SQL cuando el esquema de la base de datos es desconocido o masivo. En lugar de asumir un schema completo prefijado, plantean un agente que interactúa por turnos con tools de inspección de metadatos, formulando el problema como un POMDP y siguiendo un protocolo de cuatro fases para ir restringiendo el espacio de tablas y columnas relevantes.
Sobre ese protocolo, introducen una estrategia de RL llamada Dual-Track GRPO que separa las recompensas de exploración de los resultados de ejecución usando ventajas enmascaradas a nivel de token, resolviendo mejor el problema de credit assignment. Los resultados muestran mejoras significativas frente a GRPO estándar y, crucialmente, alcanzan o superan baselines que sí reciben el esquema completo de entrada, lo que lo hace muy atractivo para agentes de datos en entornos reales.Fuente: [clic aquí]
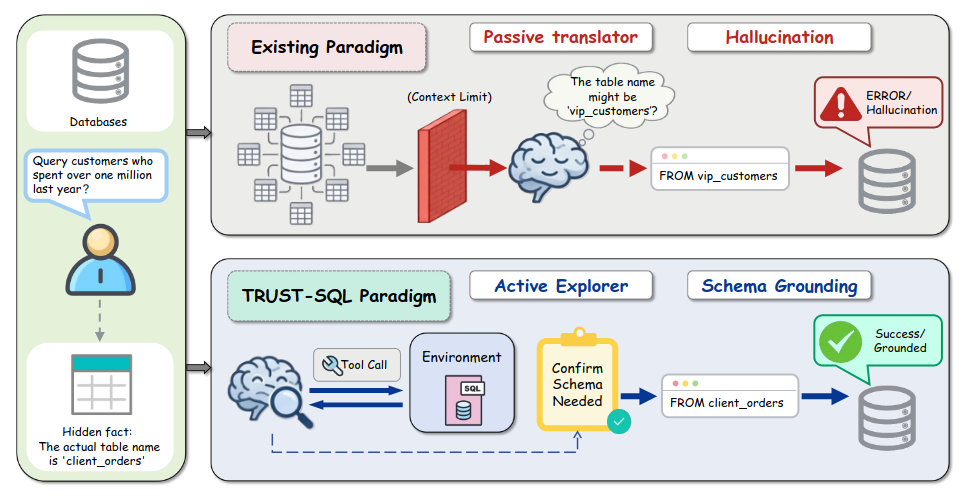
Esquema del paradigma TRUST-SQL frente a los paradigmas existentes Online Experiential Learning for Language Models (2026-03-17)
En lugar de ver el despliegue en producción como algo estático, Online Experiential Learning (OEL) propone un marco para que los modelos de lenguaje aprendan continuamente de su propia experiencia de uso real. El ciclo consta de dos etapas: primero, se extrae y acumula conocimiento “experiencial” transferible a partir de trayectorias de interacción de usuarios; después, ese conocimiento se consolida en los parámetros del modelo mediante context distillation on-policy, sin acceso directo al entorno de usuario.
Aplicado a entornos de juegos de texto y a distintos tamaños de modelo (con y sin modo “thinking”), OEL mejora de forma consistente precisión y eficiencia de tokens a lo largo de iteraciones, manteniendo el rendimiento fuera de distribución. Es una pieza clave para pensar en agentes que no solo ejecutan políticas fijas, sino que mejoran de manera segura a partir de su historial de interacción.Fuente: [clic aquí]
MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding (2026-03-23)
Mientras modelos como Chandra OCR 2 empujan el frente SOTA en OCR clásico, MinerU-Diffusion replantea el problema como renderizado inverso mediante difusión, sustituyendo el decoding autoregresivo secuencial por un denoising paralelo condicionado visualmente. El modelo utiliza un decodificador por bloques y un currículo de entrenamiento guiado por incertidumbre para estabilizar el aprendizaje y hacer eficiente la inferencia en secuencias largas.
En benchmarks de documentos complejos, MinerU-Diffusion mejora la robustez y logra hasta 3,2× velocidad de decoding frente a sistemas autoregresivos, y el benchmark Semantic Shuffle muestra menor dependencia de priors lingüísticos y mayor fidelidad visual. Es muy relevante para agentes que necesitan parsear rápidamente PDFs largos con tablas, fórmulas y layout rico.Fuente: [clic aquí]

La decodificación por difusión reconstruye progresivamente el texto estructurado a partir de tokens enmascarados bajo condicionamiento visual: los tokens negros se confirman, los tokens rojos se actualizan y los tokens amarillos permanecen enmascarados, lo que permite la generación paralela con consistencia global, a diferencia de la decodificación autorregresiva de izquierda a derecha.


Modelos de IA Interesantes
Cursor Composer 2: un agente de programación cada vez más largo-plazo
El equipo de Cursor ha lanzado Composer 2, una nueva generación de su modelo de programación que mejora de forma notable en Terminal-Bench 2.0 y SWE-bench Multilingual, combinando preentrenamiento continuo y RL sobre tareas de largo plazo para crear un coding agent especializado capaz de navegar repositorios vivos, encadenar cientos de acciones coherentes y mantener contexto consistente durante sesiones largas.Fuente: [clic aquí]

Comparación del nuevo Composer 2 frente a modelos similares con el benchmark Terminal-Bench 2.0 Covo-Audio-Chat: modelo de audio-a-audio para agentes de voz full-duplex
Tencent ha presentado Covo-Audio-Chat, un modelo de audio-a-audio de 7B parámetros que combina características acústicas continuas, tokens discretos de voz y texto en una secuencia tri-modal para habilitar interacción full-duplex de baja latencia, apuntando a una nueva generación de agentes nativos de audio que entienden, razonan y responden en voz con separación clara entre identidad de voz e inteligencia del diálogo.Fuente: [clic aquí]

Comparación del nuevo Covo-Audio frente a modelos de audio similares Chroma Context-1: un subagente de búsqueda auto-editable
Chroma ha presentado Context-1, un modelo de 20B parámetros orientado a búsqueda agentica que descompone consultas, ejecuta múltiples búsquedas iterativas y auto-gestiona su contexto con pruning selectivo, logrando rendimientos comparables a modelos mucho más grandes en benchmarks como BrowseComp-Plus o SealQA y permitiendo delegar la búsqueda a un subagente especializado más barato para mantener a raya la latencia y el coste de flujos largos.Fuente: [clic aquí]
Lyria 3: generación musical estructurada para productos y experiencias
Google ha lanzado Lyria 3, su nueva generación de modelo de música en variantes Pro y Clip, con control fino por texto, tempo y estructura, entrada multimodal por imagen y despliegue vía Gemini API, lo que lo convierte en una pieza muy útil para agentes creativos que generan bandas sonoras, jingles o loops adaptativos en tiempo real con watermarking SynthID para trazabilidad.Fuente: [clic aquí]
Chandra OCR 2: OCR multimodal para documentos largos y complejos
Desde Datalab llega Chandra OCR 2, un modelo de image/PDF-to-text de ~5B parámetros basado en Qwen 3.5 que convierte documentos en Markdown, HTML o JSON preservando layout, tablas y fórmulas, logra resultados SOTA en olmOCR y soporta más de 90 idiomas, ofreciendo a los agentes una capa muy sólida para ingerir PDFs, escaneos y formularios antes de razonar o alimentar pipelines RAG.Fuente: [clic aquí]

Ejemplo de uso de Chandra OCR 2 en la extracción de texto de imágenes daVinci-MagiHuman: generación audio-vídeo centrada en humanos en un solo transformer
El equipo de GAIR presenta daVinci-MagiHuman, un modelo generativo de 15B parámetros con arquitectura single-stream Transformer para texto, imagen de referencia, vídeo y audio que produce vídeo realista de personas con sincronía fina cara-cuerpo-voz y soporte multilingüe, ideal para avatares conversacionales y agentes de atención con cara y voz propias, apoyado en una pila completa abierta bajo licencia Apache 2.0.Fuente: [clic aquí]
Nemotron-Cascade-2-30B-A3B: razonamiento y capacidades agenticas en un MoE abierto
NVIDIA ha publicado Nemotron-Cascade-2-30B-A3B, un modelo Mixture-of-Experts de 30B parámetros con solo 3B activados por token, afinado con SFT y RL para razonamiento, que ofrece modos de “thinking” e “instruct”, contextos largos de hasta ~262k tokens y soporte explícito para tool use, con resultados destacados en razonamiento matemático y programación (IMO, IOI, Terminal-Bench 2.0, LiveCodeBench), haciéndolo muy atractivo para coding agents avanzados y agentes de resolución de problemas complejos.Fuente: [clic aquí]

Comparación del nuevo Nemotron-Cascade-2-30B-A3B frente a modelos open-source similares




Utilidades para builders
Librerías Granite y Mellea 0.4.0: toolkit para despliegues empresariales
IBM ha anunciado novedades en torno a Mellea 0.4.0 y a sus librerías Granite, que apuntan a facilitar el despliegue y operación de modelos en entornos empresariales regulados. Más que un modelo espectacular concreto, lo relevante aquí es el énfasis en tooling: conectores, librerías y APIs que permiten que los agentes se integren con sistemas existentes sin obligar a reescribir medio stack.
Este tipo de toolkit encaja muy bien con la narrativa de la semana: menos foco en el “modelo de moda” y más en las piezas que hacen viable su uso sostenido en producción.Fuente: [clic aquí]
EVA: un framework para evaluar sistemáticamente agentes de voz
En el frente de evaluación, ServiceNow ha presentado EVA (Evaluating Voice Agents), un framework pensado para medir de forma más sistemática la calidad de los agentes de voz modernos. En lugar de quedarse solo en métricas de ASR, el sistema incorpora dimensiones de naturalidad conversacional, manejo de turnos y robustez frente a errores.
EVA pone de manifiesto algo que muchos equipos ya intuían: cuando el agente vive en el teléfono o en un front de voz, la experiencia ya no depende solo de “entender palabras”, sino de cómo se comporta el sistema dentro de una conversación viva y a veces caótica.Fuente: [clic aquí]
Algunas Noticias Breves de IA
OpenAI detalla cómo monitoriza la desalineación de sus coding agents internos. En una nota sobre seguridad, la compañía explica los mecanismos que emplea para detectar comportamientos no deseados en sus propios agentes de codificación, incluyendo análisis de logs, detección de patrones anómalos y pruebas adversariales internas.
Fuente: [clic aquí]
OpenAI lanza un programa de bug bounty de seguridad centrado en IA. El nuevo Safety Bug Bounty abre la puerta a que investigadores externos reporten vulnerabilidades y problemas de seguridad en los sistemas de la compañía, con recompensas económicas escaladas según severidad.
Fuente: [clic aquí]
Anthropic refuerza su apuesta institucional por la seguridad con The Anthropic Institute. La organización presenta un nuevo instituto dedicado a investigación en alineación, seguridad y políticas de IA, enviando la señal de que el trabajo en agentes avanzados irá de la mano de una capa robusta de gobernanza.
Fuente: [clic aquí]
Hugging Face publica su “State of Open Source” de primavera de 2026. El informe destaca el crecimiento acelerado de proyectos open weights, infra para despliegues locales y tooling específico para agentes, así como una diversificación de la comunidad hacia dominios como robótica, edge y enterprise. Contiene información y métricas muy interesantes para con el futuro de la IA open-source.
Fuente: [clic aquí]



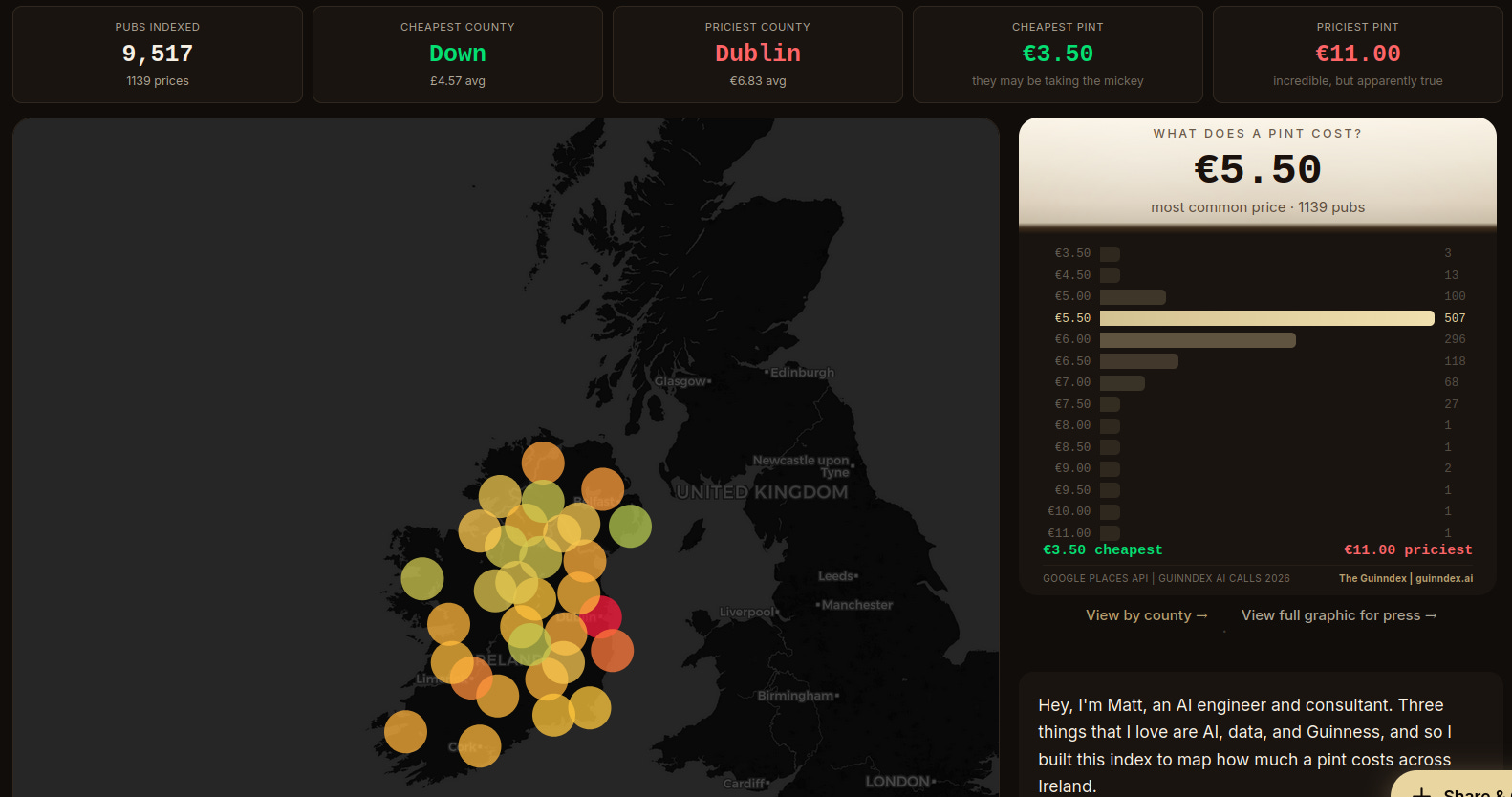
Guinndex.ai, un ejemplo divertido de IA Agéntica. La plataforma Guinndex.ai agrega información sobre el precio de las pintas de cerveza en Irlanda. Se lanzaron agentes que llamaban por teléfono a todos los pubs de Irlanda preguntando por los precios de las pintas y anotando esta información. Contiene un mapa interactivo con los precios actualizándose con frecuencia y por la propia comunidad cervecera.
Fuente: [clic aquí]
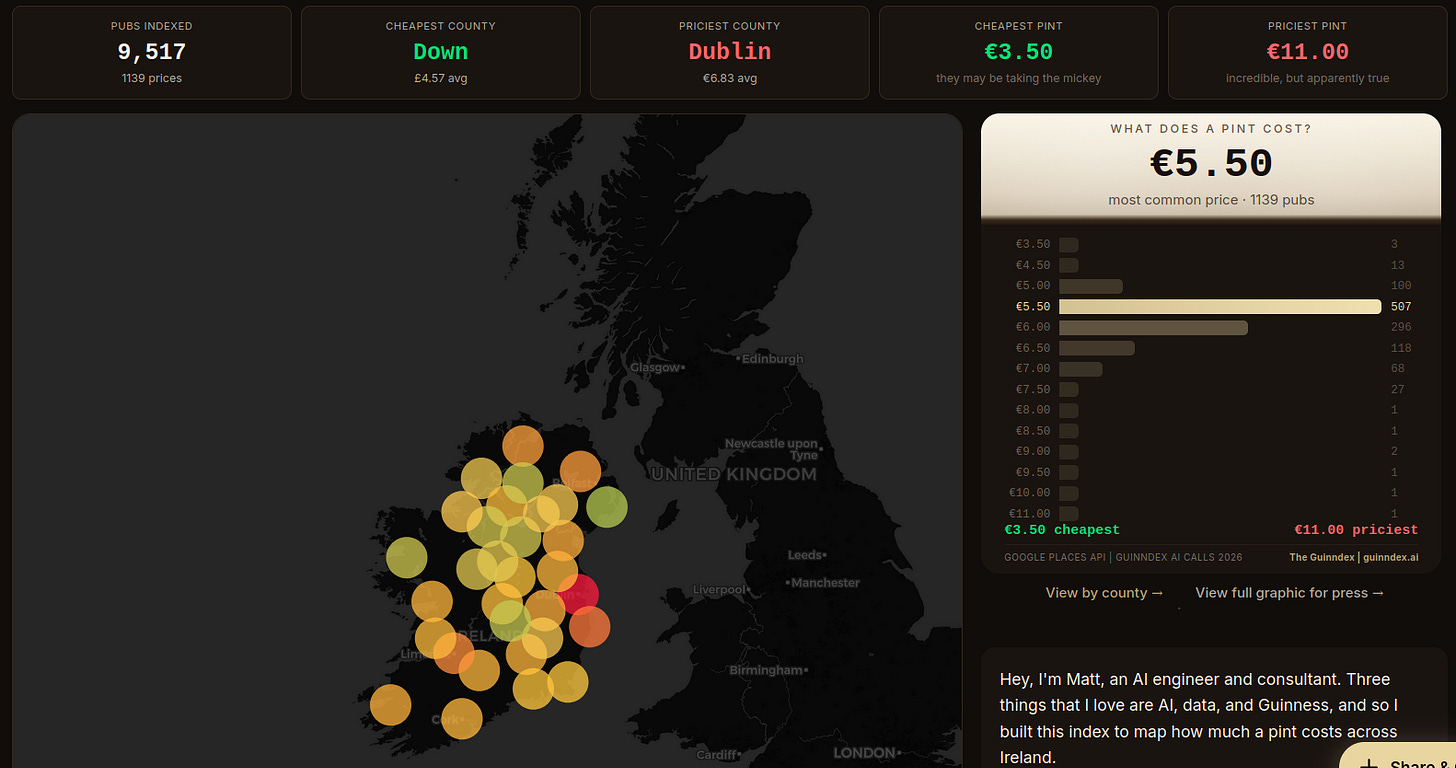
Página web de Guinndex.ai donde se puede visualizar los precios obtenidos