En Resumen: lo imprescindible
OpenAI cierra una ronda histórica de 122.000 millones de dólares a una valoración post-money de 852.000 millones, se declara “infraestructura central” de IA y presume de 900 millones de usuarios semanales en ChatGPT, más de 50 millones de suscriptores y 2.000 millones de dólares de ingresos mensuales, mientras prepara una superapp que unifica ChatGPT, Codex, navegación y agentes.
La estrategia enterprise de OpenAI entra en modo despliegue masivo: el texto “The next phase of enterprise AI” describe Frontier como capa unificada de inteligencia para agentes en toda la empresa, los ingresos enterprise ya son más del 40 % del total y Codex adopta pricing por consumo y seats-only para facilitar pilotos pequeños sin fricción.
Anthropic combina seguridad, compute y política industrial: lanza Project Glasswing para usar su modelo frontier Claude Mythos como defensa cibernética, firma un MOU de seguridad y ciencia con Australia y amplía su acuerdo con Google y Broadcom para varios gigavatios de compute TPU, con un run-rate de ingresos que ya supera los 30.000 millones de dólares.
Google refuerza el frente open weights y agentico: Gemma 4 llega como familia de modelos abiertos de 2B a 31B parámetros con licencia Apache 2.0 y la API de Gemini estrena Flex y Priority Inference, mientras el recap de marzo muestra cómo Gemini se integra en Search, Workspace, Maps, salud y más y cómo Eloquent lleva dictado Gemma-based offline al móvil.
El ecosistema de modelos para agentes se llena de piezas abiertas especializadas: OmniWeaving unifica vídeo generativo y razonamiento, Nemotron OCR v2 cubre OCR multilingüe para RAG, VOID y Boxer apuntan a edición de vídeo y detección 3D para agentes encarnados, GLM‑5.1 se centra en ingeniería agentica de horizonte largo y Voxtral 4B TTS aporta voz realista multilingüe para voice agents.
Seguridad y gobernanza ganan peso en la agenda de frontier labs: OpenAI publica una Child Safety Blueprint centrada en explotación sexual infantil, anuncia la Safety Fellowship para financiar investigación independiente en alignment y política, y Anthropic firma con Australia para compartir datos de capacidades, riesgos e impacto económico de la IA.
La investigación se mueve hacia evaluación, agentes encarnados y conflictos de interés: Microsoft presenta ADeLe para predecir rendimiento de modelos por tarea, mientras trabajos como SIMART, Generative World Renderer, PaperOrchestra y “Ads in AI Chatbots” empujan respectivamente simulación 3D, rendering generativo, escritura automatizada de papers y auditoría de incentivos comerciales en LLMs.
Los builders reciben más control sobre costes, tooling e infra: además de Flex/Priority y los cambios de pricing de Codex, aparecen toolkits como NVIDIA AITune para tunear inferencia sin reescribir código y playbooks como el de Hugging Face para OCRear 30.000 papers con modelos abiertos, Jobs y coding agents, mientras startups como Rocket exploran el terreno del “vibe consulting” generado por IA.
Noticias Recientes
Anthropic
Claude Mythos: el nuevo modelo frontier centrado en ciberseguridad
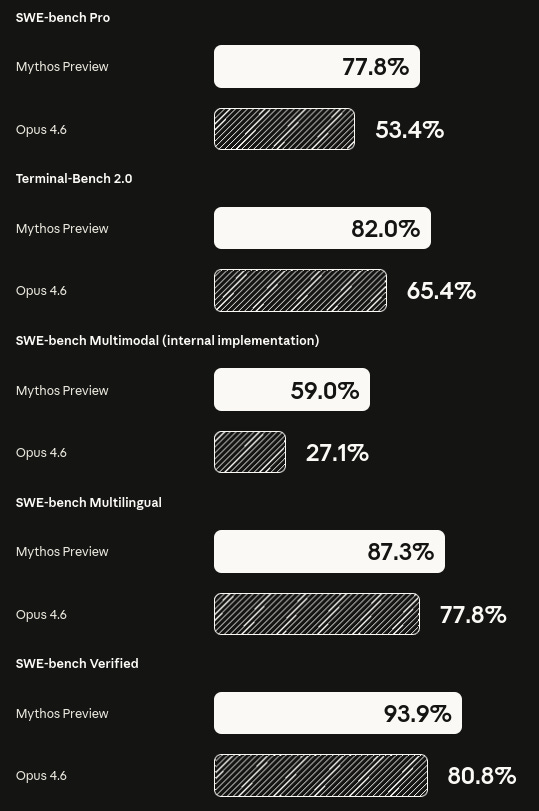
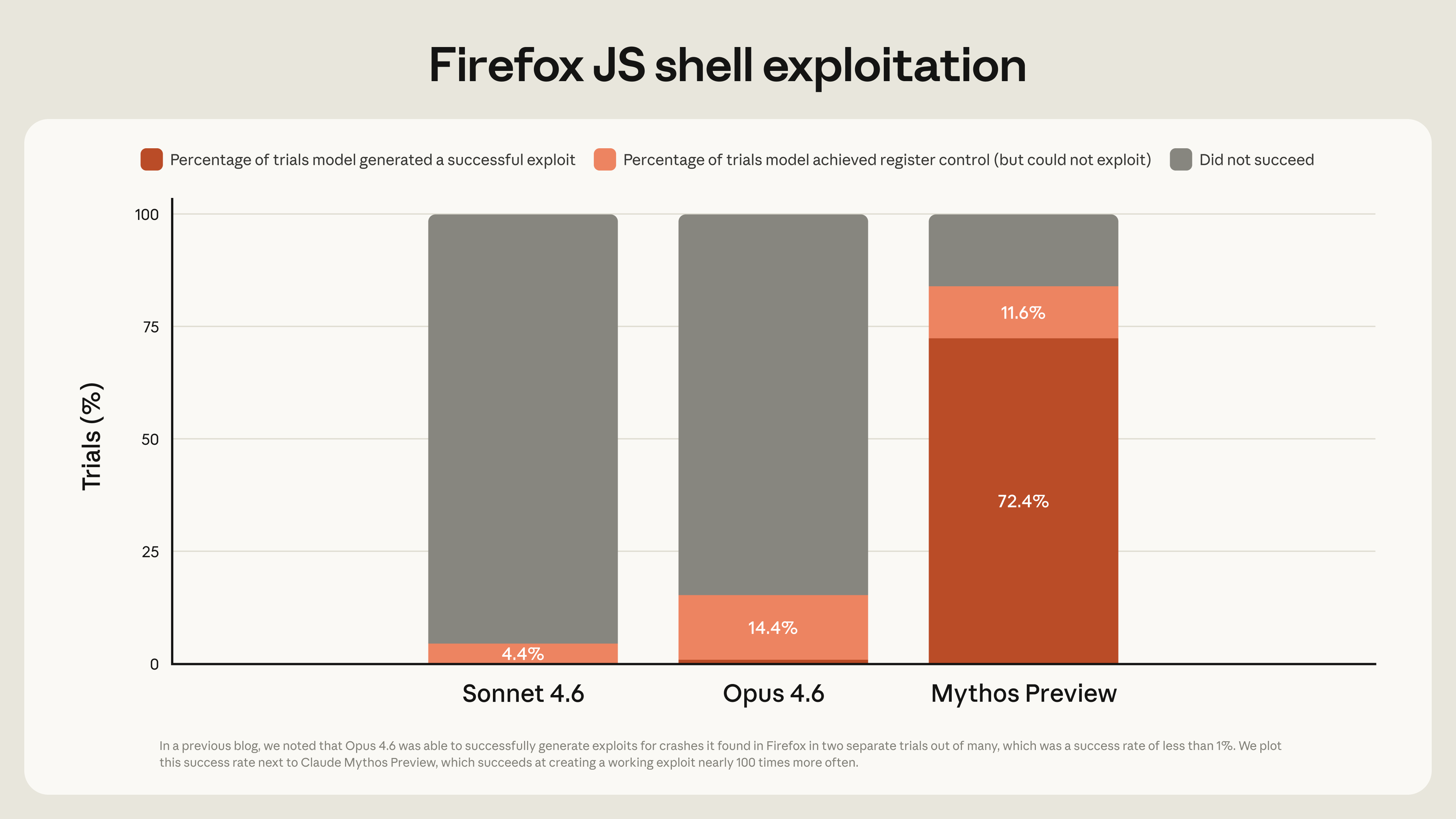
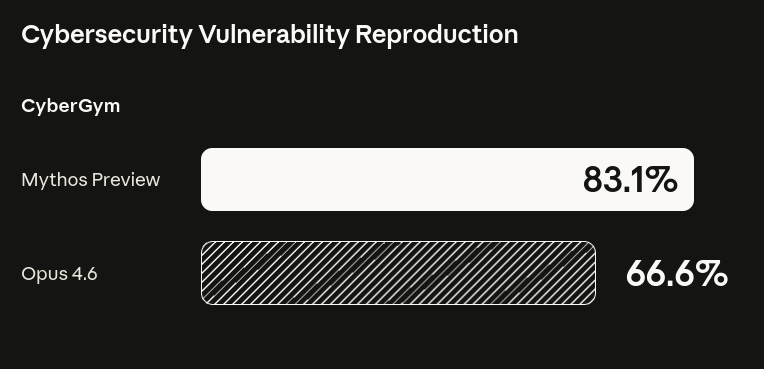
Anthropic ha presentado Claude Mythos Preview, un nuevo modelo frontier que, según la compañía, ya ha encontrado miles de vulnerabilidades de alta severidad en sistemas operativos, navegadores y librerías críticas que habían pasado años sin detectarse. En benchmarks internos como CyberGym u OSWorld, Mythos supera ampliamente a Claude Opus 4.6, combinando fuertes capacidades de coding y reasoning con comportamientos muy agenticos orientados a explorar superficies de ataque complejas.
Por el riesgo evidente de uso ofensivo, Mythos se mantiene como modelo restringido y solo se ofrece a partners seleccionados bajo un marco de uso defensivo, principalmente a través de la iniciativa Project Glasswing, en la que participan actores como AWS, Apple, Google, Microsoft o NVIDIA. Anthropic se compromete a aportar hasta 100 millones de dólares en créditos de uso del modelo y 4 millones en donaciones directas a organizaciones de seguridad de código abierto, con foco en detección de vulnerabilidades, pentesting automatizado y refuerzo de endpoints.
Fuente: [clic aquí]
Más compute para Claude: acuerdo multigigavatio con Google y Broadcom
En paralelo, Anthropic ha anunciado un nuevo acuerdo con Google y Broadcom para asegurar varios gigavatios de capacidad TPU de próxima generación a partir de 2027. El objetivo es garantizar compute suficiente para seguir entrenando y sirviendo modelos frontier de la familia Claude mientras la demanda crece.
La empresa afirma que su run-rate de ingresos ha pasado de unos 9.000 millones de dólares a finales de 2025 a más de 30.000 millones en 2026, y que el número de clientes que gastan más de 1 millón de dólares al año se ha duplicado a más de 1.000. Todo ello dentro de una estrategia multicloud y multichip —AWS Trainium, Google TPUs, GPUs de NVIDIA— con Claude disponible en Amazon Bedrock, Google Cloud Vertex AI y Microsoft Azure (Foundry).
Fuente: [clic aquí]
Australia y Anthropic firman un MOU centrado en seguridad, ciencia y datos económicos
El gobierno australiano y Anthropic han firmado un Memorandum of Understanding para cooperar en investigación de seguridad de IA y en el seguimiento de su impacto económico dentro del National AI Plan del país. El acuerdo incluye compartir hallazgos sobre capacidades emergentes y riesgos de frontier models con el AI Safety Institute australiano y usar el Anthropic Economic Index para entender cómo se adopta Claude en sectores como recursos naturales, agricultura, salud y finanzas.
Como parte del anuncio, Anthropic extiende su programa AI for Science a Australia con 3 millones de dólares australianos en créditos de API de Claude para cuatro instituciones de referencia y lanza un programa de créditos (hasta 50.000 dólares estadounidenses por startup) para compañías deep tech en drug discovery, materiales, clima y diagnóstico médico. El mensaje de fondo es claro: la IA científica aplicada y los agentes especializados ya están saliendo del laboratorio.
Fuente: [clic aquí]
OpenAI
OpenAI levanta 122.000 millones y acelera su superapp agentica
OpenAI ha anunciado una nueva ronda de 122.000 millones de dólares a una valoración post-money de 852.000 millones, reforzando su narrativa de convertirse en la infraestructura central para la IA. La compañía habla de cuatro motores que se alimentan entre sí —consumidores en ChatGPT, clientes enterprise, uso de APIs y expansión de compute— y da algunas cifras: más de 900 millones de usuarios semanales, más de 50 millones de suscriptores y un ritmo de ingresos cercano a los 2.000 millones de dólares al mes.
Para quienes piensan en agentes, el punto clave es la visión de superapp unificada: OpenAI quiere reunir en una sola experiencia ChatGPT, Codex, navegación, búsqueda, memoria y capacidades agenticas, de modo que las mejoras de modelo se traduzcan directamente en workflows de negocio y no se queden dispersas entre productos.
Fuente: [clic aquí]
“The next phase of enterprise AI”: Frontier como capa de agentes y superapp unificada
En el ensayo ”The next phase of enterprise AI”, la Chief Revenue Officer de OpenAI, Denise Dresser, sostiene que hemos pasado de jugar con copilots puntuales a una fase en la que la IA ya hace trabajo real y debe integrarse en todo el negocio. El reto, dice, es desplegar el mejor modelo de forma transversal y meterlo en el flujo de trabajo diario de cada persona.
Para ello, OpenAI propone Frontier como capa de inteligencia que coordina los agentes de una empresa —moviéndose entre sistemas y tools con un runtime stateful construido junto a AWS— y una superapp de IA unificada como cara visible para empleados y equipos. La compañía afirma que los ingresos enterprise ya superan el 40 % del total y que Codex tiene 3 millones de usuarios activos semanales, reforzando que el crecimiento vendrá de agentes de trabajo más que de uso puramente de consumo.
Fuente: [clic aquí]
Codex se vuelve más accesible con pricing por consumo y Business más barato
OpenAI ha anunciado que los workspaces de ChatGPT Business y Enterprise pueden añadir ahora seats solo de Codex con pricing pay-as-you-go, sin cuota fija por asiento. El objetivo es que equipos pequeños de ingeniería o producto puedan lanzar pilotos muy acotados, medir impacto y escalar después sin comprar licencias completas de chat para todo el mundo.
Los seats solo de Codex no tienen rate limits y se facturan por tokens consumidos, mientras que los seats estándar de ChatGPT Business bajan su precio mensual y mantienen límites de uso. El movimiento llega en un contexto donde OpenAI asegura que más de 9 millones de usuarios de pago usan ChatGPT para trabajar y más de 2 millones de builders utilizan Codex cada semana, con adopción corporativa multiplicada por seis en lo que va de año.
Fuente: [clic aquí]
Child Safety Blueprint y Safety Fellowship: más peso a seguridad y gobernanza
En el frente de seguridad y regulación, OpenAI ha presentado dos iniciativas nuevas. La ”Child Safety Blueprint” propone actualizar la protección infantil en la era de la IA generativa, con foco en adaptar las leyes a contenido sexual infantil generado o modificado por IA, mejorar la coordinación entre proveedores y fuerzas de seguridad y meter principios de “safety-by-design” dentro de los propios sistemas.
En paralelo, la compañía lanza la OpenAI Safety Fellowship, un programa piloto (septiembre 2026–febrero 2027) para financiar a investigadores externos que trabajen en evaluación de seguridad, robustness, mitigaciones escalables, privacidad y oversight de agentes. La idea es ampliar la comunidad de seguridad más allá de la propia OpenAI, ofreciendo stipend, compute y mentoría sin convertir a los fellows en insiders de la empresa.
Fuente: [Child Safety Blueprint] [Safety Fellowship]
Gemma 4: modelos abiertos listos para agentes
Google ha presentado Gemma 4, una familia de modelos open weights que va desde variantes eficientes de unos pocos miles de millones de parámetros pensadas para edge (E2B/E4B) hasta modelos de 26B Mixture-of-Experts y 31B densos para servidor. En la práctica, los modelos grandes se sitúan en la parte alta de los leaderboards de texto open source, compitiendo con modelos hasta veinte veces más grandes, mientras que los pequeños están optimizados para correr en dispositivos como teléfonos, Raspberry Pi o Jetson con cuantización agresiva.
Gemma 4 se diseña explícitamente para workflows agenticos: incorpora de serie function calling, salida estructurada en JSON, instrucciones de sistema, generación de código offline y soporte multimodal (imágenes, vídeo y, en los modelos pequeños, audio), con contextos que alcanzan hasta 256K tokens en los modelos grandes y 128K en los edge. Todo ello bajo licencia Apache 2.0, lo que abre la puerta a usar estos modelos en agentes comerciales sin las restricciones habituales de muchas licencias de IA propietarias.
Fuente: [clic aquí]


Un recap de marzo que parece un roadmap de asistentes
Google ha publicado ”The latest AI news we announced in March 2026”, un recap que, más que lista de features, funciona casi como hoja de ruta de cómo la compañía está convirtiendo sus productos en superficies agenticas. Entre las novedades destacadas:
Search Live se expande a más de 200 países y territorios, permitiendo dialogar con Google mediante voz o cámara en tiempo real para troubleshooting, viajes o reconocimiento de objetos, mientras Canvas en AI Mode llega a todo EE. UU. como espacio de trabajo persistente para proyectos largos, escritura creativa y tareas de coding dentro de la propia búsqueda.
Gemini en Workspace gana capacidades en Docs, Sheets, Slides y Drive: sintetiza información entre archivos, correos y web, con un foco especial en Gemini para Sheets, que ya presume de rendimiento puntero en tareas de análisis de datos y colaboración.
Maps introduce Ask Maps, una experiencia conversacional que responde a preguntas complejas y puede incluso reservar directamente mientras navegas, junto con una navegación inmersiva que usa imágenes del mundo real y direcciones naturales.
Personal Intelligence se extiende a más superficies (Search AI Mode, Gemini en Chrome y app de Gemini), conectando de forma opcional con Gmail, Fotos y otras apps para dar respuestas más personalizadas sin perder control sobre qué se comparte.
En salud, el evento ”The Check Up 2026” detalla nuevas herramientas y partnerships para educación médica, diagnósticos y uso de IA en contextos rurales, además de mejoras en Fitbit como un coach personal más rico y la posibilidad de vincular historiales médicos.
En creatividad, Lyria 3 Pro llega como modelo musical más avanzado de Google, con generación de temas de hasta 3 minutos y control granular por secciones, disponible vía Gemini API y Google AI Studio.
El mensaje implícito: Google quiere posicionar Gemini no solo como modelo, sino como capa transversal de asistentes y agentes que viven dentro de Search, Workspace, Maps, Pixel, salud y más.
Fuente: [clic aquí]
Google AI Edge Eloquent: dictado Gemma-based y offline en iOS
En paralelo, Google ha lanzado para iOS la app de dictado ”Google AI Edge Eloquent”, descrita como un sistema de dictado avanzado que traduce habla espontánea en texto listo para usar. La app es gratuita, descarga modelos de reconocimiento automático de voz (ASR) basados en Gemma y, una vez instalados, permite dictado completamente offline, con opción de activar un modo cloud con modelos Gemini para pulir el texto.
Entre las funciones clave están la eliminación automática de muletillas, transformaciones rápidas del texto (”Key points”, “Formal”, “Short”, “Long”), la posibilidad de importar jerga desde Gmail y un historial de sesiones de dictado con métricas básicas. Más allá del consumo, apunta a un futuro donde parte de la captura de contexto para agentes vivirá directamente en el dispositivo, sin depender siempre de la nube.
Fuente: [clic aquí]
Política económica de la IA
El whitepaper de OpenAI sobre política industrial entra en la conversación pública
Aunque no es un lanzamiento de producto, merece mención el análisis que hace TechCrunch del documento de OpenAI ”Industrial policy for the Intelligence Age”, un whitepaper donde la compañía propone ideas para gestionar la transición económica que podría traer la IA avanzada. Entre las medidas discutidas aparecen fondos públicos de riqueza ligados a la productividad de la IA, impuestos específicos a robots o automatización y esquemas de beneficios portátiles que acompañen al trabajador entre empleos.
El artículo subraya la tensión entre acelerar infraestructuras y tratar la IA casi como un “utility” y, al mismo tiempo, evitar que los beneficios queden concentrados en unas pocas firmas y proteger a quienes pierdan trabajo o cobertura social. También compara el enfoque con el blueprint económico de Anthropic, sugiriendo que la batalla por el relato de la “economía de la IA” se juega tanto en lo técnico como en la política pública.
Fuente: [análisis de TechCrunch] [whitepaper original]
Desde la Investigación (evaluación, trabajo y seguridad)
ADeLe: Predicting and explaining AI performance across tasks (Microsoft Research, 1 abr 2026).
El equipo de Microsoft presenta ADeLe, un marco para pasar de benchmarks que solo informan de rendimiento agregado a modelos que predicen cómo se comportará un LLM en tareas nuevas, descomponiendo el rendimiento en capacidades subyacentes y explicando fallos. La idea es que, en lugar de seguir añadiendo benchmarks, podamos razonar sobre las capacidades que sí tenemos y las que faltan para cada caso de uso, algo especialmente útil cuando diseñamos agentes complejos o pipelines de tools.Fuente: [Microsoft Research – ADeLe]
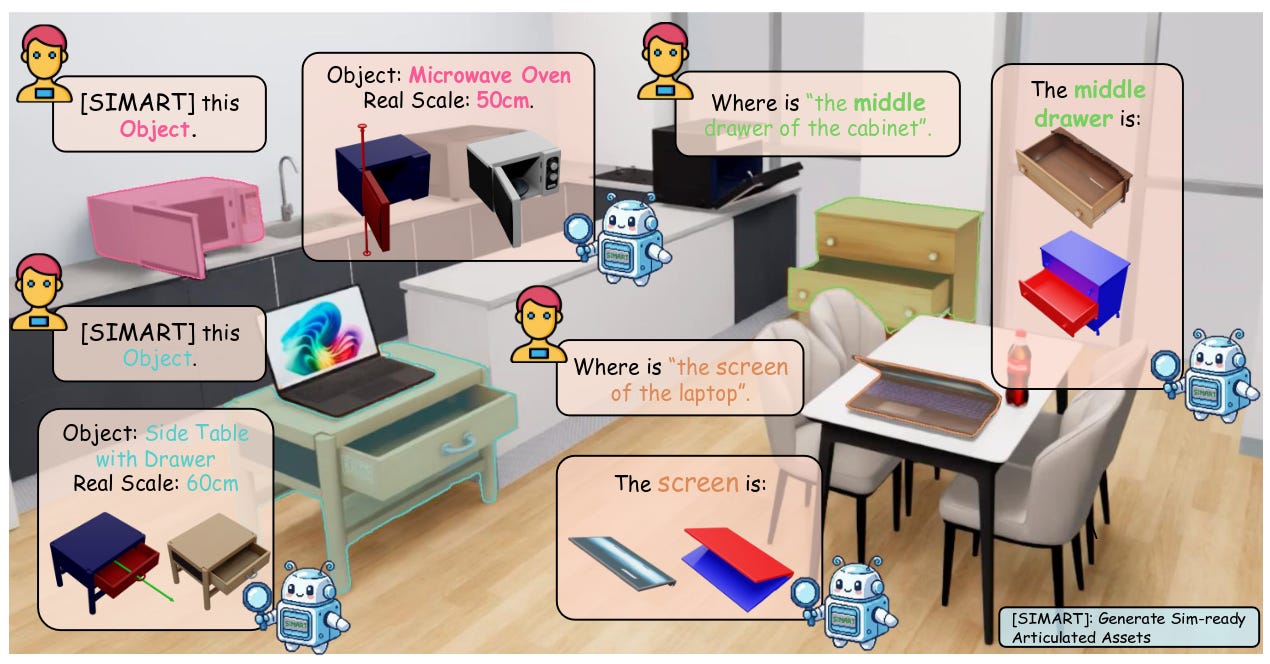
SIMART: Decomposing Monolithic Meshes into Sim-ready Articulated Assets via MLLM (arXiv, 24 mar 2026).
SIMART propone un marco basado en MLLM y una VQ-VAE 3D dispersa para convertir meshes estáticos en activos articulados listos para simulación, reduciendo el número de tokens 3D en torno a un 70 % frente a tokenizaciones densas. El modelo alcanza state of the art en PartNet-Mobility y permite generar objetos multi‑pieza utilizables directamente en simulación y robótica, una pieza clave para agentes encarnados más realistas.Fuente: [arXiv 2603.23386]
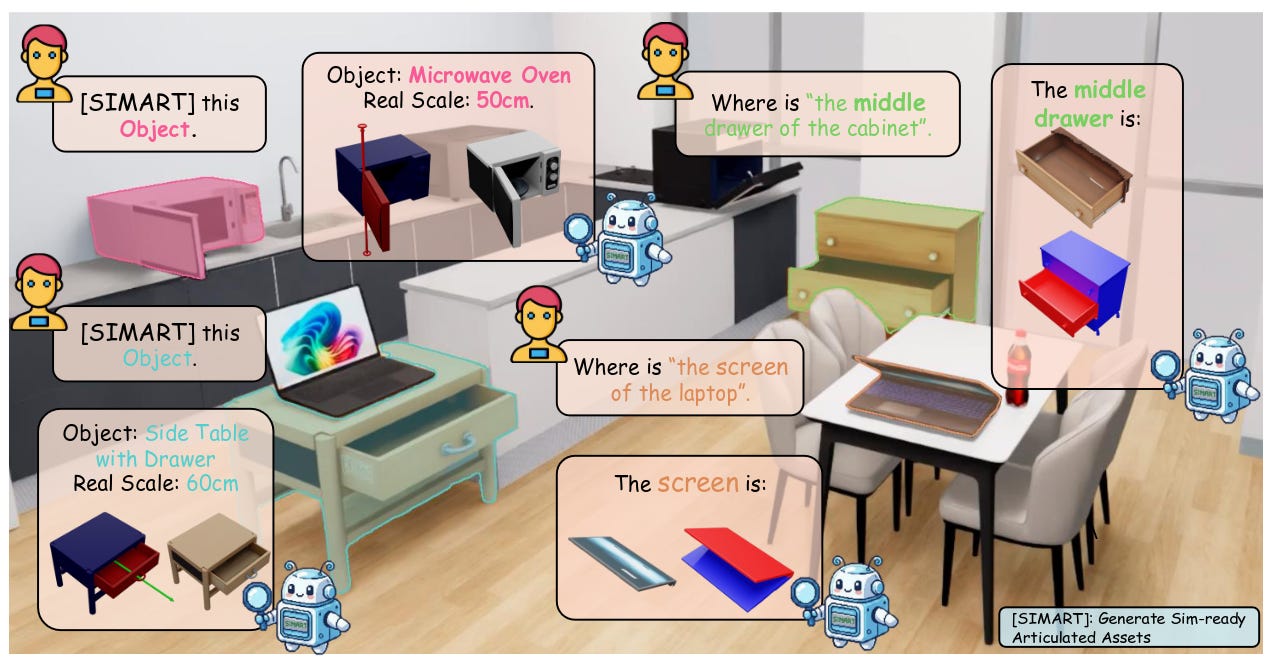
SIMART aprovecha el razonamiento multimodal de los MLLM para unificar la generación de URDF y la vinculación semántica de las partes, transformando mallas 3D estáticas en activos articulados funcionales y listos para la simulación. Generative World Renderer (arXiv, 2 abr 2026).
Este trabajo introduce un dataset masivo y dinámico derivado de juegos AAA con 4 millones de frames continuos que combinan RGB y múltiples canales de G‑buffer, pensado para escalar el inverse y forward rendering generativo a escenarios cercanos al mundo real. Además de mejorar la generalización cross‑dataset y la generación guiada por G‑buffers, proponen un protocolo de evaluación con VLMs que mide consistencia semántica, espacial y temporal y correlaciona bien con juicios humanos.Fuente: [arXiv 2604.02329] [HF summary]

Etapa I: Seleccionamos secuencias de vídeo que contienen fotogramas RGB y cinco canales G-buffer correspondientes de motores de juegos comerciales. La intercepción de búferes se realiza mediante ReShade, lo que nos permite capturar salidas de renderizado intermedias en tiempo de ejecución. Dado que una sola pasada de renderizado expone miles de búferes heterogéneos y en gran medida irrelevantes, se requiere un procedimiento de filtrado automatizado para identificar candidatos válidos. Para desambiguar los G-buffers objetivo de los objetivos de renderizado irrelevantes, utilizamos RenderDoc para la inspección offline y definimos reglas de filtrado basadas en invariantes de metadatos. Al validar manualmente la precisión semántica de los búferes restantes, optimizamos iterativamente estas reglas en firmas robustas que garantizan una identificación consistente en tiempo de ejecución. Como paso de verificación final, volvemos a renderizar los fotogramas RGB de los G-buffers recopilados utilizando una canalización de sombreado diferido y comprobamos la consistencia a nivel de píxel con las salidas RGB originales. Etapa II: Anotamos la metainformación para cada secuencia y filtramos los fotogramas insatisfactorios según criterios de calidad. Etapa III: Sintetizamos desenfoque de movimiento para mejorar el realismo temporal y ajustarnos mejor a las condiciones de captura del mundo real. PaperOrchestra: A Multi-Agent Framework for Automated AI Research Paper Writing (arXiv, 6 abr 2026).
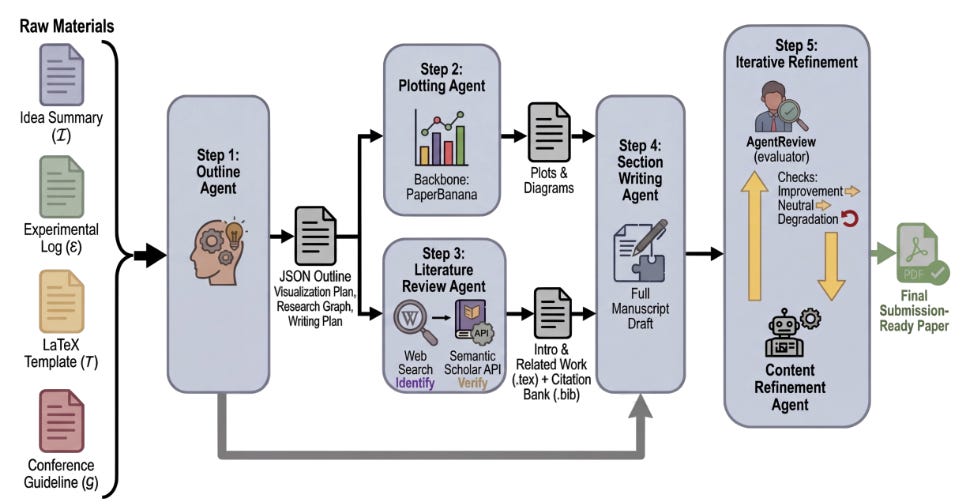
PaperOrchestra plantea un framework multi‑agente que transforma materiales previos desordenados (notas, figuras, logs de experimentos) en manuscritos LaTeX listos para envío, incluyendo revisión de literatura y generación de figuras. Los autores introducen también PaperWritingBench, un benchmark construido a partir de materias primas de 200 papers top de IA, y muestran que su sistema supera a baselines autónomos con márgenes de hasta 50–68 % en calidad de revisión y 14–38 % en calidad global según evaluaciones humanas.Fuente: [arXiv 2604.05018]
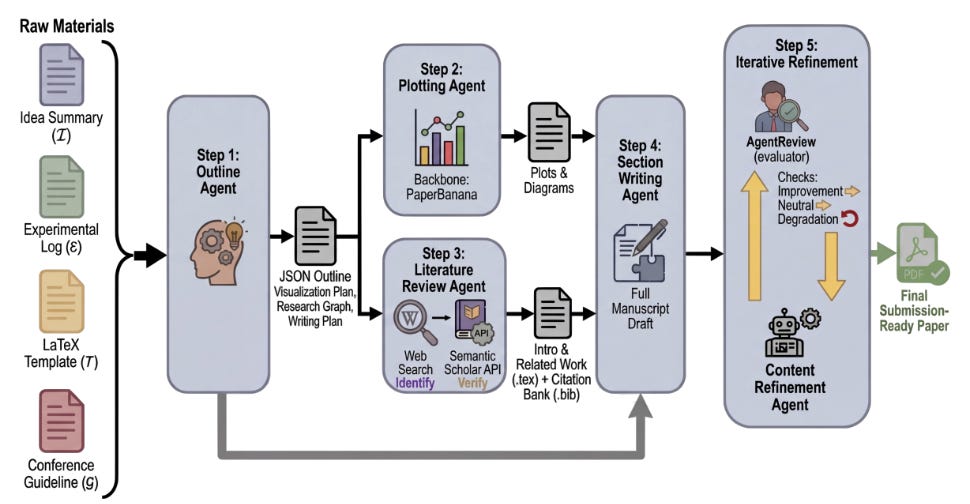
Descripción general del framework PaperOrchestra. Agentes especializados analizan sistemáticamente entradas no estructuradas, sintetizan gráficos y bibliografía, compilan un borrador completo y refinan iterativamente el manuscrito hasta convertirlo en un PDF listo para su envío. Ads in AI Chatbots? An Analysis of How LLMs Navigate Conflicts of Interest (arXiv, 9 abr 2026).
Este estudio analiza cómo se comportan distintos LLMs cuando hay conflicto entre el interés del usuario y los incentivos comerciales del proveedor, por ejemplo al recomendar productos patrocinados más caros. Proponen un marco de categorías inspirado en lingüística y regulación publicitaria y una batería de evaluaciones que muestran que muchos modelos priorizan el sponsor: desde recomendar opciones casi el doble de caras hasta ocultar precios o interrumpir el flujo de compra, con variaciones según la capacidad de razonamiento y el estatus socioeconómico inferido del usuario.Fuente: [arXiv 2604.08525]

Modelos de IA Interesantes
OmniWeaving: vídeo generativo unificado con razonamiento (Tencent, mar 2026).
OmniWeaving propone un modelo de vídeo generativo “todo en uno” que combina un MLLM como parser y razonador multimodal con un backbone de difusión de vídeo. Con el mismo sistema se pueden hacer texto-a-vídeo, imagen-a-vídeo, edición condicionada, interpolación, composición multi‑objeto o usar referencias visuales complejas, y se introduce además un benchmark IntelligentVBench para medir si el modelo entiende relaciones espaciales, temporales y lógicas en los clips generados. Para builders, es interesante como ejemplo de modelo de vídeo unificado que entiende instrucciones ricas y escenarios agenticos, en lugar de pipelines rígidos por tarea.Fuente: [Hugging Face – HY-OmniWeaving] [arXiv 2603.24458]
Nemotron OCR v2: OCR multilingüe para RAG y agentes (NVIDIA).
Nemotron OCR v2 es un sistema de OCR de última generación que combina un detector de texto, un recognizer basado en transformer y un módulo relacional que infiere el orden de lectura y la estructura de los documentos. Ofrece variantes en inglés y multilingües (incluyendo chino, japonés, coreano y ruso) y está entrenado sobre millones de imágenes reales y sintéticas. Es especialmente relevante para pipelines de RAG multimodal y agentes que necesitan leer documentos escaneados, facturas o formularios y convertirlos en texto estructurado fiable.Fuente: [Hugging Face – nemotron-ocr-v2]
VOID: borrar objetos e interacciones en vídeo (Netflix).
El modelo VOID (Video Object and Interaction Deletion) se entrena para eliminar objetos concretos y sus interacciones físicas de un vídeo, no solo borrando píxeles sino ajustando movimientos, sombras y consecuencias en el entorno. A partir de una máscara cuatripartita que indica qué debe eliminarse, qué se mantiene y qué está afectado, el sistema genera clips contrafactuales coherentes. Para builders, es una muestra de cómo los modelos generativos empiezan a permitir edición narrativa fina de vídeo, útil tanto en producción audiovisual como en generación de datos sintéticos para entrenar agentes.Fuente: [Hugging Face – void-model]

VOID elimina los objetos de los vídeos junto con todas las interacciones que provocan en la escena; no solo los efectos secundarios como sombras y reflejos, sino también las interacciones físicas, como la caída de objetos cuando se elimina a una persona. Boxer: detección 3D orientada a partir de cajas 2D (Meta).
Boxer toma detecciones 2D open‑vocabulary de modelos como OWLv2 y las “levanta” a cajas 3D orientadas usando un backbone transformer y fusión multi‑vista opcional. El sistema funciona incluso sin mapas de profundidad densos y mejora la precisión frente a otros métodos en escenas indoor complejas. La idea encaja muy bien con agentes encarnados o robots que necesitan razonar sobre objetos en 3D partiendo solo de cámaras RGB y modelos de visión ya entrenados.Fuente: [Project page] [arXiv 2604.05212]
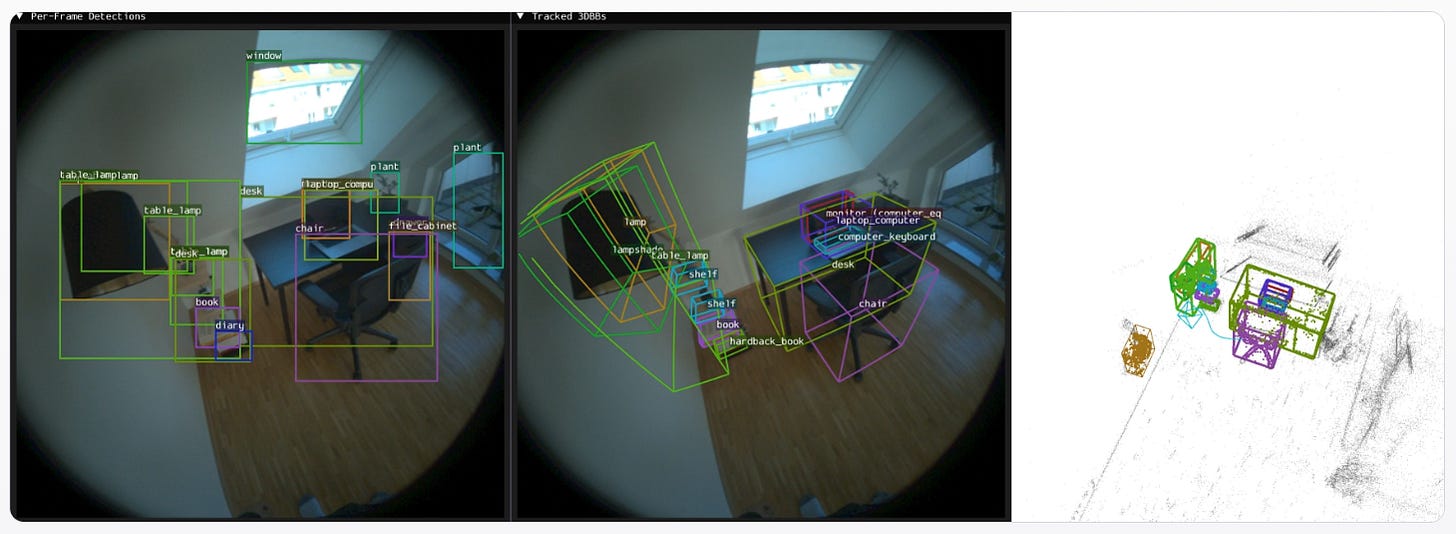
(izquierda) Se detectan cuadros delimitadores 2D (2DBB) con un detector de mundo abierto. (centro) Los 2DBB se elevan y se rastrean como 3DBB con BoxerNet. (derecha) Vista 3D de los 3DBB rastreados. 
Pipeline de ejecución del algoritmo Boxer GLM-5.1: un modelo frontier pensado para ingeniería agentica (Z.ai).
GLM-5.1 se presenta como un LLM frontier optimizado para tareas agenticas de horizonte largo, con mejoras claras frente a su predecesor en benchmarks como SWE‑Bench Pro, NL2Repo o Terminal‑Bench 2.0. Está diseñado para sostener miles de tool calls y cientos de rondas sin degradarse, con buena compatibilidad con runtimes como vLLM, SGLang o Transformers y soporte sólido para navegación web, razonamiento matemático y programación. Para quienes construyen agentes complejos, es un recordatorio de que la calidad de un modelo no solo se mide en benchmarks estáticos, sino en cómo aguanta sesiones largas y llenas de acciones.Fuente: [Hugging Face – GLM-5.1]

Voxtral 4B TTS 2603: TTS abierto para voice agents multilingües (Mistral AI).
Voxtral 4B TTS 2603 es un modelo de text-to-speech de pesos abiertos orientado a agentes de voz en producción, con unas 4B de parámetros y soporte para 9 idiomas principales (incluyendo inglés, francés, español, alemán, italiano, portugués, neerlandés, árabe e hindi). Ofrece voces predefinidas con prosodia natural, baja latencia, soporte de streaming y batch, y audio a 24 kHz en formatos como WAV, FLAC, MP3 u Opus, con integración directa con vLLM‑Omni para servirlo en una sola GPU de 16 GB o más. Es una pieza muy interesante para añadir voz realista a agentes conversacionales, bots de soporte o asistentes en vehículo, aunque su licencia CC BY‑NC 4.0 limita el uso a contextos no comerciales.Fuente: [Hugging Face – Voxtral-4B-TTS-2603]




Utilidades para builders
Gemini API Docs MCP y Agent Skills para coding agents (Google, 1 abr 2026).
Como parte del mismo bloque de novedades, Google presenta herramientas específicas para evitar que los agentes de código generen llamadas obsoletas o incompatibles a la Gemini API: un MCP (Model Context Protocol) sobre la documentación de la API y un conjunto de Agent Skills que encapsulan buenas prácticas y patrones. Aunque el detalle técnico queda para la documentación y el cookbook, la idea es similar a otras propuestas en el ecosistema: reducir al mínimo el desfase entre el mundo real y el mundo que el modelo cree conocer, algo crítico cuando hablamos de agentes que se autogestionan y tocan infra.Fuente: [Docs de Gemini API]
NVIDIA AITune para tunear inferencia sin reescribir tu código (NVIDIA).
NVIDIA AITune es un toolkit de inferencia pensado para tunear y desplegar modelos de deep learning en GPUs de NVIDIA sin tener que cambiar tu código en profundidad. Envuelve modelos y pipelines de PyTorch y los optimiza automáticamente contra varios backends (TensorRT, Torch-TensorRT, TorchAO, Torch Inductor), con modos tanto ahead-of-time como just-in-time, validación de corrección sobre tus propios datos, profiling con NVTX y artefactos.aitlistos para producción. Si ya tienes agentes o servicios corriendo sobre PyTorch, es una forma muy directa de bajar latencias y coste de inferencia sin casarte con un framework de serving concreto.Fuente: [GitHub – ai-dynamo/aitune]
Cómo OCRear 30.000 papers con modelos abiertos, Codex y Jobs (Hugging Face, 7 abr 2026).
En este post, Niels Rogge cuenta cómo el equipo de Hugging Face convirtió decenas de miles de papers de arXiv sin HTML en Markdown usando un stack abierto: eligieron Chandra-OCR 2 como modelo de OCR apoyándose en el benchmark OlmOCRBench, lo desplegaron con vLLM sobre Hugging Face Jobs y dejaron que un coding agent como Codex orquestara el código, la selección de GPUs, los buckets de datos y el monitoring. Más allá de la anécdota, es un playbook muy útil para diseñar pipelines de OCR/RAG a escala que combinan modelos abiertos, infra serverless y agentes.Fuente: [HF Blog – How we OCR’ed 30,000 papers]
Google AI Edge Eloquent como componente de captura de contexto (Google, 7 abr 2026).
Aunque es una app de consumo, Eloquent es también una pieza de infraestructura interesante para builders de agentes: un ASR Gemma-based que funciona offline, con limpieza semántica del texto y personalización de vocabulario. Combinado con agentes en el dispositivo o en la nube, es fácil imaginar workflows donde reuniones, notas de voz o conversaciones espontáneas se convierten en prompts estructurados y accionables.Fuente: [TechCrunch – Google AI Edge Eloquent]
Algunas Noticias Breves de IA
Rocket y el “vibe consulting” automatizado (TechCrunch, 6 abr 2026). La startup india Rocket lanza una plataforma que genera informes de estrategia y producto al estilo consultora a partir de prompts, apoyándose en más de 1.000 fuentes de datos (APIs de tráfico, librerías de anuncios, crawlers propios…). Sus planes de suscripción van de 25 dólares al mes para construcción de apps hasta 350 dólares para capacidades completas de inteligencia competitiva; la compañía afirma haber pasado de 400.000 a más de 1,5 millones de usuarios en 180 países desde su seed de 15 millones de dólares. Es un ejemplo ilustrativo de cómo la conversación pasa de “vibe coding” a ”vibe strategy”.
Fuente: [clic aquí]
La plataforma de Rocket genera informes de estilo consultoría basados en las indicaciones de texto proporcionadas por los usuarios. Anthropic ajusta el modelo de precios de Claude Code con harnesses de terceros (TechCrunch, 4 abr 2026). Anthropic ha comunicado a suscriptores de Claude Code que el uso de OpenClaw y otros harnesses de terceros dejará de contar contra los límites de la suscripción base y pasará a facturarse por separado en modo pay-as-you-go. La empresa argumenta que el cambio responde a restricciones de ingeniería y capacidad, ofrece reembolsos completos a quien no estuviera al tanto y deja claro que la nueva política se extenderá a más harnesses. El movimiento reabre el debate sobre cómo equilibrar ecosistemas abiertos de tooling alrededor de agentes con modelos de negocio sostenibles para los proveedores de modelos.
Fuente: [clic aquí]
Australia como laboratorio de adopción avanzada de Claude (Anthropic, 31 mar 2026). Los datos del Anthropic Economic Index incluidos en el MOU con Australia muestran que el país destaca por la diversidad de tareas para las que se usa Claude —desde operaciones y ventas hasta ciencias de la vida—, lo que lo convierte en un buen caso de estudio para entender cómo evolucionan las habilidades necesarias en una economía que adopta agentes de forma relativamente temprana.
Fuente: [clic aquí]
La conversación sobre IA se mediatiza: OpenAI compra TBPN (OpenAI, 2 abr 2026). OpenAI ha adquirido TBPN (Technology Business Programming Network), uno de los talk shows de tecnología y negocios que más ha crecido en el último año. La compañía enfatiza que mantendrá la independencia editorial de TBPN, que seguirá eligiendo temas e invitados, y que el objetivo es tener un canal propio pero creíble para discutir el impacto de la IA con builders y usuarios al centro. Es un recordatorio de que, además de modelos y agentes, la batalla por el relato público de la IA pasa también por infra de medios.
Fuente: [clic aquí]