En Resumen: lo imprescindible
Los agentes ya no son “un modelo”, sino un sistema completo: OpenAI refuerza ese framing con el update del Agents SDK (harness más capaz, memoria configurable y sandboxes nativos), empuja Codex hacia computer use + navegador in‑app + plugins/MCP, y además abre la puerta a modelos verticales con GPT‑Rosalind para workflows de ciencias de la vida (tool‑heavy y multi‑paso, con acceso controlado).
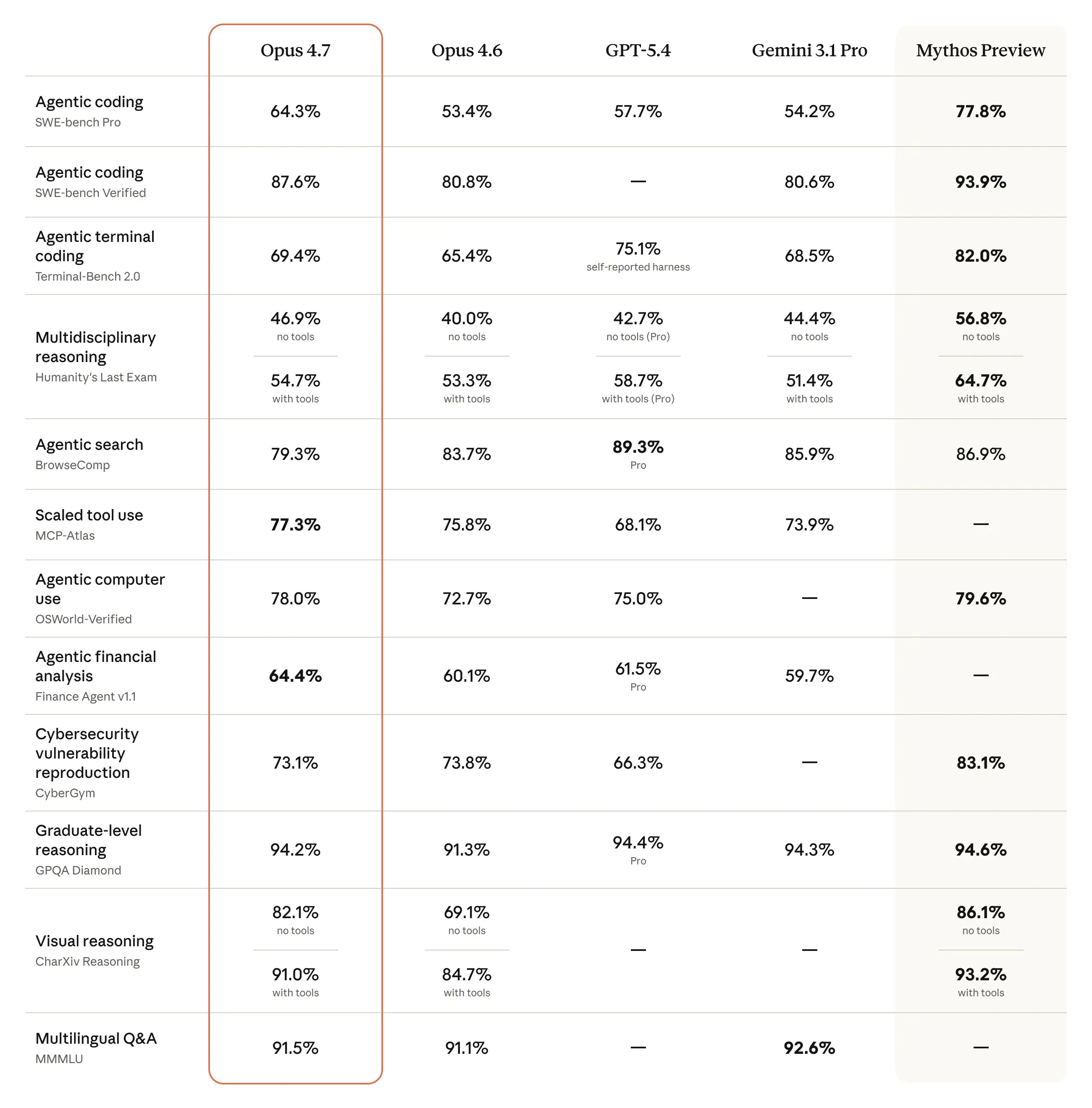
Claude Opus 4.7 sube el listón del trabajo largo y del “agentic coding”: Anthropic lo lanza como upgrade directo de Opus 4.6, con mejoras en instrucciones, visión en alta resolución y control más fino de esfuerzo (incluyendo un nuevo nivel
xhigh) orientado a workflows largos.Copilot entra en fase “gobernanza enterprise” (y “skills as packages”): GitHub anuncia data residency (US/EU) + FedRAMP, habilitación granular del Copilot Cloud Agent por organización, y empuja un ecosistema de skills con flujo tipo package manager vía
gh skill(pinning/provenance).Cloudflare intenta convertirse en la capa de inferencia de los agentes: unifica catálogo de modelos multi‑proveedor bajo una API, añade failover, y presenta primitivas “agent-first” como AI Search (híbrido vector + BM25) y Artifacts (almacenamiento versionado compatible con Git).
Open weights + inferencia frugal vuelven a estar en el centro: Qwen empuja un MoE open‑weights con foco explícito en agentic coding, y PrismML apuesta por cuantización extrema con Ternary Bonsai (1.58‑bit) como vía para desplegar LLMs bajo restricciones duras (edge/Apple).
Se acelera la multimodalidad “de verdad” (3D + audio largo + robótica): NVIDIA muestra Lyra 2.0 para mundos 3D explorables y añade Audio Flamingo Next para QA/chat sobre speech/sonidos/música con soporte nativo de audio largo; en paralelo, DeepMind actualiza Gemini Robotics‑ER 1.6 para embodied reasoning más fiable.
La evaluación y la investigación se vuelven más operativas: aparece GameWorld como benchmark verificable para agentes en juegos, y en arXiv se acumulan piezas sobre automatizar fine‑tuning (TREX), ejecutar ciencia “safe‑first” (SciFi), razonamiento tabular con scaffolds simbólicos (ReSS), frecuencia textual como señal de entrenamiento (Adam’s Law), encoders vision‑language con features espaciales (TIPSv2) y evolución colectiva de skills (SkillClaw).
La “superficie” del agente se mueve al escritorio (y al repo): Google lanza Gemini app en macOS con atajo global y compartir ventana; y, del lado builder, se consolidan utilidades prácticas (MCP para datos públicos, detección de tipos de archivo con IA, y
DESIGN.mdcurados para guiar agentes de UI).
Noticias Recientes
Anthropic
Claude Opus 4.7: upgrade directo orientado a coding largo (con safeguards cyber)
Anthropic anuncia Claude Opus 4.7 como disponibilidad general y lo posiciona como un salto específico en software engineering avanzado, tareas largas y ejecución con herramientas. La nota incluye mejoras en instruction following, una visión sustancialmente mejor (aceptando imágenes de mayor resolución) y un mensaje práctico: prompts/harnesses escritos para modelos anteriores pueden comportarse distinto porque Opus 4.7 toma instrucciones más literalmente.
También continúan el enfoque de seguridad en ciber: Opus 4.7 se lanza con salvaguardas que detectan y bloquean requests de usos cyber prohibidos o de alto riesgo, y abren un Cyber Verification Program para profesionales con casos legítimos. En términos de disponibilidad, lo listan en productos Claude, API y partners (incluyendo Amazon Bedrock, Vertex AI y Microsoft Foundry) con el mismo pricing que Opus 4.6.
Fuente: [clic aquí] [y aquí]
Claude Code “routines”: jobs autónomos por schedule, API o eventos de GitHub
En su documentación, Anthropic describe routines como una forma de poner Claude Code “en piloto automático”: una configuración guardada (prompt + repos + conectores) que corre como sesión cloud y puede dispararse por schedule, por API (un POST a un endpoint con bearer token) o por eventos de GitHub.
Esto es importante por el cambio de unidad de producto: deja de ser “chat/coding en vivo” y pasa a ser automation agentica con inputs periódicos (triage, revisión de PRs, verificación post‑deploy, mantenimiento de backlog). En la práctica, es la puerta de entrada a agentes que viven cerca de CI/CD y de herramientas de observabilidad, con ejecución no-interactiva.
Fuente: [clic aquí]
Identity verification en Claude: un paso más hacia plataformas “policy-first”
Anthropic está desplegando verificación de identidad en algunos casos de uso y checks de integridad de plataforma. Su explicación es explícita: reducir abuso, hacer cumplir usage policies y cumplir obligaciones legales, usando Persona como partner de verificación.
El detalle que importa para equipos es operativo: Anthropic afirma que no usa los datos de verificación para entrenar modelos, que las imágenes (ID/selfie) se alojan en Persona y que el objetivo es pedir el mínimo. Es otro síntoma de hacia dónde va el mercado agentico: más capacidad implica más controles de acceso.
Fuente: [clic aquí]
OpenAI
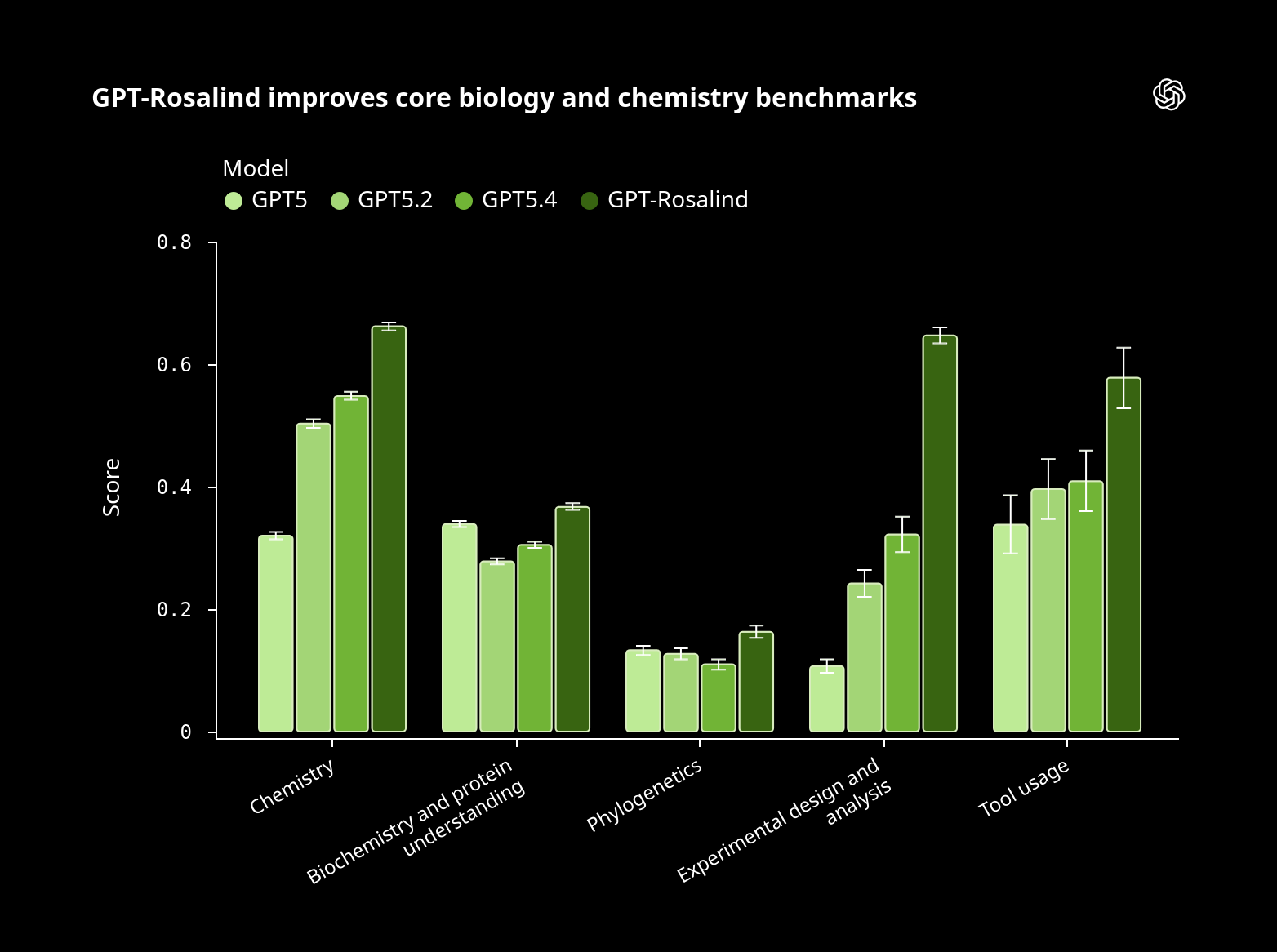
GPT‑Rosalind: modelo especializado para investigación en ciencias de la vida (preview)
OpenAI presenta GPT‑Rosalind, una serie de modelos orientados a workflows científicos en biología, drug discovery y medicina traslacional: lectura de evidencia publicada, razonamiento sobre moléculas/proteínas/genes y ejecución de flujos multi‑paso con herramientas (revisión de literatura, interpretación de secuencia‑a‑función, planificación experimental y análisis de datos).
La disponibilidad se plantea como research preview con acceso controlado para clientes cualificados (enfocado a entornos enterprise), y se acompaña de un Life Sciences research plugin para Codex (open en GitHub) que conecta el modelo con decenas de bases de datos y herramientas públicas para tareas repetibles.
Fuente: [clic aquí]
Agents SDK: más harness, más sandbox, menos pegamento
OpenAI ha publicado “The next evolution of the Agents SDK” con una tesis clara: para producir agentes útiles en producción no basta con un modelo; hace falta un harness que estandarice el bucle agentico (archivos, tools, ejecución) y que separe bien orquestación de compute para mejorar seguridad, durabilidad y escalabilidad.
La actualización pone el foco en ejecución en sandboxes de forma nativa, un Manifest para describir workspaces (montajes de archivos/inputs/outputs) y soporte para proveedores de sandbox (mencionan Blaxel, Cloudflare, Daytona, E2B, Modal, Runloop y Vercel). También explicitan un objetivo pragmático: resistir mejor prompt‑injection y minimizar exfiltración separando credenciales del entorno donde corre código generado por el modelo.
Fuente: [clic aquí]
Codex se sale del editor: computer use, navegador in‑app, memoria y automations
Con “Codex for (almost) everything”, OpenAI empuja Codex hacia un rol de “operador” que vive en todo el flujo de trabajo: computer use en background (ver/clicar/teclear con su propio cursor), navegador dentro de la app para dar instrucciones sobre páginas concretas y soporte de plugins + MCP para conectar herramientas.
Lo más relevante para agentes persistentes es el bloque de continuidad: reutilización de hilos, capacidad de programar trabajo futuro y un preview de memory para recordar preferencias/correcciones y reducir fricción en tareas repetidas. Si esto cuaja, Codex deja de ser un acelerador de “una sesión” y se convierte en un agente que mantiene estado y backlog.
Fuente: [clic aquí]
GitHub
gh skill: un package manager para skills de agentes (con pinning y “supply chain”)
GitHub lanza
gh skillen la CLI para descubrir, instalar, actualizar y publicar skills, siguiendo la especificación abierta de agentskills.io. La idea es que skills sean portables entre hosts (mencionan Copilot, Claude Code, Cursor, Codex y Gemini CLI) y que instalarlas sea tan trivial como un comando.
La pieza no-obvia es seguridad: GitHub lo trata como supply chain. Hablan de version pinning (tag o commit SHA), detección de cambios por tree SHA, y de meter “provenance” en el frontmatter del propioSKILL.md. Si los agentes van a ejecutar instrucciones + scripts, el control de versiones deja de ser “nice to have”.
Fuente: [clic aquí]
Copilot se endurece para enterprise: data residency + FedRAMP, y control granular del cloud agent
En el frente enterprise, GitHub anuncia data residency en US/EU para Copilot y disponibilidad de modelos/infra bajo estándares FedRAMP Moderate para clientes gubernamentales de EE. UU. La promesa es simple: features GA (agent mode, chat, cloud agent, code review, Copilot CLI) enrutan solo a endpoints regionales y compliance-certified.
Además, Copilot Cloud Agent gana gobernanza: ahora se puede habilitar de forma selectiva por organización (incluyendo uso de custom properties) y exponen endpoints REST para manejar el estado de la política. Es el tipo de cambio que marca madurez: agentes en cloud solo escalan si se pueden pilotar, auditar y desplegar por fases.
Fuente: [clic aquí] [y aquí]
Qwen
Qwen3.6-35B-A3B: open weights MoE con foco explícito en agentic coding
Qwen abre pesos de Qwen3.6‑35B‑A3B, un MoE con 35B totales / ~3B activos, y lo presenta con un framing muy directo: eficiencia sin perder rendimiento en agentic coding y benchmarks del estilo SWE‑bench. Además, insiste en compatibilidad práctica: uso en Qwen Studio/API y encaje con asistentes/agents de terminal.
Más allá del rendimiento puntual, el mensaje estratégico es que el segmento open‑weights quiere competir en el terreno donde se decide el valor real en 2026: tareas largas con tools, terminal, repos reales y evaluación “end‑to‑end”.
Fuente: [clic aquí] [HuggingFace]

NVIDIA
Lyra 2.0: mundos 3D explorables generados (y exportables a simulación)
NVIDIA Research presenta Lyra 2.0, un framework para generar walkthrough videos controlados por cámara y “levantarlos” a 3D mediante reconstrucción feed‑forward, con el objetivo de producir mundos persistentes y explorables (no solo clips). La demo se apoya en una GUI interactiva para planear trayectorias, revisitar zonas y expandir el escenario, y muestra exportación a 3D Gaussian Splats / meshes para su uso en motores y simuladores (por ejemplo, Isaac Sim).
La aportación técnica ataca dos fallos típicos del largo horizonte: spatial forgetting (cuando el modelo “pierde” regiones al salir del contexto) y temporal drifting (degradación acumulativa). Lo resuelven usando geometría por frame como memoria espacial para retrieval/correspondencias (routing de información) y entrenando con self‑augmented histories para que el modelo aprenda a corregir drift en lugar de propagarlo.
Fuente: [proyecto] [paper]

Benchmarks
GameWorld: evaluación estandarizada y verificable de agentes multimodales en juegos
GameWorld propone un benchmark de agentes en juegos de navegador que intenta resolver un problema recurrente en evaluaciones “agentic”: la verificación. En lugar de depender de heurísticas visuales o de un LLM‑as‑judge, el framework usa estado serializado del juego para medir progreso/éxito de forma reproducible, y unifica dos interfaces: computer‑use (teclado/ratón) y acciones semánticas vía parsing determinista.
El suite cubre 34 juegos y 170 tareas en cinco géneros (runner, arcade, platformer, puzzle y simulation), y los resultados reportados sugieren que los agentes actuales hacen progreso parcial pero aún están lejos de cerrar tareas de forma fiable y de los baselines humanos (novato/expert) bajo el mismo presupuesto.
Fuente: [proyecto] [paper] [HF]

Cloudflare
“Agents Week”: inferencia multi‑proveedor + búsqueda + storage versionado para agentes
Cloudflare presenta su AI Platform como una capa de inferencia pensada para agentes: un catálogo de 70+ modelos de múltiples proveedores detrás de un endpoint unificado, con énfasis en observabilidad de coste y fiabilidad (incluido failover automático cuando un proveedor cae). La tesis es muy de producción: los agentes encadenan llamadas, así que cada 50ms y cada error “se multiplican” en cascada.
Pero el movimiento más interesante es el paquete de primitivas: AI Search como “search primitive” plug‑and‑play (híbrido vector + BM25, metadata boosts, instancias por agente/cliente) y Artifacts como filesystem versionado compatible con Git para persistir estado de sesiones y sandboxes, con un roadmap explícito de escala “millones de repos”.
Fuente: [clic aquí] [aquí] [y aquí]
Google y Google DeepMind
Gemini Robotics‑ER 1.6: embodied reasoning más preciso (pointing, success detection e instrument reading)
DeepMind publica Gemini Robotics‑ER 1.6 como actualización de su modelo de razonamiento para robótica, reforzando capacidades que suelen romper agentes físicos en el mundo real: razonamiento espacial con pointing, multi‑view reasoning, detección fiable de “task success” y una habilidad nueva y muy industrial: leer instrumentos (p. ej., gauges) con precisión.
La señal importante es de producto: lo ofrecen vía Gemini API / Google AI Studio y comparten ejemplos/Colab, apuntando a que este tipo de modelos acaben integrándose como “capa alta” que llama tools (Search, VLA u otras funciones) más que como un monolito que lo hace todo.
Fuente: [clic aquí]
, scissors (1), paintbrushes (1), pliers (6), and a collection of garden tools which can be interpreted as a single group or multiple points. It does not point to requested items that are not present in the image — a wheelbarrow and Ryobi drill. In comparison Gemini Robotics-ER 1.5 fails to identify the correct number of hammers or paint brushes, misses the scissors altogether, hallucinates a wheelbarrow and lacks precision on plier pointing . Gemini 3.0 Flash is close to Gemini Robotics-ER 1.6, but does not handle the pliers as well.")
Gemini app llega a macOS: atajo global y “share window” como contexto instantáneo
Google lanza la Gemini app en macOS como experiencia nativa: aparece con un atajo global y permite compartir una ventana para que el asistente vea el contexto (incluyendo ficheros locales mostrados en pantalla). Es un enfoque muy “agent surface”: menos pestañas y más ayuda pegada al trabajo que ya estabas haciendo.
El mensaje de roadmap es claro: esto es “la primera versión” de un asistente de escritorio más personal y proactivo. Si lo cruzas con computer use en Codex y con el empuje de workflows largos, la batalla se está moviendo hacia quién domina el entorno de trabajo, no solo el chat.
Fuente: [clic aquí]
PrismML
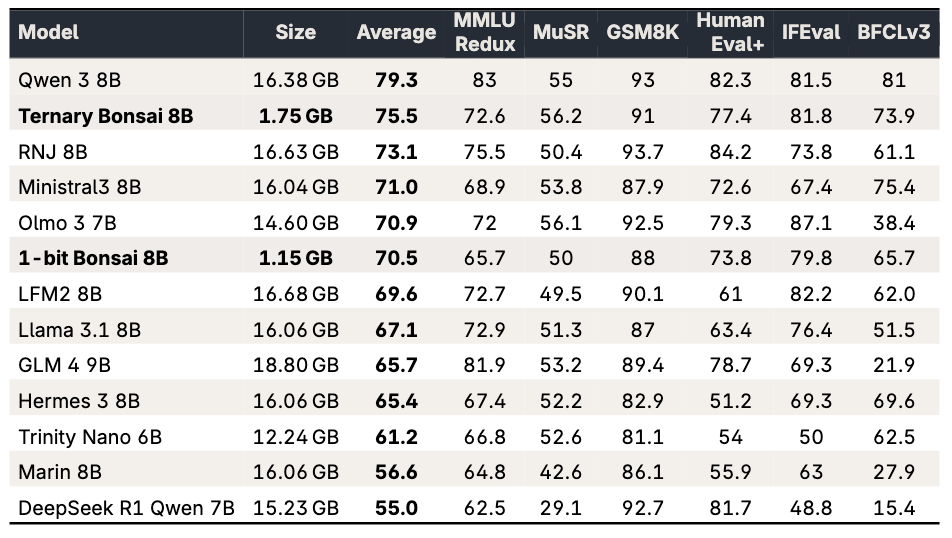
Ternary Bonsai: LLMs de 1.58 bits “sin escapatorias” de precisión
PrismML anuncia Ternary Bonsai, una familia de modelos con representación ternaria (1.58‑bit) a través de toda la red (embeddings, atención, MLPs y head), sin capas “en FP16” como excepción. La idea es estricta: pesos cuantizados en tres estados {-s, 0, +s} (con escala compartida por grupos) para maximizar densidad de inteligencia por GB.
En benchmarks, la nota afirma mejoras consistentes frente a su línea 1‑bit (p. ej., el 8B sube ~5 puntos de media) con un incremento de memoria moderado, y lo posiciona como opción para despliegues con restricciones duras (móvil/edge). También remarcan soporte nativo en Apple vía MLX y disponibilidad de pesos bajo Apache 2.0.
Fuente: [clic aquí]
Desde la Investigación (arXiv, agentes y evaluación)
Autogenesis: A Self-Evolving Agent Protocol (2026-04-16).
Propone un protocolo para agentes que evolucionan su propio comportamiento, con foco en cómo se “actualiza” la política del agente sin romper consistencia ni perder trazabilidad del proceso.Fuente: [clic aquí]
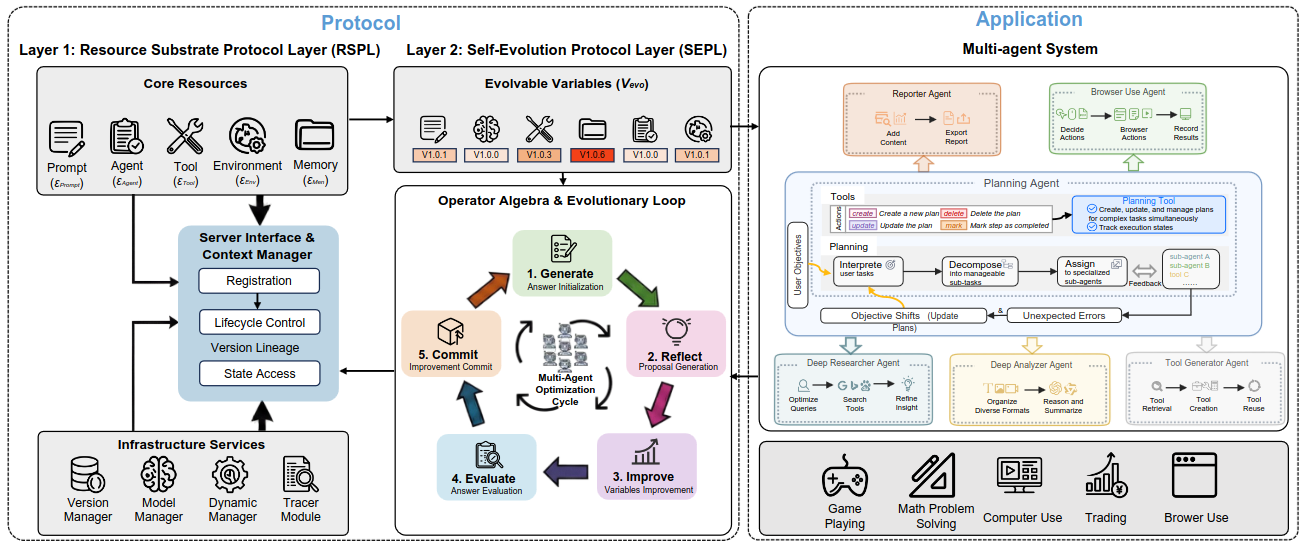
Arquitectura del protocolo Autogenesis Atropos: Improving Cost-Benefit Trade-off of LLM-based Agents under Self-Consistency with Early Termination and Model Hotswap (2026-04-16).
Explora cómo mejorar la relación coste‑calidad con ideas como early termination y “model hotswap”, un enfoque muy alineado con producción: no siempre quieres el mismo modelo ni el mismo esfuerzo en cada paso del loop.Fuente: [clic aquí]
TREX: Automating LLM Fine-tuning via Agent-Driven Tree-based Exploration (2026-04-15).
Presenta un sistema multi‑agente que intenta automatizar de extremo a extremo el ciclo de fine‑tuning (desde investigación de datos/estrategia hasta entrenamiento y evaluación), modelando el proceso experimental como un árbol de búsqueda para reutilizar resultados y planificar exploración.Fuente: [clic aquí]
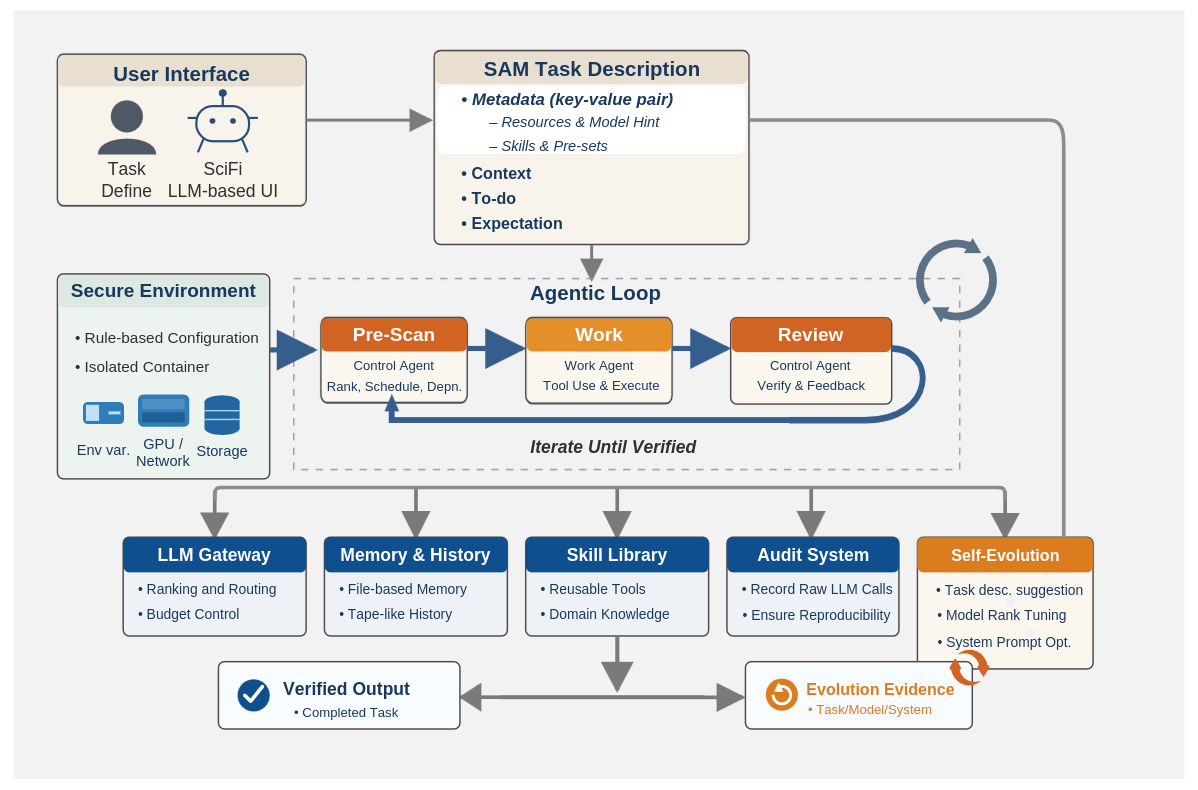
SciFi: A Safe, Lightweight, User-Friendly, and Fully Autonomous Agentic AI Workflow for Scientific Applications (2026-04-14).
Propone un framework agentico “safe-first” para ejecutar tareas científicas bien definidas, combinando entorno aislado, un loop en tres capas y un mecanismo do‑until auto‑evaluado para reducir riesgo y aumentar fiabilidad en despliegues reales.Fuente: [clic aquí]
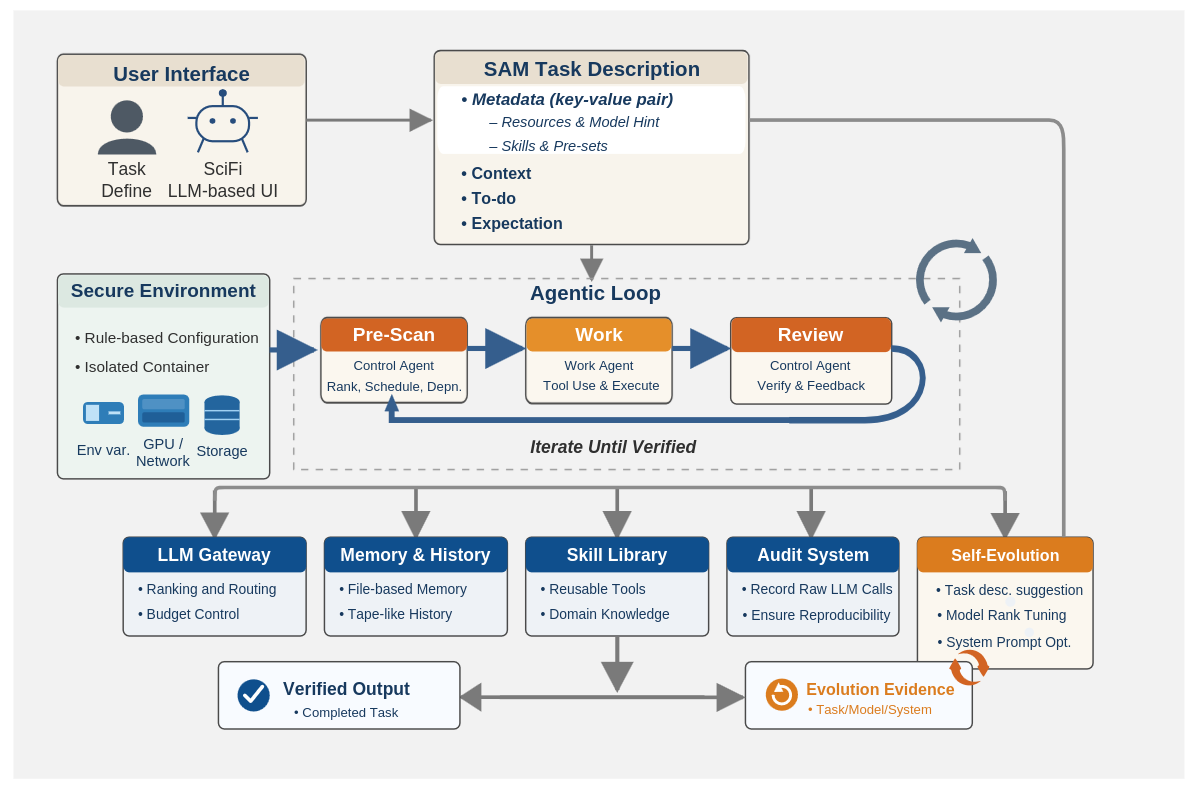
Arquitectura del sistema de agentes SciFi, que indica la seguridad garantizada por un funcionamiento ambiental seguro, la usabilidad proporcionada por una estructura de bucle de tres agentes que funciona bajo condiciones concretas de “hacer hasta” con fácil intercambio de LLM y la extensibilidad a través de una interfaz de lenguaje natural. ReSS: Learning Reasoning Models for Tabular Data Prediction via Symbolic Scaffold (2026-04-15).
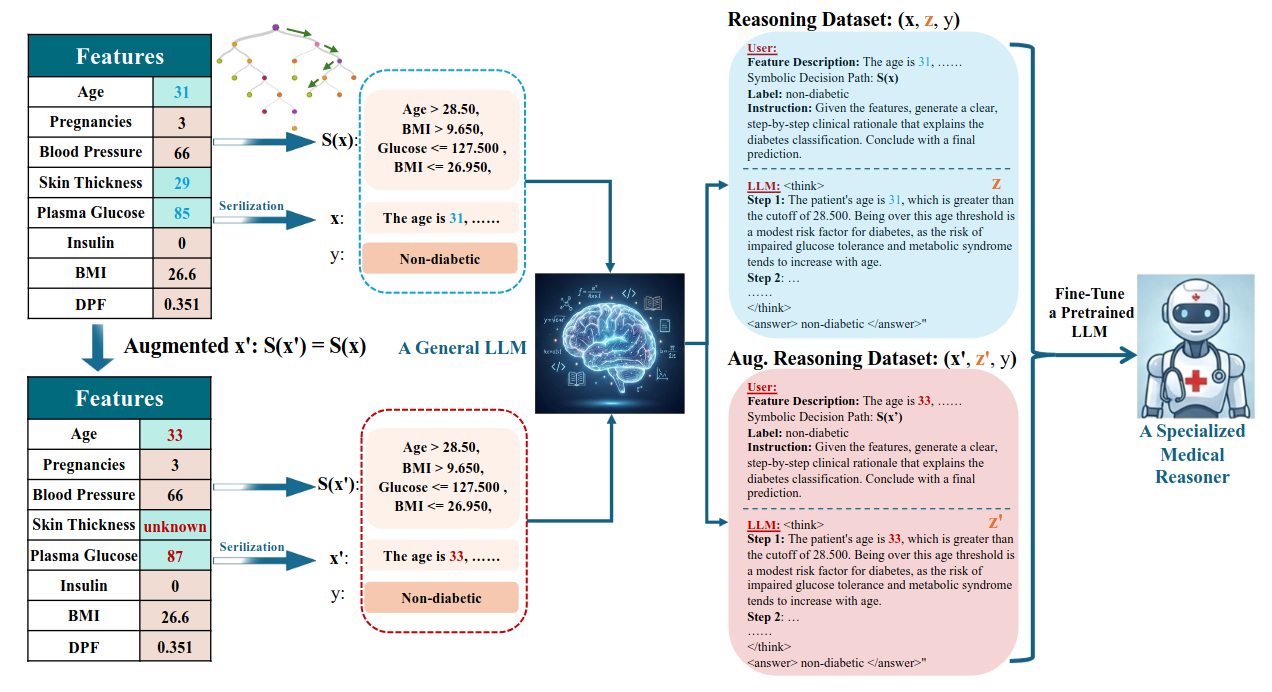
Usa un decision tree para extraer rutas de decisión como “scaffolds” simbólicos y guiar a un LLM a generar explicaciones ancladas en esa lógica; con ese dataset, entrenan un modelo de razonamiento tabular y proponen métricas para medir fidelidad (p. ej., tasa de alucinación).Fuente: [clic aquí]
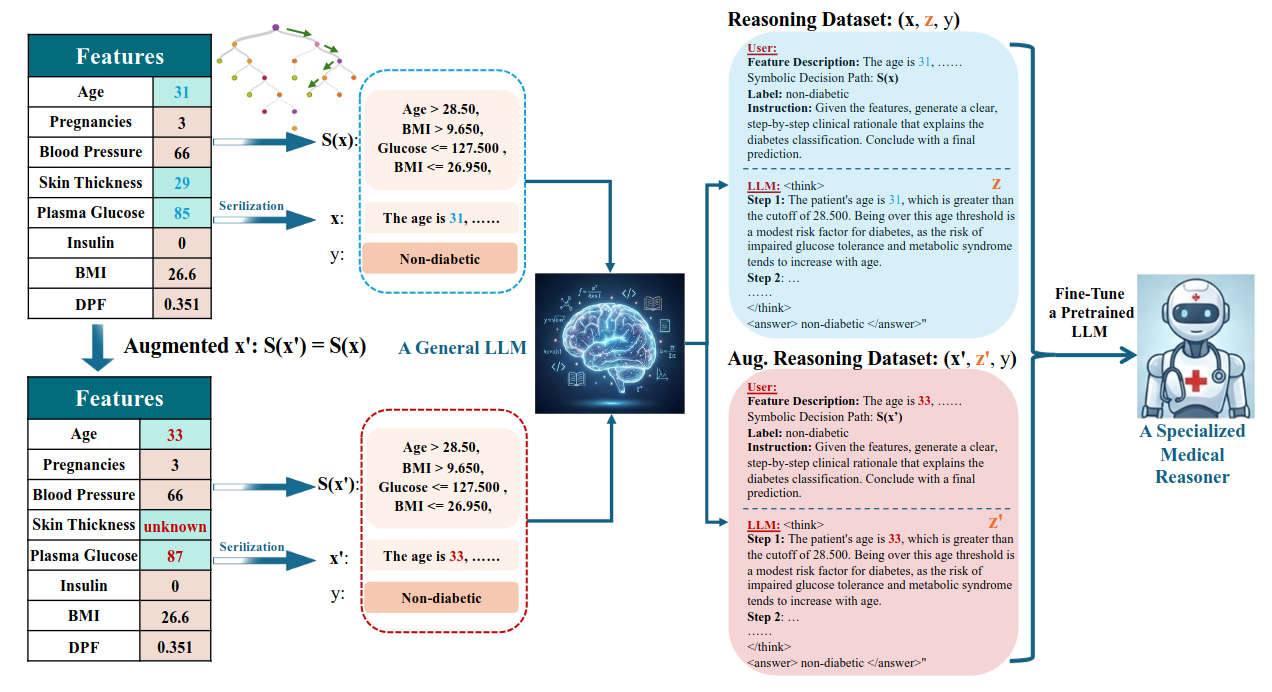
Ilustración del proceso ReSS aplicado al problema de la predicción de la diabetes Adam’s Law: Textual Frequency Law on Large Language Models (v2: 2026-04-07).
Abre una línea curiosa: tratar la frecuencia textual como señal útil para prompting y fine‑tuning, con un pipeline que estima frecuencia, parafrasea hacia formulaciones más frecuentes y entrena con un currículo que prioriza inputs “más comunes” antes de los raros.Fuente: [clic aquí]
TIPSv2 — g/14 (vision‑language con features espaciales, 2026).
Modelo de vision‑language que no solo produce un embedding global, sino también tokens por patch (features espaciales) alineados con texto; útil para tareas tipo feature visualization y zero‑shot (incluyendo segmentación) donde importa la estructura espacial, no solo la clase.Fuente: [HF] [GitHub]
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver (2026-04-09).
Framework para que agentes basados en “skills” evolucionen con uso real: captura trayectorias, las agrega y un “evolver” traduce patrones recurrentes en actualizaciones de skills sincronizadas entre usuarios (con un proxy local + un evolve server y skills en formatoSKILL.md).Fuente: [paper] [GitHub]


Modelos de IA Interesantes
Audio Flamingo Next (NVIDIA, audio‑language).
Checkpoint instruction‑tuned para conversación y QA sobre speech, sonidos ambientales y música, con soporte nativo de audio largo (hasta 30 minutos) y prompts con timestamps; también sirve para tareas tipo ASR/AST y captioning.Fuente: [clic aquí]
HY‑World 2.0 (Tencent, 3D world model).
Modelo multimodal para reconstruir/generar mundos 3D (meshes / 3DGS) desde texto, imágenes (single/multi‑view) o vídeo, apostando por activos editables e importables en Blender/Unity/Unreal.Fuente: [clic aquí]
Gemini 3.1 Flash TTS (Google, preview).
Nueva generación de text‑to‑speech con más control y expresividad: “audio tags” para dirigir estilo/ritmo, diálogo multi‑speaker, soporte 70+ idiomas y watermark SynthID. Disponible en preview vía Gemini API/AI Studio y Vertex AI.Fuente: [clic aquí]
ERNIE‑Image (Baidu, text‑to‑image).
Modelo open de generación de imagen con Diffusion Transformer (DiT) + Prompt Enhancer, con foco en instruction following, render de texto y generación estructurada (posters, cómics, layouts).Fuente: [clic aquí]
ERNIE‑Image‑Turbo (Baidu, text‑to‑image).
Variante destilada/optimizada para latencia: apunta a buena estética y fidelidad en ~8 steps (vs ~50), manteniendo buen control para prompts complejos y texto en imagen.Fuente: [clic aquí]
Utilidades para builders
GAIA (AMD, local agents): framework open source para montar agentes locales en Python/C++ optimizados para hardware AMD (sin cloud ni API keys).
Fuente: [clic aquí]
data.gouv.fr MCP Server (datagouv-mcp): servidor MCP oficial (Python) para que agentes (Claude/ChatGPT/Gemini, etc.) puedan buscar, explorar y analizar datasets y dataservices de data.gouv.fr directamente desde la conversación.
Fuente: [clic aquí]
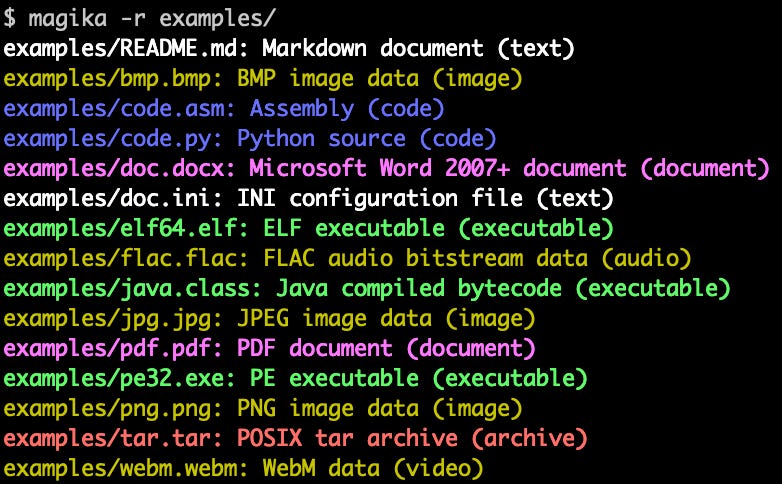
Magika (Google): detección de tipo de archivo (MIME/content type) con IA, rápida y precisa; útil en pipelines de seguridad, ingestión y triage automático, con CLI y bindings (Python/JS/Rust/Go).
Fuente: [clic aquí]
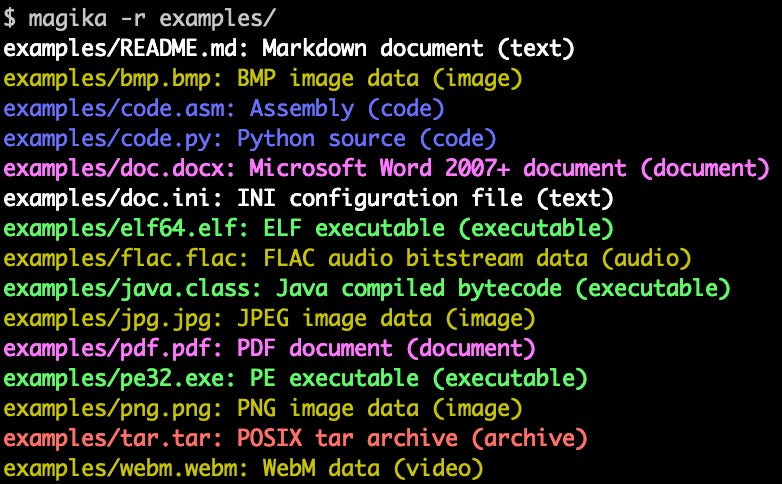
Ejemplo en la terminal de la salida de Magika Awesome DESIGN.md (VoltAgent): colección curada de archivos
DESIGN.md(formato Stitch) para “anclar” a agentes de UI a un estilo concreto: lo copias a tu repo y el agente genera interfaces consistentes con ese look & feel.Fuente: [clic aquí]