

En Resumen: lo imprescindible
GPT‑5.5 consolida la semana como “la pelea por el agente que termina el trabajo”: OpenAI lo presenta como su modelo más fuerte en agentic coding hasta la fecha, con mejoras críticas en token efficiency (más rendimiento con menos tokens) como requisito real para agentes que iteran y validan de forma autónoma.
Los “agentes de equipo” se vuelven un producto nativo: ChatGPT lanza workspace agents para que equipos operen agentes compartidos con permisos, memoria y ejecución en cloud (Slack incluido), mientras GitHub integra la visibilidad y control de agent sessions directamente en Issues y Projects.
Privacidad y gobernanza como herramientas operativas: OpenAI libera Privacy Filter (modelo open-weight para redactar PII localmente) y publica HealthBench para el sector clínico, moviendo el foco de las políticas abstractas a la infraestructura auditable.
La adopción enterprise escala con casos de impacto real: Anthropic y NEC anuncian el despliegue de Claude a 30.000 empleados en Japón, mientras Mercadona Tech reporta ahorros del 90% tras reconstruir su buscador en un mes apoyándose en Claude Code.
La frontera de la percepción se expande: Meta presenta Sapiens 2 (modelos fundacionales humanos en 4K) y Ai2 libera WildDet3D, impulsando la capacidad de los modelos para entender humanos y objetos en el espacio 3D a partir de imágenes sencillas.
Investigación: optimización de costes y seguridad multi-turno: La academia se centra en reducir el “tax” de las herramientas (MCP), proponer memorias estructuradas más baratas (StructMem) y alertar sobre ataques que explotan la moderación stateless en interacciones largas.
Noticias Recientes
OpenAI
OpenAI lanza GPT‑5.5 y sube el techo práctico del “agentic coding”
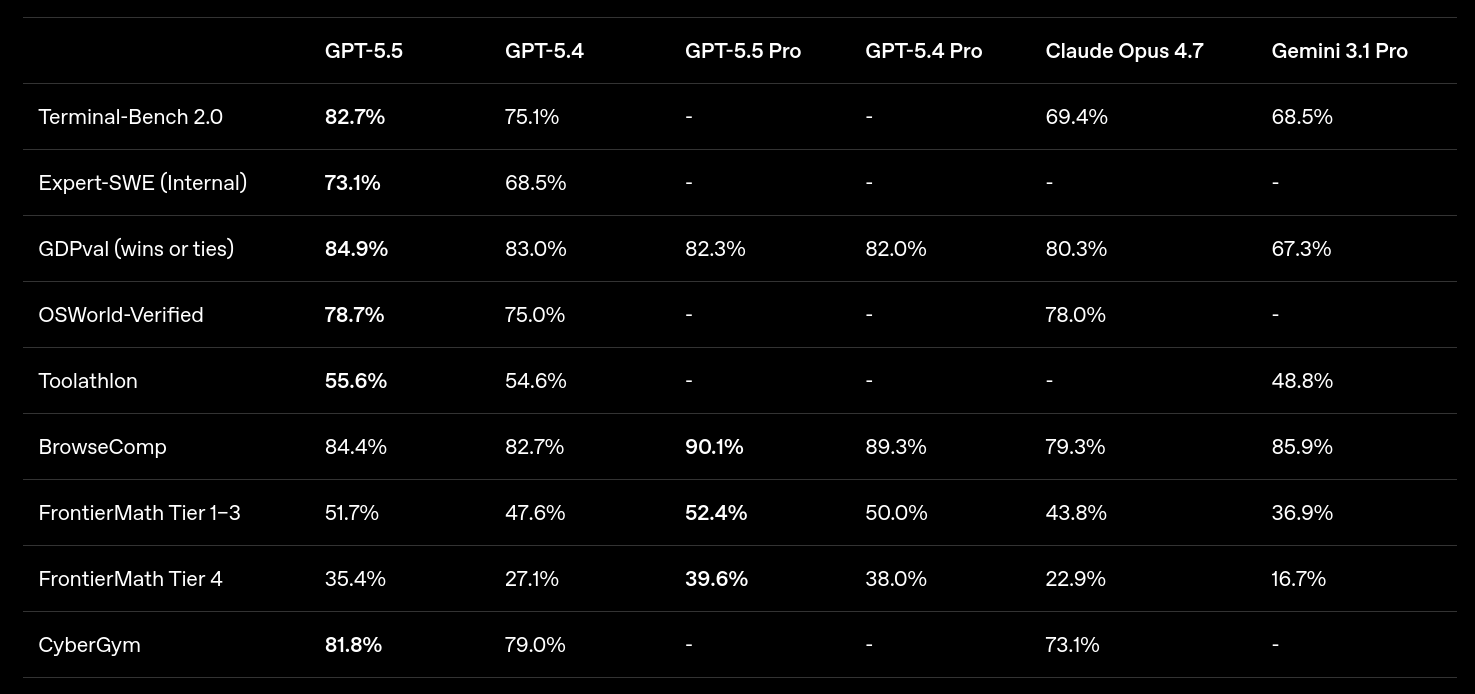
OpenAI ha presentado GPT‑5.5 (23 abril) como su modelo más fuerte para workflows de ingeniería largos: planificación, iteración, coordinación con herramientas y validación. En benchmarks que intentan aproximar trabajo real, reporta 82,7% en Terminal-Bench 2.0 y 58,6% en SWE-Bench Pro, con mejoras frente a GPT‑5.4.
La parte más relevante para agentes no es solo el score, sino el framing: OpenAI insiste en que GPT‑5.5 alcanza mejores resultados usando menos tokens, y lo despliega primero en ChatGPT y Codex (con llegada “muy pronto” a API). El mensaje implícito es que la siguiente frontera no es únicamente “más contexto”, sino más rendimiento por token cuando el modelo tiene que actuar durante muchos turnos.
Fuente: [clic aquí]
ChatGPT introduce workspace agents: agentes compartidos con permisos, memoria y ejecución en cloud
OpenAI ha anunciado workspace agents en ChatGPT (22 abril) como una evolución de los GPTs orientada al trabajo en equipo: agentes que se pueden crear, compartir y operar dentro de una organización, y que pueden ejecutar pasos multi-turn “en la nube” incluso cuando el usuario no está. La propuesta incluye interacción en ChatGPT y Slack (con más superficies prometidas), y un flujo guiado para convertir un proceso repetible (reporting, triage, ventas, riesgo, etc.) en un agente.
En gobernanza, el post enfatiza controles típicos de enterprise: permisos, aprobaciones para acciones sensibles, analítica de uso y visibilidad vía Compliance API. Está disponible en research preview para planes Business, Enterprise, Edu y Teachers, con gratuidad hasta 6 de mayo de 2026 y pricing por créditos a partir de esa fecha.
Fuente: [clic aquí]

OpenAI hace ChatGPT mejor para clínicos y publica HealthBench Professional
OpenAI ha publicado “Making ChatGPT better for clinicians” (22 abril), presentando ChatGPT for Clinicians como una versión diseñada con y para profesionales de salud: búsqueda clínica con citas en tiempo real desde fuentes médicas revisadas por pares, “deep research” para revisiones de literatura, y skills para flujos repetibles (derivaciones, prior auth, instrucciones a pacientes). También menciona opciones de seguridad/privacidad (por ejemplo, soporte HIPAA vía BAA para cuentas elegibles) y acceso gratuito para clínicos verificados en EE. UU.
En paralelo, introduce HealthBench Professional, un benchmark abierto de tareas reales de chat clínico (consult, writing/documentation, research) con conversaciones y rúbricas escritas y adjudicadas por médicos, incluyendo ejemplos de red teaming. El dataset está publicado en Hugging Face y añade campos comoconversation,rubric_items,use_case,specialtyyphysician_response(además de una nota pidiendo no compartir ejemplos para evitar contaminación).
Fuente: [clic aquí] [dataset]

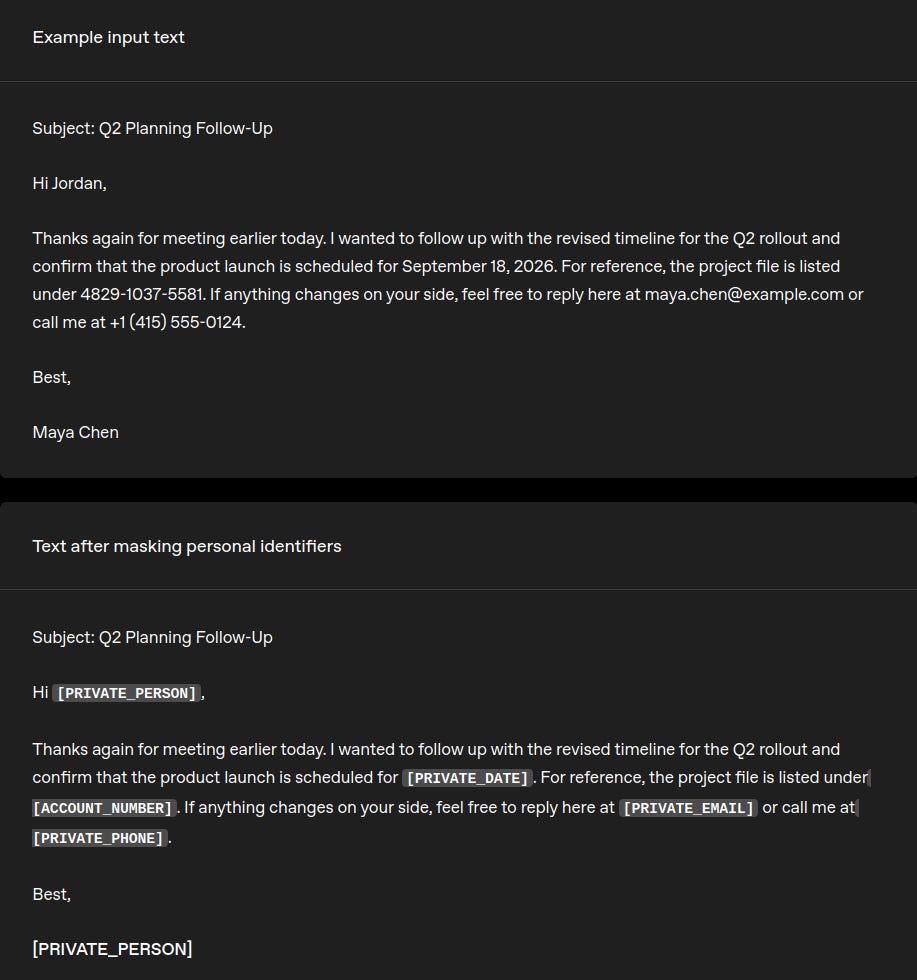
OpenAI publica Privacy Filter: un modelo open-weight para detectar y redactar PII
OpenAI ha liberado OpenAI Privacy Filter (22 abril), un modelo open-weight para detección y redacción de información personal (PII) en texto. En vez de reglas deterministas (emails, teléfonos), el enfoque es context-aware: un token-classifier bidireccional con decodificación de spans y una taxonomía explícita de etiquetas (por ejemplo
private_email,private_phone,secret).
El punto práctico es el deployment: el modelo es lo bastante pequeño como para correr localmente, soporta hasta 128k tokens de contexto y se publica bajo Apache 2.0 en Hugging Face y GitHub, pensado para integrarse en pipelines de training, indexing, logging y revisión con posibilidad de fine-tuning.
Fuente: [clic aquí]
OpenAI lanza ChatGPT Images 2.0
OpenAI ha lanzado ChatGPT Images 2.0 (21 abril), una actualización de producto centrada en una nueva generación de imágenes dentro de ChatGPT, con mejoras en control, tipografía y estilos. Es una señal más de que la suite “ChatGPT” sigue integrando capacidades creativas como parte del flujo general de trabajo (no como una herramienta separada).
Fuente: [clic aquí]
GitHub
Copilot en VS Code ya permite BYOK (bring your own key) para usar modelos externos y locales en Chat
GitHub ha activado BYOK en VS Code para usuarios de Copilot Business y Enterprise (22 abril): organizaciones pueden reutilizar sus API keys para acceder a modelos de proveedores como Anthropic, Gemini, OpenAI, OpenRouter y Azure, además de modelos locales vía Ollama y Foundry Local.
Una vez configurado, el modelo aparece en VS Code Chat (incluyendo el plan agent y agentes custom). Importante: BYOK no aplica a code completions, y el uso se factura directamente por el proveedor y no cuenta contra las cuotas de solicitudes de Copilot.
Fuente: [clic aquí]
GitHub añade visibilidad y control de agent sessions desde Issues y Projects
GitHub permite ahora ver y dirigir agent sessions directamente desde el workflow (23 abril). En issues aparece un “session pill” en la cabecera para ver sesiones activas y completadas, y un panel lateral para abrir una sesión, revisar progreso/logs y “steer” (dar guía) sin salir del issue.
En Projects, la opción “Show agent sessions” queda habilitada por defecto (en views nuevas y existentes) y se puede abrir la sesión en el sidebar desde el board. Es un cambio pequeño, pero apunta a una idea clave: si los agentes van a correr en background, el producto necesita una superficie de observabilidad y control integrada en la gestión diaria.
Fuente: [clic aquí]
GitHub ajusta Copilot para individuos: pausa de nuevos signups y límites más estrictos
GitHub anuncia cambios en planes individuales (20 abril) para priorizar calidad de servicio: pausa de nuevos registros para Student, Pro y Pro+ (Copilot Free sigue abierto), y límites de uso más estrictos con avisos en VS Code y Copilot CLI a medida que el usuario se acerca al límite.
También actualiza el “mix” de modelos: los Opus dejan de estar disponibles en Copilot Pro, mientras Opus 4.7 permanece en Pro+. Incluye opción de cancelación y reembolso (según condiciones) para usuarios a los que estos cambios no les encajen.
Fuente: [clic aquí]
Anthropic
Anthropic y NEC colaboran para desplegar Claude y construir una gran fuerza de ingeniería AI-native en Japón
Anthropic y NEC anuncian una colaboración (24 abril) en la que Claude se despliega a ~30.000 empleados del grupo NEC a nivel global y NEC se convierte en el primer global partner de Anthropic en Japón. El acuerdo incluye co-desarrollo de productos seguros y específicos de dominio para sectores como finanzas, manufactura y ciberseguridad.
En producto y operación, Anthropic destaca el uso de Claude (incluido Claude Opus 4.7) y Claude Code dentro de NEC BluStellar Scenario, además de integración en servicios de Security Operations Center. El subtexto aquí es claro: la adopción enterprise de agentes se está moviendo hacia capacitación interna + integración en suites existentes, no solo “pilotos aislados”.
Fuente: [clic aquí]
DeepSeek
DeepSeek estrena DeepSeek‑V4 en una colección oficial de Hugging Face
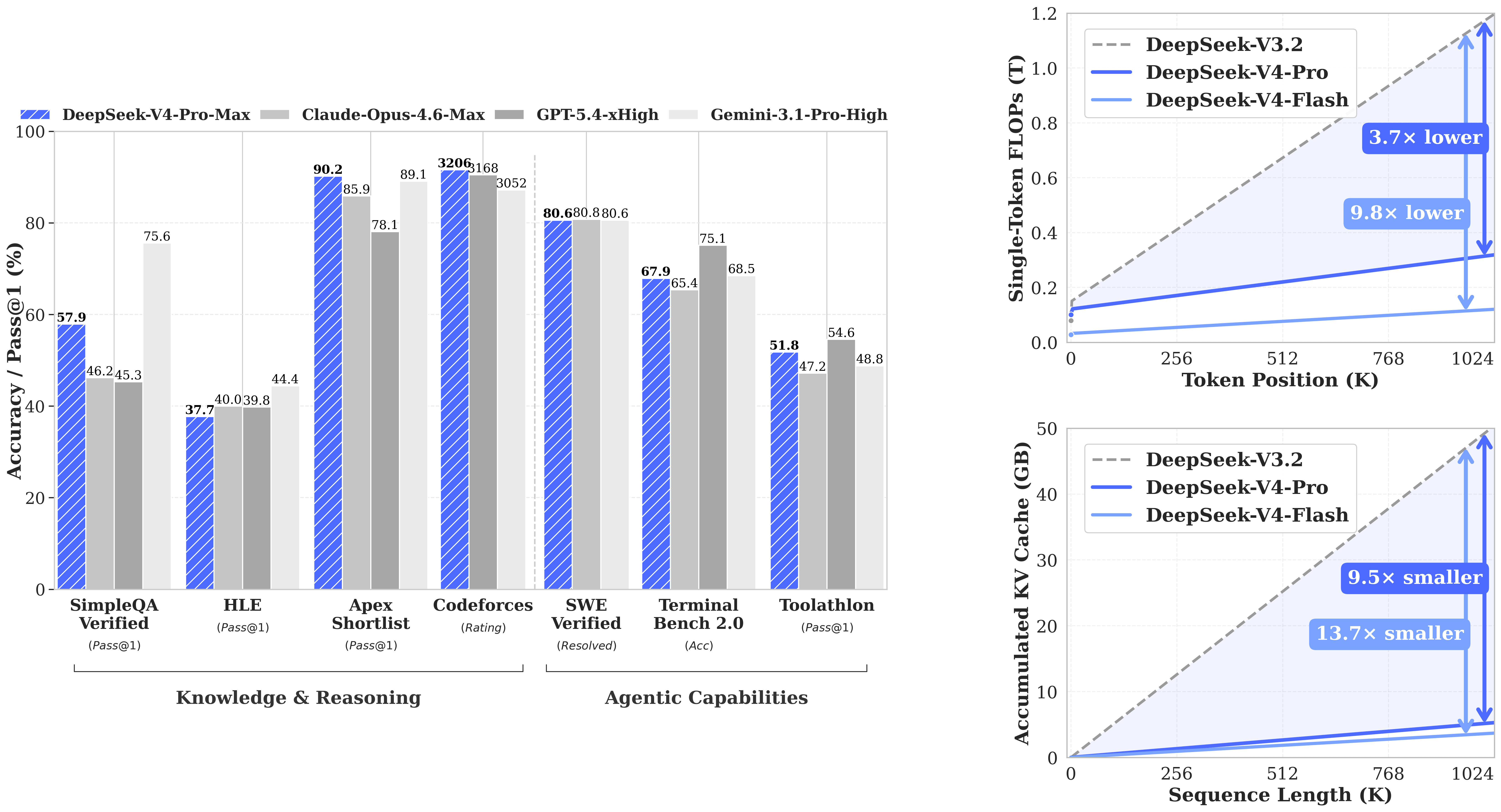
DeepSeek ha publicado/actualizado la colección DeepSeek‑V4 en Hugging Face, centralizando los checkpoints y variantes del release en una sola página. La colección lista modelos como DeepSeek‑V4‑Flash / Flash‑Base y DeepSeek‑V4‑Pro / Pro‑Base, con tamaños que van de ~158B a ~862B parámetros (y una variante base marcada en 1.6T en el listado).
DeepSeek-V4-Pro destaca como el modelo insignia de esta generación, con una arquitectura Mixture-of-Experts (MoE) de 1.6 billones (1.6T) de parámetros totales y 49B activos por token. Esta versión introduce innovaciones críticas como la atención híbrida (combinando CSA y HCA), que permite gestionar una ventana de contexto de 1 millón de tokens con una eficiencia sin precedentes: en contextos largos, requiere solo el 10% del KV cache y el 27% de los FLOPs en comparación con DeepSeek-V3.2. Además, el uso del optimizador Muon y conexiones mHC refuerza su estabilidad en razonamiento complejo, posicionándolo como un competidor directo de los modelos propietarios en tareas agénticas, de programación y matemáticas.
Fuente: [clic aquí]
Meta
Meta libera Sapiens 2: modelos fundacionales de alta resolución para tareas humanas
Meta ha presentado Sapiens 2 (24 abril), una familia de modelos Vision Transformer (ViT) de alta resolución (hasta 4K) diseñados para tareas centradas en humanos: estimación de pose, segmentación de partes del cuerpo y estimación de normales de superficie. Los modelos escalan de 0.4B a 5B de parámetros y han sido pre-entrenados con 1.000 millones de imágenes humanas.
La novedad principal frente a la primera versión es el uso de un paradigma híbrido que combina Masked Auto-Encoding (MAE) con aprendizaje contrastivo semántico, mejorando tanto el detalle fino como la comprensión semántica global.
Fuente: [GitHub] [Hugging Face] [Paper]

Desde la Investigación (arXiv, benchmarks y seguridad)
WildDet3D: Scaling Promptable 3D Detection in the Wild (2026-04-24).
Allen Institute for AI (Ai2) presenta WildDet3D, un detector 3D monocular de vocabulario abierto que permite detectar objetos a partir de una única imagen RGB mediante prompts (texto, clics o cajas 2D). El proyecto incluye WildDet3D-Data, un dataset masivo con más de 1 millón de imágenes y 3.7 millones de anotaciones 3D en 13.000 categorías.Fuente: [arXiv] [Hugging Face]

Descripción general de WildDet3D. A partir de una única imagen RGB y un mapa de profundidad opcional, WildDet3D realiza la detección monocular de objetos 3D con vocabulario abierto, aceptando modalidades de entrada flexibles (consultas de texto, clics en puntos 2D o cuadros delimitadores 2D) y prediciendo cuadros delimitadores 3D completos para los objetos especificados. OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation (2026-04-24).
Xiaomi Embodied Intelligence propone OneVL, un modelo de visión-lenguaje unificado para tareas robóticas que integra razonamiento latente y planificación en un solo paso. El modelo destaca por su capacidad de generar explicaciones en lenguaje natural sobre sus decisiones de planificación, mejorando la interpretabilidad en entornos de robótica autónoma.Fuente: [arXiv] [Proyecto]

Arquitectura de OneVL StructMem: Structured Memory for Long-Horizon Behavior in LLMs (2026-04-23).
Propone StructMem, una memoria jerárquica “enriquecida con estructura” que intenta capturar relaciones entre eventos (no solo hechos aislados) para mejorar razonamiento temporal y multi-hop en agentes conversacionales. Reporta mejoras en LoCoMo y, a la vez, reducción de tokens, llamadas a API y runtime frente a sistemas de memoria previos; el paper indica además aceptación en ACL 2026 (main).Fuente: [clic aquí]
Tool Attention Is All You Need: Dynamic Tool Gating and Lazy Schema Loading… (2026-04-23).
Ataca el problema práctico del “MCP/Tools tax” (inyección eager de esquemas) con un middleware que hace tool gating + lazy schema loading: mantiene resúmenes compactos en contexto y solo promueve el JSON schema completo para herramientas top‑k relevantes. En una simulación calibrada (120 tools / 6 servers), reporta reducción de tokens de herramientas del 95% (47,3k → 2,4k); los autores remarcan que métricas end‑to‑end se dan como proyecciones, no medidas en agentes “en vivo”.Fuente: [clic aquí]
Transient Turn Injection: Exposing Stateless Multi-Turn Vulnerabilities in LLMs (2026-04-23).
Introduce TTI, un ataque multi-turn que explota moderación stateless distribuyendo la intención adversaria en interacciones aisladas. Evalúa modelos comerciales y open-source y propone mitigaciones como agregación de contexto a nivel sesión y testing adversarial continuo; útil como recordatorio de que “seguridad por turno” no es suficiente cuando el agente opera por episodios largos.Fuente: [clic aquí]
MCP Pitfall Lab: Exposing Developer Pitfalls in MCP Tool Server Security… (2026-04-23).
Presenta un framework de testing para servidores MCP que convierte pitfalls de desarrollo en escenarios reproducibles y valida resultados con trazas MCP (en vez de autoinforme del agente). En su setup, aplicar hardening recomendado elimina findings Tier‑1 (29 → 0) con un coste medio bajo en LOC, y muestra divergencias entre narrativa del agente y evidencia de traza, reforzando la necesidad de auditoría basada en ejecución real.Fuente: [clic aquí]
CI-Work: Benchmarking Contextual Integrity in Enterprise LLM Agents (2026-04-23).
Propone un benchmark de “Contextual Integrity” para agentes enterprise en escenarios de retrieval denso: medir si el agente transmite lo esencial sin filtrar contexto sensible. Encuentra fallos de privacidad frecuentes (violaciones 15,8%–50,9%) y un trade-off incómodo: más utilidad suele correlacionar con más violación, sugiriendo que la solución pasa menos por “escalar el modelo” y más por arquitecturas context-centric.Fuente: [clic aquí]
An Alternate Agentic AI Architecture (It’s About the Data) (2026-04-23).
Critica la narrativa dominante de orquestación opaca con LLMs y propone RUBICON, una arquitectura data-centric con un álgebra explícita AQL (Find/From/Where) ejecutada por wrappers por fuente que imponen control de acceso, alineación de esquema y normalización. La tesis: en enterprise el cuello de botella suele ser integración y gobernanza de datos, y la “agenticidad” debería producir planes auditables, no cadenas invisibles de prompts.Fuente: [clic aquí]


Modelos de IA Interesantes
Nucleus-Image (MoE diffusion, open-weight, Apache 2.0).
Modelo text-to-image basado en un diffusion transformer sparse MoE: ~17B parámetros totales con ~2B activos por forward pass (64 expertos ruteados por capa), buscando empujar la frontera calidad/eficiencia. Lo interesante para builders es que viene como base model (sin DPO/RLHF) y se integra condiffusers, incluyendo text KV caching para acelerar los pasos de denoising.Fuente: [clic aquí]
LingBot-Map (streaming 3D reconstruction, Apache 2.0).
Un modelo fundacional feed-forward para reconstrucción 3D en streaming con un “Geometric Context Transformer” que combina anclajes, ventana pose-reference y memoria de trayectoria para corregir drift en secuencias largas. Reporta inferencia estable a ~20 FPS (518×378) en secuencias de >10.000 frames, apuntando a pipelines donde la latencia y la estabilidad importan más que la optimización iterativa offline.Fuente: [clic aquí]
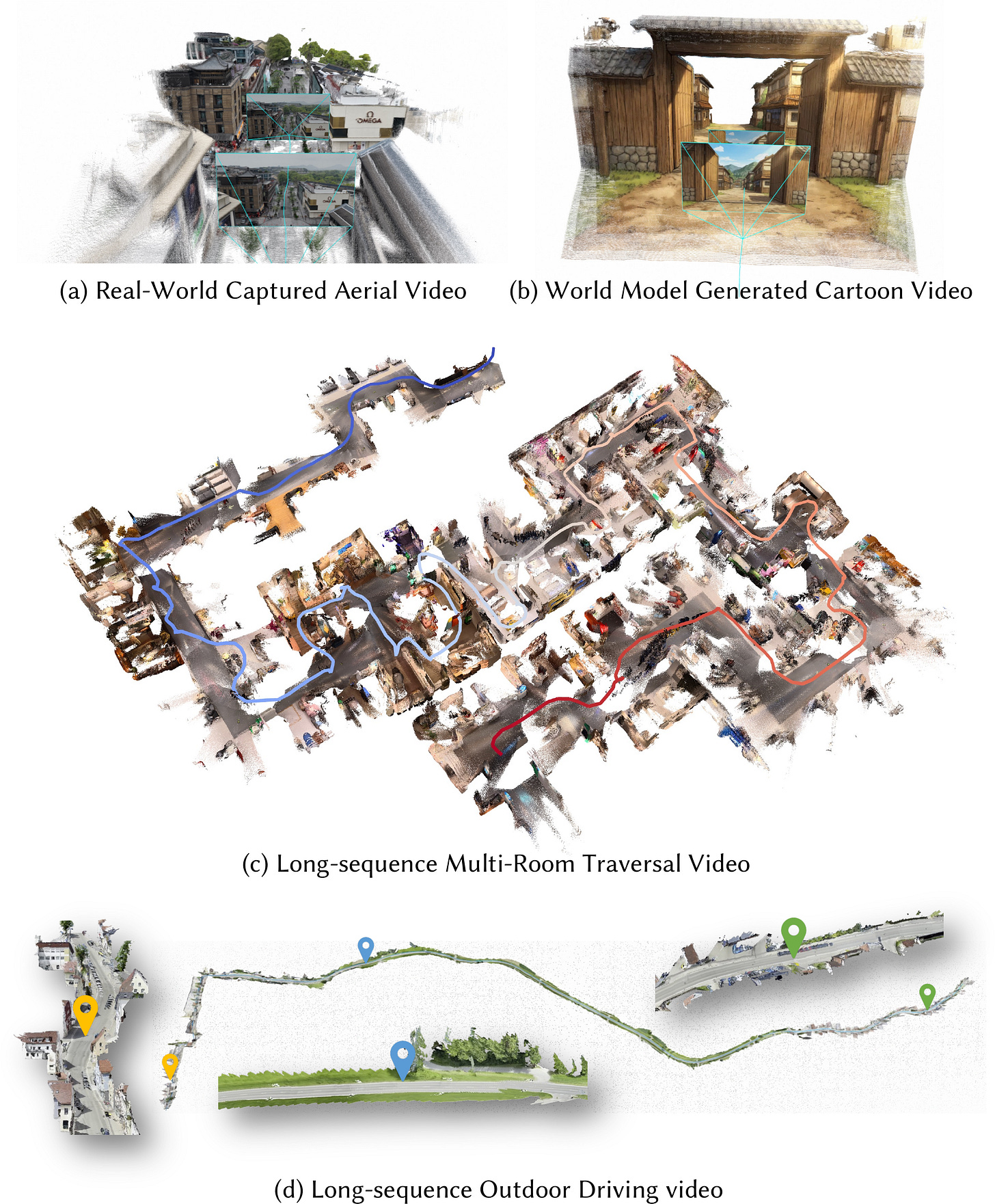
Ejemplos obtenidos de Lingbot-Map sobre diferentes escenarios Kimi-K2.6 (multimodal agentic MoE, licencia Modified MIT).
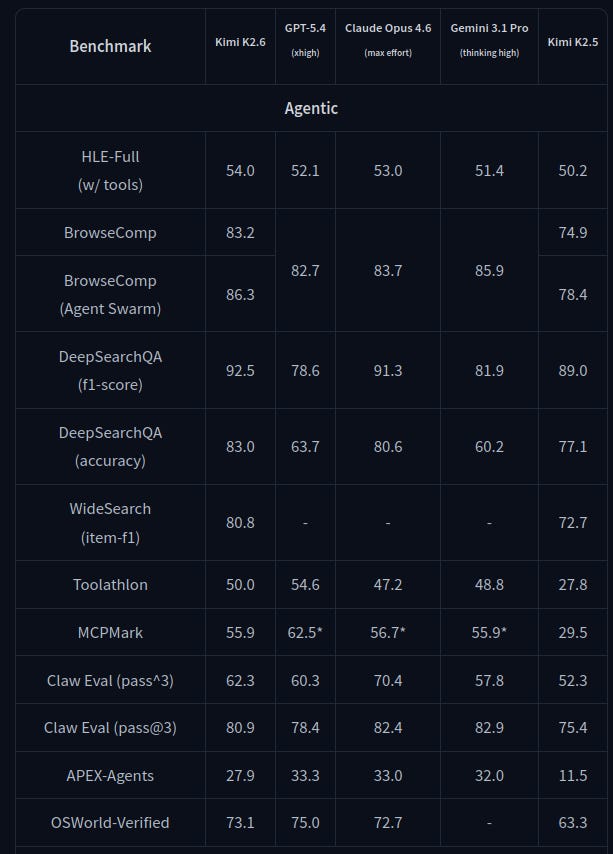
Modelo open-source multimodal y orientado a agentes: arquitectura MoE con 1T parámetros totales y 32B activados, y 256K de contexto. El card enfatiza “long-horizon coding”, diseño guiado por coding y orquestación tipo agent swarm (hasta 300 sub-agentes), lo que lo hace un candidato natural para experimentar con tareas largas y paralelizables.Fuente: [clic aquí]
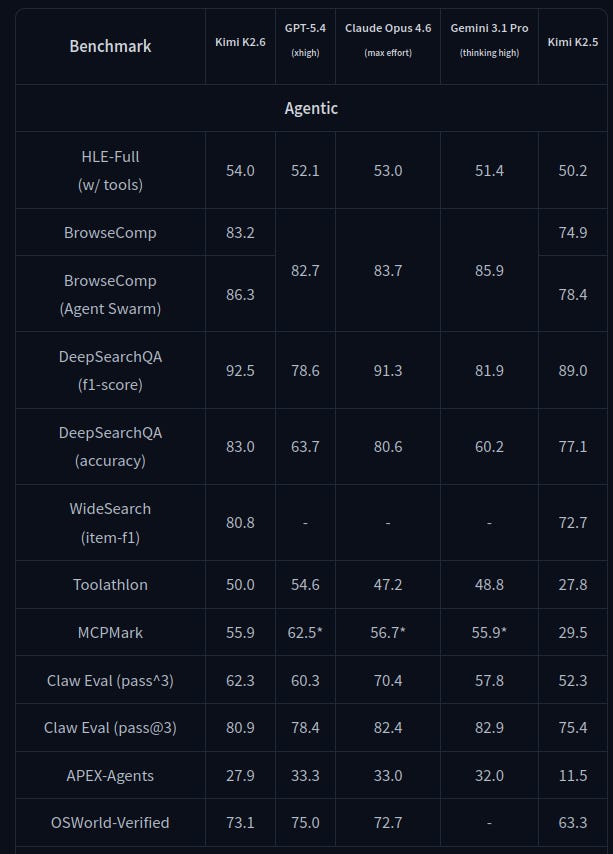
Comparativa del nuevo Kimi-K2.6 en capacidades agénticas frente a modelos cloud frontier similares
Utilidades para builders
pdf-inspector (Firecrawl).
Librería (Rust) + bindings para Python/Node para clasificar PDFs (text-based vs scanned/mixed), extraer texto con coordenadas y convertir a Markdown limpio sin OCR. Lo más útil en pipelines de agentes es que devuelvepages_needing_ocr, lo que permite enrutar OCR por página y evitar OCR caro en PDFs que ya traen texto embebido.Fuente: [clic aquí]
DFNDR‑12M‑bf16 (Apple): dataset reforzado para entrenamiento eficiente de imagen‑texto.
Un dataset imagen‑texto reforzado que construye sobre DFN (DFN-2B/DFN-12M) y añade captions sintéticos + embeddings (bfloat16) orientados a mejorar eficiencia de aprendizaje en CLIP-like training. Útil como referencia para builders que quieran explorar reinforcement-style data curation o entrenar/afinar modelos multimodales compactos con mejor relación coste‑calidad.Fuente: [clic aquí]
mlinter (Transformers).
Hugging Face publicamlinter, un linter específico para archivosmodeling_*.py,modular_*.pyyconfiguration_*.pyde Transformers que opera sobre AST (sin imports runtime) y codifica reglas estructurales TRF### con explicación y diff de fix. El diseño es explícitamente “agent-friendly”: IDs estables,--changed-only, anotaciones de GitHub y documentación por regla pensada para que agentes (y humanos) corrijan convenciones en el mismo loop de edición.Fuente: [clic aquí]
C++ Language Server para GitHub Copilot CLI (preview).
GitHub anuncia un Language Server de C++ (npm package) para que Copilot CLI pueda usar información semántica (símbolos, referencias, tipos) en lugar de depender solo de búsquedas tipo grep. Para repos grandes con macros/templates/build configs, esto suele ser la diferencia entre “respuesta plausible” y “respuesta accionable”.Fuente: [clic aquí]
Algunas Noticias Breves de IA
Copilot Chat mejora su comprensión y “review mode” en pull requests. Ahora, cuando un PR se da como contexto, Copilot Chat incorpora comentarios, cambios de archivos, commits y reviews, y puede dar summary/review estructurados.
Fuente: [clic aquí]
Copilot en la web estructura mejor el debugging a partir de stack traces. Las respuestas pasan a incluir “qué falló y dónde”, “por qué”, root cause probable, evidencia con referencias a código, nivel de confianza y checks siguientes.
Fuente: [clic aquí]
GitHub pausa nuevos self-serve signups de Copilot Business para orgs en Free/Team. Clientes existentes no se ven afectados y pueden seguir añadiendo seats y usando el servicio.
Fuente: [clic aquí]
“Desastre” de Claude Code (según reportes): Anthropic habría retirado temporalmente Claude Code del plan Pro para una parte de nuevos usuarios; la compañía lo atribuyó a una prueba que afectó a ~2% de altas nuevas y admitió mala comunicación. Se considera que recogieron cable tras críticas de usuarios habituales.
Fuente: [clic aquí]

Mercadona reconstruye su buscador con Claude Code y recorta costes: Mercadona Tech cuenta que sustituyeron Algolia por un buscador propio construido en alrededor de un mes apoyándose en Claude Code, con ahorros reportados cercanos al 90%.
Fuente: [clic aquí]
